將 fairseq wmt19 翻譯系統移植到 transformers


Stas Bekman 的客座博文
本文旨在記錄如何將fairseq wmt19 翻譯系統移植到
transformers。
我正在尋找一些有趣的專案來做,Sam Shleifer 建議我嘗試移植一個高質量的翻譯器。
我閱讀了這篇簡短的論文:Facebook FAIR 的 WMT19 新聞翻譯任務提交,該論文描述了原始系統,並決定嘗試一下。
最初,我不知道如何著手這個複雜的專案,Sam 幫助我將其分解成更小的任務,這非常有幫助。
在移植過程中,我選擇使用預訓練的 `en-ru`/`ru-en` 模型,因為我懂這兩種語言。使用 `de-en`/`en-de` 對會困難得多,因為我不懂德語,而在移植過程的高階階段能夠透過閱讀和理解輸出來評估翻譯質量為我節省了大量時間。
此外,由於我最初使用 `en-ru`/`ru-en` 模型進行移植,我完全不知道 `de-en`/`en-de` 模型使用了合併詞彙表,而前者使用了兩個不同大小的獨立詞彙表。因此,一旦我完成了支援兩個獨立詞彙表的更復雜的工作,使合併詞彙表工作就變得微不足道了。
讓我們作弊
第一步當然是作弊。既然可以花小力氣,為什麼要花大力氣呢?所以我寫了一個簡短的筆記本,它通過幾行程式碼提供了一個 fairseq 的代理,並模擬了 transformers API。
如果只需要基本的翻譯功能,這已經足夠了。但是,我們當然希望進行完整的移植,所以在取得這個小勝利之後,我著手處理更困難的事情。
準備工作
為了本文的方便,我們假設在 `~/porting` 目錄下工作,所以讓我們建立這個目錄
mkdir ~/porting
cd ~/porting
我們需要為這項工作安裝一些東西
# install fairseq
git clone https://github.com/pytorch/fairseq
cd fairseq
pip install -e .
# install mosesdecoder under fairseq
git clone https://github.com/moses-smt/mosesdecoder
# install fastBPE under fairseq
git clone git@github.com:glample/fastBPE.git
cd fastBPE; g++ -std=c++11 -pthread -O3 fastBPE/main.cc -IfastBPE -o fast; cd -
cd -
# install transformers
git clone https://github.com/huggingface/transformers/
pip install -e .[dev]
檔案
簡單概括一下,需要建立和編寫以下檔案
src/transformers/configuration_fsmt.py- 一個簡短的配置類。src/transformers/convert_fsmt_original_pytorch_checkpoint_to_pytorch.py- 一個複雜的轉換指令碼。src/transformers/modeling_fsmt.py- 這是模型架構的實現。src/transformers/tokenization_fsmt.py- 分詞器程式碼。tests/test_modeling_fsmt.py- 模型測試。tests/test_tokenization_fsmt.py- 分詞器測試。docs/source/model_doc/fsmt.rst- 一個文件檔案。
還有其他檔案也需要修改,我們將在文章末尾討論。
轉換
移植過程中最重要的部分之一是建立一個指令碼,該指令碼將獲取模型原始開發人員提供的所有可用源資料,其中包括一個包含預訓練權重、模型和訓練配置、字典和分詞器支援檔案的檢查點,並將其轉換為 transformers 支援的新模型檔案集。您將在此處找到最終的轉換指令碼:src/transformers/convert_fsmt_original_pytorch_checkpoint_to_pytorch.py
我透過複製現有的轉換指令碼 `src/transformers/convert_bart_original_pytorch_checkpoint_to_pytorch.py` 來開始這個過程,清除了大部分內容,然後隨著移植過程的進展逐漸添加了各個部分。
在開發過程中,我將所有程式碼都針對轉換後的模型檔案的本地副本進行測試,直到所有準備就緒,我才將檔案上傳到 🤗 s3,然後繼續針對線上版本進行測試。
fairseq 模型及其支援檔案
我們首先來看看 fairseq 預訓練模型中包含哪些資料。
我們將使用方便的 `torch.hub` API,這使得部署提交到該 hub 的模型變得非常容易
import torch
torch.hub.load('pytorch/fairseq', 'transformer.wmt19.en-ru', checkpoint_file='model4.pt',
tokenizer='moses', bpe='fastbpe')
此程式碼下載預訓練模型及其支援檔案。我在 pytorch hub 上與fairseq 對應的頁面上找到了此資訊。
要檢視下載檔案中的內容,我們首先必須在 `~/.cache` 下找到正確的資料夾。
ls -1 ~/.cache/torch/hub/pytorch_fairseq/
顯示
15bca559d0277eb5c17149cc7e808459c6e307e5dfbb296d0cf1cfe89bb665d7.ded47c1b3054e7b2d78c0b86297f36a170b7d2e7980d8c29003634eb58d973d9
15bca559d0277eb5c17149cc7e808459c6e307e5dfbb296d0cf1cfe89bb665d7.ded47c1b3054e7b2d78c0b86297f36a170b7d2e7980d8c29003634eb58d973d9.json
如果您曾將 `hub` 用於其他模型,那裡可能有一個以上的條目。
讓我們建立一個符號連結,以便將來可以輕鬆引用那個晦澀的快取資料夾名稱
ln -s /code/data/cache/torch/hub/pytorch_fairseq/15bca559d0277eb5c17149cc7e808459c6e307e5dfbb296d0cf1cfe89bb665d7.ded47c1b3054e7b2d78c0b86297f36a170b7d2e7980d8c29003634eb58d973d9 \
~/porting/pytorch_fairseq_model
注意:當您自己嘗試時,路徑可能會有所不同,因為模型的雜湊值可能會改變。您將在 `~/.cache/torch/hub/pytorch_fairseq/` 中找到正確的路徑。
如果我們檢視該資料夾內部
ls -l ~/porting/pytorch_fairseq_model/
total 13646584
-rw-rw-r-- 1 stas stas 532048 Sep 8 21:29 bpecodes
-rw-rw-r-- 1 stas stas 351706 Sep 8 21:29 dict.en.txt
-rw-rw-r-- 1 stas stas 515506 Sep 8 21:29 dict.ru.txt
-rw-rw-r-- 1 stas stas 3493170533 Sep 8 21:28 model1.pt
-rw-rw-r-- 1 stas stas 3493170532 Sep 8 21:28 model2.pt
-rw-rw-r-- 1 stas stas 3493170374 Sep 8 21:28 model3.pt
-rw-rw-r-- 1 stas stas 3493170386 Sep 8 21:29 model4.pt
我們有
model*.pt- 4 個檢查點(包含所有預訓練權重和各種其他內容的 PyTorch `state_dict`)dict.*.txt- 源詞典和目標詞典bpecodes- 分詞器使用的特殊對映檔案
我們將在以下部分中研究這些檔案。
翻譯系統的工作原理
這裡是對計算機如今如何翻譯文字的簡要介紹。
計算機無法閱讀文字,只能處理數字。因此,在處理文字時,我們必須將一個或多個字母對映成數字,然後將這些數字交給計算機程式。程式完成後,它也會返回數字,我們需要將其轉換回文字。
讓我們從俄語和英語的兩個句子開始,併為每個單詞分配一個唯一的數字
я люблю следовательно я существую
10 11 12 10 13
I love therefore I am
20 21 22 20 23
以 10 開頭的數字將俄語單詞對映到唯一的數字。以 20 開頭的數字對英語單詞做同樣的事情。如果您不懂俄語,您仍然可以看到單詞 `я`(意思是“我”)在句子中重複了兩次,並且它被分配了相同的數字 10。對於 `I`(20)也是如此,它也重複了兩次。
翻譯系統的工作階段如下
1. [я люблю следовательно я существую] # tokenize sentence into words
2. [10 11 12 10 13] # look up words in the input dictionary and convert to ids
3. [black box] # machine learning system magic
4. [20 21 22 20 23] # look up numbers in the output dictionary and convert to text
5. [I love therefore I am] # detokenize the tokens back into a sentence
如果我們將前兩個步驟和後兩個步驟合併,我們得到 3 個階段
- 編碼輸入:將輸入文字分解成標記,為這些標記建立一個字典(詞彙表),並將每個標記重新對映到該字典中的唯一 ID。
- 生成翻譯:獲取輸入數字,透過預訓練的機器學習模型執行它們,該模型預測最佳翻譯,並返回輸出數字。
- 解碼輸出:獲取輸出數字,在目標語言詞典中查詢它們,將它們轉換回文字,最後將轉換後的標記合併為翻譯後的句子。
第二階段可能會返回一個或幾個可能的翻譯。在後一種情況下,呼叫者可以選擇最合適的結果。在本文中,我將提及束搜尋演算法,這是搜尋多個可能結果的方法之一。束的大小指的是返回結果的數量。
如果只請求一個結果,模型將選擇機率最高的一個。如果請求多個結果,它將按機率排序返回這些結果。
請注意,同樣的想法適用於大多數自然語言處理任務,而不僅僅是翻譯。
分詞
早期的系統將句子分詞成單詞和標點符號。但是由於許多語言有數十萬個單詞,處理巨大的詞彙表非常耗費資源,因為它大大增加了計算資源需求和完成任務所需的時間。
截至 2020 年,有相當多不同的分詞方法,但大多數最新的方法都基於子詞分詞——也就是說,這些現代分詞器不是將輸入文字分解成單詞,而是將其分解成單詞片段和字母,使用某種訓練來獲得最優的分詞。
讓我們看看這種方法如何幫助減少記憶體和計算需求。如果我們有一個包含 6 個常用詞的輸入詞彙表:go、going、speak、speaking、sleep、sleeping - 使用詞級分詞,我們最終得到 6 個標記。但是,如果我們將其分解為:go、go-ing、speak、speak-ing 等,那麼我們的詞彙表中只有 4 個標記:go、speak、sleep、ing。這個簡單的改變帶來了 33% 的改進!除了,子詞分詞器不使用語法規則,而是透過大量文字輸入進行訓練以找到這樣的拆分。在這個例子中,我使用了一個簡單的語法規則,因為它很容易理解。
這種方法的另一個重要優點是處理輸入文字中不在我們詞彙表中的單詞。例如,假設我們的系統遇到單詞 `grokking` (*),在它的詞彙表中找不到。如果我們把它分成 `grokk` - `ing`,那麼機器學習模型可能不知道如何處理單詞的前半部分,但它得到了一個有用的見解,即 `ing` 表示進行時態,因此它能夠生成更好的翻譯。在這種情況下,分詞器會將未知片段分成它知道的片段,在最壞的情況下,將其簡化為單個字母。
- 腳註:`grok` 一詞由羅伯特·A·海因萊因(Robert A. Heinlein)於 1961 年在其著作《異鄉異客》("Stranger in a Strange Land")中創造:憑直覺或透過同理心理解(某事)。
關於為什麼現代分詞方法比簡單的單詞分詞更優越,還有許多其他細微之處,本文將不予贅述。與剛剛演示的簡單的“ing”結尾拆分示例相比,這些系統中的大多數在分詞方式上都非常複雜,但原理是相似的。
分詞器移植
第一步是移植分詞器的編碼器部分,將文字轉換為 ID。解碼器部分直到最後才需要。
fairseq 的分詞器工作原理
讓我們瞭解 `fairseq` 的分詞器是如何工作的。
fairseq (*) 使用位元組對編碼(BPE)演算法進行分詞。
- 腳註:從現在開始,當我提到 `fairseq` 時,我指的是此特定模型實現 - `fairseq` 專案本身有數十種不同模型的不同實現。
讓我們看看 BPE 是如何工作的
import torch
sentence = "Machine Learning is great"
checkpoint_file='model4.pt'
model = torch.hub.load('pytorch/fairseq', 'transformer.wmt19.en-ru', checkpoint_file=checkpoint_file, tokenizer='moses', bpe='fastbpe')
# encode step by step
tokens = model.tokenize(sentence)
print("tokenize ", tokens)
bpe = model.apply_bpe(tokens)
print("apply_bpe: ", bpe)
bin = model.binarize(bpe)
print("binarize: ", len(bin), bin)
# compare to model.encode - should give us the same output
expected = model.encode(sentence)
print("encode: ", len(expected), expected)
給我們
('tokenize ', 'Machine Learning is great')
('apply_bpe: ', 'Mach@@ ine Lear@@ ning is great')
('binarize: ', 7, tensor([10217, 1419, 3, 2515, 21, 1054, 2]))
('encode: ', 7, tensor([10217, 1419, 3, 2515, 21, 1054, 2]))
您可以看到 `model.encode` 執行 `tokenize+apply_bpe+binarize` - 因為我們得到相同的輸出。
步驟是
tokenize:通常它會轉義撇號並進行其他預處理,在這個例子中它只是返回了未經任何更改的輸入句子apply_bpe:BPE 根據分詞器提供的 `bpecodes` 檔案將輸入文字分割成單詞和子詞——我們得到 6 個 BPE 塊binarize:這只是將前一步的 BPE 塊重新對映到詞彙表(也隨模型下載)中對應的 ID
您可以參考此筆記本以檢視更多詳細資訊。
現在是檢視 `bpecodes` 檔案內容的好時機。以下是檔案的開頭部分
$ head -15 ~/porting/pytorch_fairseq_model/bpecodes
e n</w> 1423551864
e r 1300703664
e r</w> 1142368899
i n 1130674201
c h 933581741
a n 845658658
t h 811639783
e n 780050874
u n 661783167
s t 592856434
e i 579569900
a r 494774817
a l 444331573
o r 439176406
th e</w> 432025210
[...]
此檔案的頂部條目包含非常頻繁的短單字母序列。正如我們稍後將看到的,底部包含最常見的多字母子詞,甚至是完整的長單詞。
特殊標記 `</w>` 表示單詞的結尾。因此,在上面引用的幾行中,我們發現
e n</w> 1423551864
e r</w> 1142368899
th e</w> 432025210
如果第二列不包含 `</w>`,則表示此段落在單詞中間而不是結尾處。
最後一列聲明瞭此 BPE 程式碼在訓練期間遇到的次數。`bpecodes` 檔案按此列排序——因此最常見的 BPE 程式碼位於頂部。
透過檢視計數,我們現在知道,當此分詞器進行訓練時,它遇到了 1,423,551,864 個以 `en` 結尾的單詞,1,142,368,899 個以 `er` 結尾的單詞,以及 432,025,210 個以 `the` 結尾的單詞。對於後者,它很可能指的是實際的單詞 `the`,但也可能包括 `lathe`、`loathe`、`tithe` 等單詞。
這些巨大的數字也向我們表明,這個分詞器是在大量的文字上訓練出來的!
如果我們檢視同一檔案的底部
$ tail -10 ~/porting/pytorch_fairseq_model/bpecodes
4 x 109019
F ische</w> 109018
sal aries</w> 109012
e kt 108978
ver gewal 108978
Sten cils</w> 108977
Freiwilli ge</w> 108969
doub les</w> 108965
po ckets</w> 108953
Gö tz</w> 108943
我們看到複雜的子詞組合仍然非常常見,例如 `salaries` 出現了 109,012 次!所以它在 `bpecodes` 對映檔案中擁有自己的專用條目。
apply_bpe 是如何工作的?它透過在 `bpecodes` 對映檔案中查詢各種字母組合,並在找到最長的匹配條目時使用它。
回到我們的例子,我們看到它將 `Machine` 分割成:`Mach@@` + `ine` - 讓我們檢查一下
$ grep -i ^mach ~/porting/pytorch_fairseq_model/bpecodes
mach ine</w> 463985
Mach t 376252
Mach ines</w> 374223
mach ines</w> 214050
Mach th 119438
您可以看到它包含 `mach ine</w>`。我們沒有看到 `Mach ine` 在其中 - 所以它必須在正常大小寫不匹配時處理小寫查詢。
現在檢查一下:`Lear@@` + `ning`
$ grep -i ^lear ~/porting/pytorch_fairseq_model/bpecodes
lear n</w> 675290
lear ned</w> 505087
lear ning</w> 417623
我們發現 `learning</w>` 在那裡(同樣,大小寫不一致)。
仔細想想,大小寫對於分詞可能並不重要,只要字典中存在 `Mach` / `Lear` 和 `mach` / `lear` 的唯一條目,其中涵蓋每種大小寫至關重要。
希望您現在能明白這是如何運作的。
一個令人困惑的地方是,如果您還記得 `apply_bpe` 的輸出是
('apply_bpe: ', 6, ['Mach@@', 'ine', 'Lear@@', 'ning', 'is', 'great'])
它不是用 `</w>` 標記單詞的結尾,而是保留原樣,而是用 `@@` 標記不是結尾的單詞。這可能是因為 `fairseq` 使用了 `fastBPE` 實現,所以它就是這樣做的。我不得不改變它以適應 `transformers` 的實現,後者不使用 `fastBPE`。
最後要檢查的是 BPE 程式碼到詞彙表 ID 的重新對映。重複一下,我們有
('apply_bpe: ', 'Mach@@ ine Lear@@ ning is great')
('binarize: ', 7, tensor([10217, 1419, 3, 2515, 21, 1054, 2]))
2 - 最後一個標記 ID 是一個 `eos`(流結束)標記。它用於向模型指示輸入的結束。
然後 `Mach@@` 被重新對映到 `10217`,`ine` 被重新對映到 `1419`。
讓我們檢查一下字典檔案是否一致
$ grep ^Mach@@ ~/porting/pytorch_fairseq_model/dict.en.txt
Mach@@ 6410
$ grep "^ine " ~/porting/pytorch_fairseq_model/dict.en.txt
ine 88376
等等——這些不是我們 `binarize` 之後得到的 ID,它們應該是 `10217` 和 `1419`。
經過一番調查,我發現詞彙表文件 ID 並非模型使用的 ID,並且在載入詞彙表文件後,它們在內部被重新對映到新的 ID。幸運的是,我不需要弄清楚它是如何精確完成的。相反,我只是使用了 `fairseq.data.dictionary.Dictionary.load` 來載入字典 (*),它執行了所有重新對映,——然後我儲存了最終的字典。我是透過使用偵錯程式逐步除錯 `fairseq` 程式碼來發現這個 `Dictionary` 類的。
- 腳註:我越是致力於移植模型和資料集,我就越意識到讓原始程式碼為我所用,而不是嘗試複製它,可以節省大量時間,最重要的是,這些程式碼已經經過測試——太容易遺漏一些東西,並在之後發現大問題!畢竟,最終,所有這些轉換程式碼都不重要,因為只有它生成的資料將被 `transformers` 及其終端使用者使用。
這是轉換指令碼的相關部分
from fairseq.data.dictionary import Dictionary
def rewrite_dict_keys(d):
# (1) remove word breaking symbol
# (2) add word ending symbol where the word is not broken up,
# e.g.: d = {'le@@': 5, 'tt@@': 6, 'er': 7} => {'le': 5, 'tt': 6, 'er</w>': 7}
d2 = dict((re.sub(r"@@$", "", k), v) if k.endswith("@@") else (re.sub(r"$", "</w>", k), v) for k, v in d.items())
keep_keys = "<s> <pad> </s> <unk>".split()
# restore the special tokens
for k in keep_keys:
del d2[f"{k}</w>"]
d2[k] = d[k] # restore
return d2
src_dict_file = os.path.join(fsmt_folder_path, f"dict.{src_lang}.txt")
src_dict = Dictionary.load(src_dict_file)
src_vocab = rewrite_dict_keys(src_dict.indices)
src_vocab_size = len(src_vocab)
src_vocab_file = os.path.join(pytorch_dump_folder_path, "vocab-src.json")
print(f"Generating {src_vocab_file}")
with open(src_vocab_file, "w", encoding="utf-8") as f:
f.write(json.dumps(src_vocab, ensure_ascii=False, indent=json_indent))
# we did the same for the target dict - omitted quoting it here
# and we also had to save `bpecodes`, it's called `merges.txt` in the transformers land
執行轉換指令碼後,讓我們檢查轉換後的字典
$ grep '"Mach"' /code/huggingface/transformers-fair-wmt/data/wmt19-en-ru/vocab-src.json
"Mach": 10217,
$ grep '"ine</w>":' /code/huggingface/transformers-fair-wmt/data/wmt19-en-ru/vocab-src.json
"ine</w>": 1419,
我們有 `transformers` 版本的詞彙表文件中的正確 ID。
如您所見,我還必須重寫詞彙表以匹配 `transformers` BPE 實現。我們必須更改
['Mach@@', 'ine', 'Lear@@', 'ning', 'is', 'great']
到
['Mach', 'ine</w>', 'Lear', 'ning</w>', 'is</w>', 'great</w>']
我們不是標記作為單詞片段的塊,除了最後一個片段,而是標記作為最終片段的片段或單詞。可以輕鬆地從一種編碼樣式轉換為另一種,然後轉換回來。
這成功完成了模型檔案第一部分的移植。您可以在此處檢視最終的程式碼版本。
如果您想深入瞭解,此筆記本中還有更多細節。
將分詞器的編碼器移植到 transformers
transformers 無法依賴fastBPE,因為後者需要 C 編譯器,但幸運的是,有人已經在tokenization_xlm.py中實現了相同的 Python 版本。
所以我只需將其複製到 `src/transformers/tokenization_fsmt.py` 並重命名類名
cp tokenization_xlm.py tokenization_fsmt.py
perl -pi -e 's|XLM|FSMT|ig; s|xlm|fsmt|g;' tokenization_fsmt.py
只需進行極少的更改,我就擁有了一個可用的分詞器編碼器部分。有很多程式碼不適用於我需要支援的語言,因此我刪除了那些程式碼。
由於我需要兩個不同的詞彙表,而不是一個,因此在分詞器和所有其他地方,我不得不修改程式碼以支援兩者。例如,我不得不重寫超類的方法
def get_vocab(self) -> Dict[str, int]:
return self.get_src_vocab()
@property
def vocab_size(self) -> int:
return self.src_vocab_size
由於 `fairseq` 未使用 `bos`(流開始)標記,我還必須更改程式碼以不包含這些標記 (*)
- return bos + token_ids_0 + sep
- return bos + token_ids_0 + sep + token_ids_1 + sep
+ return token_ids_0 + sep
+ return token_ids_0 + sep + token_ids_1 + sep
- 腳註:這是 `diff(1)` 的輸出,它顯示了兩個程式碼塊之間的差異——以 `-` 開頭的行表示已刪除的內容,以 `+` 開頭的行表示已新增的內容。
fairseq 還在跳脫字元並執行激進的破折號分割,所以我也必須改變
- [...].tokenize(text, return_str=False, escape=False)
+ [...].tokenize(text, return_str=False, escape=True, aggressive_dash_splits=True)
如果您正在跟隨,並想檢視我對原始 `tokenization_xlm.py` 所做的所有更改,您可以執行以下操作
cp tokenization_xlm.py tokenization_orig.py
perl -pi -e 's|XLM|FSMT|g; s|xlm|fsmt|g;' tokenization_orig.py
diff -u tokenization_orig.py tokenization_fsmt.py | less
只需確保您在 fsmt 釋出前後簽出儲存庫,因為這兩個檔案自那時以來可能已經有所不同。
最後階段是執行一系列輸入並確保移植後的分詞器產生與原始分詞器相同的 ID。您可以在此筆記本中看到這一點,我反覆執行該筆記本,試圖弄清楚如何使輸出匹配。
大部分移植過程都是這樣進行的:我選擇一個小功能,用 `fairseq` 方式執行它,獲取輸出;然後用 `transformers` 程式碼做同樣的事情,嘗試讓輸出匹配——反覆調整程式碼直到匹配,然後嘗試不同型別的輸入,確保它產生相同的輸出,以此類推,直到所有輸入都產生匹配的輸出。
移植核心翻譯功能
在分詞器移植取得相對較快的成功之後(顯然,這要歸功於大部分程式碼已經存在),下一個階段要複雜得多。這就是 `generate()` 函式,它接受輸入 ID,將其透過模型執行並返回輸出 ID。
我必須將其分解為多個子任務。我必須
- 移植模型權重。
- 使 `generate()` 在單個束(即只返回一個結果)下工作。
- 然後是多個束(即返回多個結果)。
我首先研究了哪些現有架構與我的需求最接近。BART 是最接近的,所以我繼續做了
cp modeling_bart.py modeling_fsmt.py
perl -pi -e 's|Bart|FSMT|ig; s|bart|fsmt|g;' modeling_fsmt.py
這是我的起點,我需要調整它以與 `fairseq` 提供的模型權重一起工作。
移植權重和配置
我做的第一件事是檢視公開共享的檢查點中的內容。此筆記本展示了我當時所做的事情。
我發現裡面有 4 個檢查點。我不知道該如何處理,所以我開始做一份更簡單的工作,只使用第一個檢查點。後來我發現 `fairseq` 使用所有 4 個檢查點組成一個整合模型來獲得最佳預測,而 `transformers` 目前不支援該功能。當移植完成並且我能夠測量效能分數時,我發現 `model4.pt` 檢查點提供了最佳分數。但在移植過程中,效能並不重要。由於我只使用了一個檢查點,因此當我比較輸出時,`fairseq` 也只使用一個相同的檢查點,這一點至關重要。
為此,我使用了略有不同的 `fairseq` API
from fairseq import hub_utils
#checkpoint_file = 'model1.pt:model2.pt:model3.pt:model4.pt'
checkpoint_file = 'model1.pt'
model_name_or_path = 'transformer.wmt19.ru-en'
data_name_or_path = '.'
cls = fairseq.model_parallel.models.transformer.ModelParallelTransformerModel
models = cls.hub_models()
kwargs = {'bpe': 'fastbpe', 'tokenizer': 'moses'}
ru2en = hub_utils.from_pretrained(
model_name_or_path,
checkpoint_file,
data_name_or_path,
archive_map=models,
**kwargs
)
首先我看了模型
print(ru2en["models"][0])
TransformerModel(
(encoder): TransformerEncoder(
(dropout_module): FairseqDropout()
(embed_tokens): Embedding(31232, 1024, padding_idx=1)
(embed_positions): SinusoidalPositionalEmbedding()
(layers): ModuleList(
(0): TransformerEncoderLayer(
(self_attn): MultiheadAttention(
(dropout_module): FairseqDropout()
(k_proj): Linear(in_features=1024, out_features=1024, bias=True)
(v_proj): Linear(in_features=1024, out_features=1024, bias=True)
(q_proj): Linear(in_features=1024, out_features=1024, bias=True)
(out_proj): Linear(in_features=1024, out_features=1024, bias=True)
)
[...]
# the full output is in the notebook
看起來與 BART 的架構非常相似,只有幾個層略有不同——有些被新增,有些被移除。所以這是個好訊息,因為我不需要重新發明輪子,而只需調整一個執行良好的設計。
請注意,在上面的程式碼示例中,我沒有使用 `torch.load()` 來載入 `state_dict`。這是我最初所做的,結果非常令人困惑——我缺少 `self_attn.(k|q|v)_proj` 權重,而只有一個 `self_attn.in_proj`。當我嘗試使用 `fairseq` API 載入模型時,它解決了問題——顯然那個模型很舊,並且使用了舊的架構,該架構為 `k/q/v` 使用了一組權重,而較新的架構則將它們分開。當 `fairseq` 載入這個舊模型時,它會重寫權重以匹配現代架構。
我還使用此筆記本直觀地比較了 `state_dict`。在該筆記本中,您還將看到 `fairseq` 在 `last_optimizer_state` 中獲取了 2.2GB 的資料,我們可以安全地忽略它,並將最終模型大小減少 3 倍。
在轉換指令碼中,我還必須刪除一些 `state_dict` 鍵,這些鍵我不會使用,例如 `model.encoder.version`、`model.model` 以及其他一些鍵。
接下來我們看看配置引數
args = dict(vars(ru2en["args"]))
pprint(args)
'activation_dropout': 0.0,
'activation_fn': 'relu',
'adam_betas': '(0.9, 0.98)',
'adam_eps': 1e-08,
'adaptive_input': False,
'adaptive_softmax_cutoff': None,
'adaptive_softmax_dropout': 0,
'arch': 'transformer_wmt_en_de_big',
'attention_dropout': 0.1,
'bpe': 'fastbpe',
[... full output is in the notebook ...]
好的,我們將複製這些來配置模型。我必須重新命名一些引數名稱,只要 `transformers` 對相應的配置設定使用不同的名稱。因此,配置的重新對映如下所示
model_conf = {
"architectures": ["FSMTForConditionalGeneration"],
"model_type": "fsmt",
"activation_dropout": args["activation_dropout"],
"activation_function": "relu",
"attention_dropout": args["attention_dropout"],
"d_model": args["decoder_embed_dim"],
"dropout": args["dropout"],
"init_std": 0.02,
"max_position_embeddings": args["max_source_positions"],
"num_hidden_layers": args["encoder_layers"],
"src_vocab_size": src_vocab_size,
"tgt_vocab_size": tgt_vocab_size,
"langs": [src_lang, tgt_lang],
[...]
"bos_token_id": 0,
"pad_token_id": 1,
"eos_token_id": 2,
"is_encoder_decoder": True,
"scale_embedding": not args["no_scale_embedding"],
"tie_word_embeddings": args["share_all_embeddings"],
}
剩下要做的就是將配置儲存到 `config.json` 中,並將新的 `state_dict` 匯出到 `pytorch.dump` 中。
print(f"Generating {fsmt_tokenizer_config_file}")
with open(fsmt_tokenizer_config_file, "w", encoding="utf-8") as f:
f.write(json.dumps(tokenizer_conf, ensure_ascii=False, indent=json_indent))
[...]
print(f"Generating {pytorch_weights_dump_path}")
torch.save(model_state_dict, pytorch_weights_dump_path)
我們已經移植了配置和模型的 `state_dict` - 太棒了!
您可以在此處找到最終的轉換程式碼。
移植架構程式碼
現在我們已經移植了模型權重和模型配置,我們只需調整從 `modeling_bart.py` 複製的程式碼,使其與 `fairseq` 的功能匹配。
第一步是獲取一個句子,對其進行編碼,然後將其輸入到 `generate` 函式中——對於 `fairseq` 和 `transformers` 都是如此。
經過幾次非常失敗的嘗試(*),我很快意識到,以當前的複雜程度,使用 `print` 作為除錯方法是行不通的,基本的 `pdb` 偵錯程式也一樣。為了高效,並且能夠觀察多個變數並擁有程式碼評估監視器,我需要一個嚴肅的視覺化偵錯程式。我花了一天時間嘗試各種 Python 偵錯程式,直到我嘗試了 `pycharm`,才意識到它正是我需要的工具。這是我第一次使用 `pycharm`,但我很快就弄清楚瞭如何使用它,因為它非常直觀。
- 腳註:模型用俄語生成了“nononono”——這很公平也很搞笑!
隨著時間的推移,我在 `pycharm` 中發現了一個很棒的功能,它允許我按功能對斷點進行分組,我可以根據我正在除錯的內容開啟和關閉整個組。例如,在這裡我關閉了與束搜尋相關的斷點,並打開了解碼器斷點
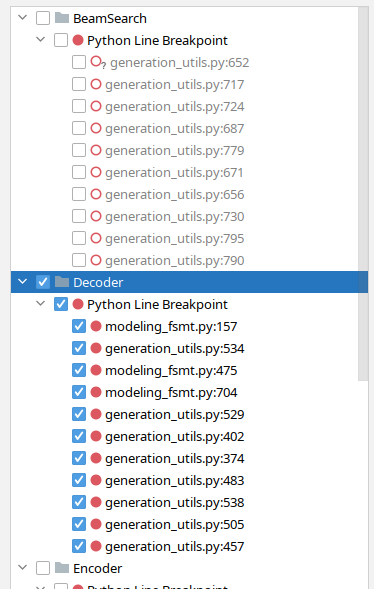
現在我已經使用這個偵錯程式移植 FSMT,我知道如果我用 pdb 做同樣的事情,我將花費很多倍的時間——我甚至可能已經放棄了。
我從兩個指令碼開始
(先不帶 `decode` 部分)
同時執行兩者,在兩側用偵錯程式逐步執行並比較相關變數的值——直到我發現第一個分歧。然後我研究了程式碼,在 `modeling_fsmt.py` 中進行了調整,重新啟動了偵錯程式,快速跳到分歧點並重新檢查了輸出。這個迴圈重複了多次,直到輸出匹配。
我首先要做的改變是移除 `fairseq` 未使用的一些層,然後新增它正在使用的一些新層。其餘的主要是弄清楚何時切換到 `src_vocab_size`,何時切換到 `tgt_vocab_size`——因為在核心模組中它只是 `vocab_size`,這並沒有考慮到可能有兩個字典的模型。最後,我發現一些超引數配置不同,因此也更改了這些配置。
我首先對簡單的無束搜尋執行此過程,一旦輸出 100% 匹配,我就會對更復雜的束搜尋重複此過程。例如,在這裡我發現 `fairseq` 使用了相當於 `early_stopping=True` 的功能,而 `transformers` 預設將其設定為 `False`。當啟用提前停止時,一旦候選數量達到束大小,它就會停止尋找新的候選;而當停用時,演算法只有在找不到比現有候選更高機率的候選時才會停止搜尋。`fairseq` 論文提到使用了 50 的巨大束大小,這彌補了使用提前停止的不足。
分詞器解碼器移植
一旦我移植的 `generate` 函式產生的結果與 `fairseq` 的 `generate` 函式非常相似,接下來我需要完成將輸出解碼為人類可讀文字的最後階段。這使我能夠用我的眼睛進行快速比較和翻譯質量——這是我無法用輸出 ID 做到的。
與編碼過程類似,這個過程是反向進行的。
步驟是
- 將輸出 ID 轉換為文字字串
- 移除 BPE 編碼
- 去分詞——處理跳脫字元等
在這裡進行更多除錯後,我不得不更改處理 BPE 的方式,使其與 `tokenization_xlm.py` 中的原始方法不同,並且還要將輸出透過 `moses` 去分詞器執行。
def convert_tokens_to_string(self, tokens):
""" Converts a sequence of tokens (string) in a single string. """
- out_string = "".join(tokens).replace("</w>", " ").strip()
- return out_string
+ # remove BPE
+ tokens = [t.replace(" ", "").replace("</w>", " ") for t in tokens]
+ tokens = "".join(tokens).split()
+ # detokenize
+ text = self.moses_detokenize(tokens, self.tgt_lang)
+ return text
一切順利。
將模型上傳到 s3
一旦轉換指令碼完成了所有所需檔案到 `transformers` 的移植,我將模型上傳到我的 🤗 s3 帳戶
cd data
transformers-cli upload -y wmt19-ru-en
transformers-cli upload -y wmt19-en-ru
transformers-cli upload -y wmt19-de-en
transformers-cli upload -y wmt19-en-de
cd -
在測試期間,我一直使用我的 🤗 s3 賬戶,一旦我的 PR 完成所有更改並準備合併,我在 PR 中請求將模型移動到 `facebook` 組織賬戶,因為這些模型屬於那裡。
有幾次我只需要更新配置檔案,不想重新上傳大模型,所以我寫了這個小指令碼,它可以生成正確的上傳命令,否則這些命令太長,容易出錯
perl -le 'for $f (@ARGV) { print qq[transformers-cli upload -y $_/$f --filename $_/$f] \
for map { "wmt19-$_" } ("en-ru", "ru-en", "de-en", "en-de")}' \
vocab-src.json vocab-tgt.json tokenizer_config.json config.json
# add/remove files as needed
例如,如果我只需要更新所有 `config.json` 檔案,上面的指令碼就給我提供了一個方便的複製貼上功能
transformers-cli upload -y wmt19-en-ru/config.json --filename wmt19-en-ru/config.json
transformers-cli upload -y wmt19-ru-en/config.json --filename wmt19-ru-en/config.json
transformers-cli upload -y wmt19-de-en/config.json --filename wmt19-de-en/config.json
transformers-cli upload -y wmt19-en-de/config.json --filename wmt19-en-de/config.json
上傳完成後,這些模型即可透過 (*) 訪問
tokenizer = FSMTTokenizer.from_pretrained("stas/wmt19-en-ru")
- 腳註:`stas` 是我在https://huggingface.co上的使用者名稱。
在進行此次上傳之前,我必須使用模型檔案所在的本地路徑,例如
tokenizer = FSMTTokenizer.from_pretrained("/code/huggingface/transformers-fair-wmt/data/wmt19-en-ru")
重要提示:如果您更新模型檔案並重新上傳,您必須注意由於 CDN 快取,上傳的模型可能會在上傳後長達 24 小時內無法使用 - 即將交付舊的快取模型。因此,提前開始使用新模型的唯一方法是:
- 將其下載到本地路徑,並將該路徑作為引數傳遞給 `from_pretrained()`。
- 或者在接下來的 24 小時內 everywhere 使用:`from_pretrained(..., use_cdn=False)` - 僅僅一次是不夠的。
AutoConfig, AutoTokenizer 等
我需要做的另一項更改是將新移植的模型插入到自動化模型 `transformers` 系統中。這主要用於模型網站,用於載入模型配置、分詞器和主類,而無需提供任何特定的類名。例如,在 `FSMT` 的情況下,可以執行以下操作
from transformers import AutoTokenizer, AutoModelWithLMHead
mname = "facebook/wmt19-en-ru"
tokenizer = AutoTokenizer.from_pretrained(mname)
model = AutoModelWithLMHead.from_pretrained(mname)
有 3 個 `*auto*` 檔案包含啟用此功能的對映
-rw-rw-r-- 1 stas stas 16K Sep 23 13:53 src/transformers/configuration_auto.py
-rw-rw-r-- 1 stas stas 65K Sep 23 13:53 src/transformers/modeling_auto.py
-rw-rw-r-- 1 stas stas 13K Sep 23 13:53 src/transformers/tokenization_auto.py
然後還有管道,它們完全向終端使用者隱藏了所有 NLP 的複雜性,並提供了非常簡單的 API,只需選擇一個模型並將其用於手頭的任務。例如,以下是如何使用 `pipeline` 執行摘要任務
summarizer = pipeline("summarization", model="t5-base", tokenizer="t5-base")
summary = summarizer("Some long document here", min_length=5, max_length=20)
print(summary)
撰寫本文時,翻譯管道仍在開發中,請關注此文件,瞭解何時支援翻譯(目前僅支援少數特定模型/語言)。
最後,還有 `src/transformers/__init__.py` 需要編輯,這樣就可以執行
from transformers import FSMTTokenizer, FSMTForConditionalGeneration
而不是
from transformers.tokenization_fsmt import FSMTTokenizer
from transformers.modeling_fsmt import FSMTForConditionalGeneration
但兩者都可以。
為了找到我需要插入 FSMT 的所有位置,我模仿了 `BartConfig`、`BartForConditionalGeneration` 和 `BartTokenizer`。我只是 `grep` 搜尋了包含它們的那些檔案,併為 `FSMTConfig`、`FSMTForConditionalGeneration` 和 `FSMTTokenizer` 插入了相應的條目。
$ egrep -l "(BartConfig|BartForConditionalGeneration|BartTokenizer)" src/transformers/*.py \
| egrep -v "(marian|bart|pegasus|rag|fsmt)"
src/transformers/configuration_auto.py
src/transformers/generation_utils.py
src/transformers/__init__.py
src/transformers/modeling_auto.py
src/transformers/pipelines.py
src/transformers/tokenization_auto.py
在 `grep` 搜尋中,我排除了也包含這些類的檔案。
手動測試
在此之前,我主要使用自己的指令碼進行測試。
一旦翻譯器工作正常,我轉換了反向的 `ru-en` 模型,然後編寫了兩個複述指令碼
它將源語言中的一個句子翻譯成另一種語言,然後將翻譯結果再翻譯回原始語言。由於不同語言表達相似事物的方式不同,這個過程通常會導致複述結果。
藉助這些指令碼,我發現了去分詞器的一些問題,透過偵錯程式逐步除錯並使 fsmt 指令碼產生與 fairseq 版本相同的結果。
在這個階段,無束搜尋(no-beam search)基本能產生相同的結果,但束搜尋(beam search)仍然存在一些差異。為了識別特殊情況,我編寫了一個 fsmt-port-validate.py 指令碼,該指令碼使用 `sacrebleu` 測試資料作為輸入,並透過 `fairseq` 和 `transformers` 翻譯執行該資料,只報告不匹配項。它很快識別出一些剩餘的問題,透過觀察模式,我也能夠解決這些問題。
移植其他模型
接下來我著手移植 `en-de` 和 `de-en` 模型。
我驚訝地發現這些模型的構建方式並不相同。每個模型都有一個合併字典,所以有一瞬間我感到沮喪,因為我以為現在又必須進行巨大的更改來支援它。但是,我不需要做任何更改,因為合併字典無需任何更改即可適應。我只是使用了兩個相同的字典——一個作為源,另一個作為它的副本作為目標。
我編寫了另一個指令碼來測試所有移植模型的A基本功能:fsmt-test-all.py。
測試覆蓋率
下一步非常重要——我需要為移植後的模型準備廣泛的測試。
在 `transformers` 測試套件中,大多數處理大型模型的測試都被標記為 `@slow`,並且它們通常不會在 CI(持續整合)上執行,因為它們確實很慢。因此,我還需要建立一個微型模型,它與正常的預訓練模型具有相同的結構,但它必須非常小,並且可以具有隨機權重。然後,這個微型模型可以用於測試移植的功能。它不能用於質量測試,因為它只有很少的權重,因此無法真正訓練以執行任何實際操作。fsmt-make-tiny-model.py 建立了這樣一個微型模型。生成模型及其所有字典和配置檔案的大小僅為 3MB。我使用 `transformers-cli upload` 將其上傳到 `s3`,現在我可以在測試套件中使用它了。
就像程式碼一樣,我從複製 `tests/test_modeling_bart.py` 開始,並將其轉換為使用 `FSMT`,然後調整它以與新模型一起工作。
然後我將我用於手動測試的幾個指令碼轉換成單元測試——這很簡單。
transformers 包含大量每個模型都會執行的通用測試——我不得不做一些額外的調整,以使這些測試適用於 `FSMT`(主要是為了適應雙字典設定),而且我不得不重寫一些測試,由於此模型的獨特性,這些測試無法執行,因此跳過了它們。您可以在此處檢視結果。
我添加了一個額外的測試,它執行一個輕量級的 BLEU 評估——我只對 4 個模型中的每個模型使用了 8 個文字輸入,並測量了它們的 BLEU 分數。這是測試和生成資料的指令碼。
SinusoidalPositionalEmbedding
fairseq 使用的 SinusoidalPositionalEmbedding 實現與 transformers 使用的略有不同。最初我複製了 fairseq 的實現。但在嘗試使測試套件工作時,我無法透過 torchscript 測試。SinusoidalPositionalEmbedding 的編寫方式使其不會成為 state_dict 的一部分,也不會隨模型權重儲存——該類生成的所有權重都是確定性的,並且未經過訓練。fairseq 使用了一個技巧,透過不將其權重作為引數或緩衝區,然後在 forward 期間將權重切換到正確的裝置來使其透明地工作。torchscript 對此不太滿意,因為它希望在第一次 forward 呼叫之前所有權重都在正確的裝置上。
我不得不重寫實現,將其轉換為正常的 `nn.Embedding` 子類,然後新增功能,在 `save_pretrained()` 期間不儲存這些權重,並且在 `from_pretrained()` 載入 `state_dict` 時,如果找不到這些權重,也不會抱怨。
評估
我知道移植後的模型在大量文字的手動測試中表現相當不錯,但我不知道移植後的模型與原始模型相比表現如何。所以是時候進行評估了。
對於翻譯任務,BLEU 分數被用作評估指標。`transformers` 有一個指令碼 run_eval.py 來執行評估。
以下是 `ru-en` 語對的評估
export PAIR=ru-en
export MODEL=facebook/wmt19-$PAIR
export DATA_DIR=data/$PAIR
export SAVE_DIR=data/$PAIR
export BS=64
export NUM_BEAMS=5
export LENGTH_PENALTY=1.1
mkdir -p $DATA_DIR
sacrebleu -t wmt19 -l $PAIR --echo src > $DATA_DIR/val.source
sacrebleu -t wmt19 -l $PAIR --echo ref > $DATA_DIR/val.target
PYTHONPATH="src:examples/seq2seq" python examples/seq2seq/run_eval.py $MODEL \
$DATA_DIR/val.source $SAVE_DIR/test_translations.txt --reference_path $DATA_DIR/val.target \
--score_path $SAVE_DIR/test_bleu.json --bs $BS --task translation --num_beams $NUM_BEAMS \
--length_penalty $LENGTH_PENALTY --info $MODEL --dump-args
運行了幾分鐘並返回
{'bleu': 39.0498, 'n_obs': 2000, 'runtime': 184, 'seconds_per_sample': 0.092,
'num_beams': 5, 'length_penalty': 1.1, 'info': 'ru-en'}
您可以看到 BLEU 分數是 `39.0498`,並且它使用 `sacrebleu` 提供的 `wmt19` 資料集,評估了 2000 個測試輸入。
請記住,我無法使用模型整合,所以我接下來需要找到表現最佳的檢查點。為此,我編寫了一個指令碼 fsmt-bleu-eval-each-chkpt.py,它轉換每個檢查點,執行評估指令碼並報告最佳的一個。結果我得知 `model4.pt` 在四個可用檢查點中提供了最佳效能。
我沒有得到與原始論文中報告的相同的 BLEU 分數,所以我接下來需要確保我們使用相同的工具比較相同的資料。透過在 `fairseq` 問題中提問,我獲得了 `fairseq` 開發人員用來獲取 BLEU 分數的程式碼——你可以在這裡找到它。但是,唉,他們的方法使用了未公開的重排序方法。此外,他們評估的是去分詞之前的輸出,而不是實際的輸出,這顯然得分更高。總而言之——我們沒有以相同的方式得分 (*)。
- 腳註:論文《關於 BLEU 分數報告清晰度的呼籲》邀請開發者開始使用相同的方法計算指標(tl;dr:使用 `sacrebleu`)。
目前,這個移植模型在 BLEU 分數上略低於原始模型,因為沒有使用模型整合,但在使用相同的測量方法之前,無法準確判斷差異。
移植新模型
上傳了 4 個 fairseq 模型這裡後,有人建議移植 3 個 wmt16 和 2 個 wmt19 AllenAI 模型(Jungo Kasai 等人)。移植過程非常順利,我只需要弄清楚如何將所有原始檔組合在一起,因為它們分散在幾個不相關的存檔中。一旦完成,轉換就沒有任何問題。
我發現的唯一問題是移植後 BLEU 分數低於原始模型。這些模型的建立者 Jungo Kasai 非常樂於助人,他建議使用自定義超引數 `length_penalty=0.6`,一旦我將其插入,我便獲得了更好的結果。
這一發現促使我編寫了一個新指令碼:run_eval_search.py,該指令碼可用於搜尋各種超引數以獲得最佳 BLEU 分數。以下是其用法示例
# search space
export PAIR=ru-en
export DATA_DIR=data/$PAIR
export SAVE_DIR=data/$PAIR
export BS=32
mkdir -p $DATA_DIR
sacrebleu -t wmt19 -l $PAIR --echo src > $DATA_DIR/val.source
sacrebleu -t wmt19 -l $PAIR --echo ref > $DATA_DIR/val.target
PYTHONPATH="src:examples/seq2seq" python examples/seq2seq/run_eval_search.py stas/wmt19-$PAIR \
$DATA_DIR/val.source $SAVE_DIR/test_translations.txt --reference_path $DATA_DIR/val.target \
--score_path $SAVE_DIR/test_bleu.json --bs $BS --task translation \
--search="num_beams=5:8:11:15 length_penalty=0.6:0.7:0.8:0.9:1.0:1.1 early_stopping=true:false"
在這裡,它搜尋 `num_beams`、`length_penalty` 和 `early_stopping` 的所有可能組合。
執行完畢後,它報告
bleu | num_beams | length_penalty | early_stopping
----- | --------- | -------------- | --------------
39.20 | 15 | 1.1 | 0
39.13 | 11 | 1.1 | 0
39.05 | 5 | 1.1 | 0
39.05 | 8 | 1.1 | 0
39.03 | 15 | 1.0 | 0
39.00 | 11 | 1.0 | 0
38.93 | 8 | 1.0 | 0
38.92 | 15 | 1.1 | 1
[...]
您可以看到,在 `transformers` 的情況下,`early_stopping=False` 表現更好(`fairseq` 使用的是 `early_stopping=True` 的等效功能)。
所以對於這 5 個新模型,我使用這個指令碼來尋找最佳預設引數,並在轉換模型時使用了它們。使用者仍然可以在呼叫 `generate()` 時覆蓋這些引數,但為什麼不提供最佳預設值呢?
您可以在此處找到 5 個已移植的 AllenAI 模型。
更多指令碼
由於每一組移植的模型都有其自身的細微差別,我為它們分別編寫了專用指令碼,以便將來可以輕鬆地重新構建,或建立新的指令碼來轉換新模型。您可以在這裡找到所有轉換、評估和其他指令碼。
模型卡
另一件重要的事情是,僅僅移植模型並使其可用是不夠的。還需要提供如何使用它、超引數的細微差別、資料集來源、評估指標等資訊。所有這些都透過建立模型卡來完成,模型卡只是一個以一些元資料開頭的README.md檔案,這些元資料由模型網站使用,然後是所有可以共享的有用資訊。
例如,我們來看看facebook/wmt19-en-ru模型卡。這是它的頂部
---
language:
- en
- ru
thumbnail:
tags:
- translation
- wmt19
- facebook
license: apache-2.0
datasets:
- wmt19
metrics:
- bleu
---
# FSMT
## Model description
This is a ported version of
[...]
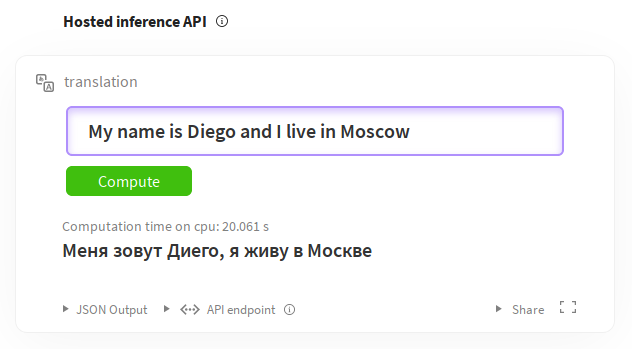
如您所見,我們定義了語言、標籤、許可證、資料集和指標。有關編寫這些內容的完整指南,請參閱模型共享和上傳。其餘部分是描述模型及其細微差別的 Markdown 文件。您還可以透過推理小部件直接從模型頁面試用模型。例如,對於英語到俄語的翻譯:https://huggingface.co/facebook/wmt19-en-ru?text=My+name+is+Diego+and+I+live+in+Moscow。
文件
最後,需要新增文件。
幸運的是,大部分文件都是從模組檔案中的文件字串自動生成的。
和以前一樣,我複製了docs/source/model_doc/bart.rst並將其修改為FSMT。準備好後,我透過在docs/source/index.rst中新增fsmt條目來連結它
我使用了
make docs
來測試新新增的文件是否正確構建。執行該目標後我需要檢查的檔案是docs/_build/html/model_doc/fsmt.html——我只是在瀏覽器中載入並驗證它是否正確渲染。
這是最終的源文件docs/source/model_doc/fsmt.rst及其渲染版本。
提交 PR 的時候了
當我感覺我的工作基本完成時,我準備提交我的 PR。
由於這項工作涉及許多 git 提交,我希望進行一次乾淨的 PR,因此我使用了以下技術,將所有提交壓縮到一個新分支中。這樣,如果我以後想訪問任何一個提交,所有初始提交都還在。
我正在開發的分支名為fair-wmt,我將從中提交 PR 的新分支名為fair-wmt-clean,所以我做了以下操作:
git checkout master
git checkout -b fair-wmt-clean
git merge --squash fair-wmt
git commit -m "Ready for PR"
git push origin fair-wmt-clean
然後我去了 GitHub,基於fair-wmt-clean分支提交了這個 PR。
它經歷了兩個星期的多輪反饋、修改和更多類似迴圈。最終,一切都令人滿意,PR 被合併了。
在這個過程中,我發現了一些問題,增加了新的測試,改進了文件等等,所以時間花得很值。
隨後,我在改進和重構了一些功能、添加了各種構建指令碼、模型卡等之後,又提交了一些 PR。
由於我移植的模型屬於facebook和allenai組織,我不得不請 Sam 將這些模型檔案從我的s3帳戶移動到相應的組織。
結束語
雖然我無法移植模型整合,因為
transformers不支援它,但好的一面是最終的facebook/wmt19-*模型下載大小為 1.1GB,而不是原始的 13GB。出於某種原因,原始模型中包含了最佳化器狀態,因此對於那些只想下載模型並直接用於文字翻譯的人來說,這增加了近 9GB(4x2.2GB)的無用負擔。雖然移植工作一開始看起來非常有挑戰性,因為我既不瞭解
transformers的內部機制,也不瞭解fairseq的內部機制,但回顧起來,它最終並沒有那麼困難。這主要是因為transformers的各個部分已經為我提供了大部分元件——我只需要找到我需要的部件,主要借鑑其他模型,然後對它們進行調整以實現我需要的功能。程式碼和測試都是如此。換句話說——移植是困難的——但如果我必須從頭開始編寫所有內容,那將困難得多。而且找到合適的部件也不容易。
致謝
有Sam Shleifer指導我完成這個過程,對我來說幫助極大,這不僅歸功於他的技術支援,更重要的是,在我遇到困難時,他給予了我啟發和鼓勵。
PR 的合併過程耗費了兩週時間才被接受。在此階段,除了 Sam,Lysandre Debut和Sylvain Gugger透過他們的見解和建議做出了巨大貢獻,我將這些整合到了程式碼庫中。
我感謝所有為
transformers程式碼庫做出貢獻的人,這為我的工作鋪平了道路。
備註
在 Jupyter Notebook 中自動列印所有內容
我的 Jupyter Notebook 配置為自動列印所有表示式,因此我無需顯式地print()它們。預設行為是隻列印每個單元格的最後一個表示式。所以,如果您閱讀我的 Notebook 中的輸出,它們可能與您自己執行時的輸出不同,除非您有相同的設定。
您可以透過在~/.ipython/profile_default/ipython_config.py中新增以下內容(如果沒有則建立)來在 Jupyter Notebook 設定中啟用“列印所有”功能
c = get_config()
# Run all nodes interactively
c.InteractiveShell.ast_node_interactivity = "all"
# restore to the original behavior
# c.InteractiveShell.ast_node_interactivity = "last_expr"
並重新啟動您的 Jupyter Notebook 伺服器。
指向 GitHub 檔案版本的連結
為了確保所有連結在您閱讀本文很久之後仍然有效,這些連結指向程式碼的特定 SHA 版本,而不一定是最新版本。這樣,即使檔案被重新命名或刪除,您仍然可以找到本文所引用的程式碼。如果您想確保檢視最新版本的程式碼,請將連結中的雜湊程式碼替換為master。例如,一個連結
https://github.com/huggingface/transformers/blob/129fdae04033fe4adfe013b734deaec6ec34ae2e/src/transformers/modeling_fsmt.py
變成
https://github.com/huggingface/transformers/blob/master/src/transformers/convert_fsmt_original_pytorch_checkpoint_to_pytorch.py
感謝您的閱讀!

