使用 Hugging Face Transformers 和 Habana Gaudi 預訓練 BERT







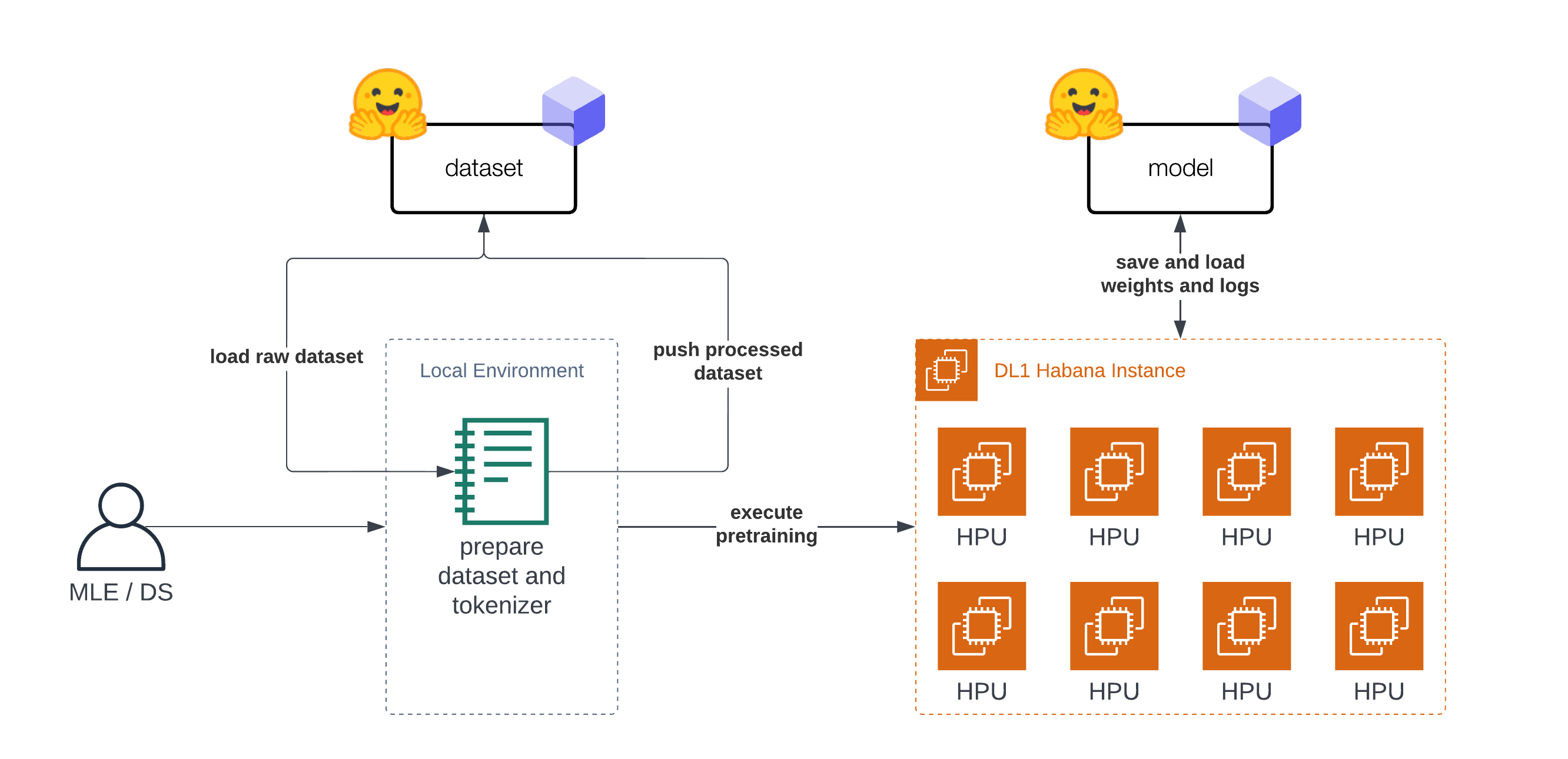
在本教程中,你將學習如何利用 AWS 上基於 Habana Gaudi 的 DL1 例項,從頭開始預訓練 BERT-base,以發揮 Gaudi 的價效比優勢。我們將使用 Hugging Face 的 Transformers、Optimum Habana 和 Datasets 庫,透過掩碼語言建模(BERT 最初的兩個預訓練任務之一)來預訓練一個 BERT-base 模型。在開始之前,我們需要先設定深度學習環境。 檢視程式碼
您將學習如何
注意:步驟 1 到 3 可以/應該在不同大小的例項上執行,因為這些是 CPU 密集型任務。
要求
在開始之前,請確保你已滿足以下要求
- 擁有 DL1 例項型別配額的 AWS 賬戶
- 已安裝 AWS CLI
- 在 CLI 中配置了 AWS IAM 使用者,並具有建立和管理 EC2 例項的許可權
有用的資源
- 在 AWS 上為 Hugging Face Transformers 和 Habana Gaudi 設定深度學習環境
- 使用 EC2 Remote Runner 和 Habana Gaudi 輕鬆設定深度學習
- Optimum Habana 文件
- 預訓練指令碼
- 程式碼:pre-training-bert.ipynb
什麼是 BERT?
BERT,全稱為 Bidirectional Encoder Representations from Transformers,是一種用於自然語言處理的機器學習 (ML) 模型。它由 Google AI Language 的研究人員於 2018 年開發,可作為解決 11 種以上最常見語言任務(如情感分析和命名實體識別)的瑞士軍刀式解決方案。
在我們的部落格 BERT 101 🤗 詳解最先進的 NLP 模型中閱讀更多關於 BERT 的資訊。
什麼是掩碼語言建模 (MLM)?
MLM 透過在句子中掩蓋(隱藏)一個詞,並強制 BERT 雙向使用被遮蓋詞兩側的詞來預測被掩蓋的詞,從而實現/強制從文字中進行雙向學習。
掩碼語言建模示例
“Dang! I’m out fishing and a huge trout just [MASK] my line!”
請在這裡閱讀更多關於掩碼語言建模的資訊。
讓我們開始吧。🚀
注意:步驟 1 到 3 是在 AWS c6i.12xlarge 例項上執行的。
1. 準備資料集
本教程“分為”兩部分。第一部分(步驟 1-3)是關於準備資料集和 Tokenizer。第二部分(步驟 4)是在準備好的資料集上預訓練 BERT。在開始準備資料集之前,我們需要設定我們的開發環境。正如引言中所述,你不需要在 DL1 例項上準備資料集,可以使用你的筆記型電腦或臺式電腦。
首先,我們將安裝 transformers、datasets 和 git-lfs,以便將我們的 Tokenizer 和資料集推送到 Hugging Face Hub 以供後續使用。
!pip install transformers datasets
!sudo apt-get install git-lfs
為了完成我們的設定,讓我們登入 Hugging Face Hub,以便在訓練期間和之後將我們的資料集、Tokenizer、模型工件、日誌和指標推送到 Hub。
為了能夠將我們的模型推送到 Hub,你需要在 Hugging Face Hub 上註冊。
我們將使用 huggingface_hub 包中的 notebook_login 工具登入我們的賬戶。你可以在設定中的訪問令牌處獲取你的令牌。
from huggingface_hub import notebook_login
notebook_login()
既然我們已經登入,讓我們獲取 user_id,它將用於推送工件。
from huggingface_hub import HfApi
user_id = HfApi().whoami()["name"]
print(f"user id '{user_id}' will be used during the example")
最初的 BERT 是在 維基百科和 BookCorpus 資料集上預訓練的。這兩個資料集都可以在 Hugging Face Hub 上找到,並且可以使用 datasets 載入。
注意:對於維基百科,我們將使用 20220301 版本,這與原始分割不同。
第一步,我們載入資料集並將它們合併在一起,以建立一個大的資料集。
from datasets import concatenate_datasets, load_dataset
bookcorpus = load_dataset("bookcorpus", split="train")
wiki = load_dataset("wikipedia", "20220301.en", split="train")
wiki = wiki.remove_columns([col for col in wiki.column_names if col != "text"]) # only keep the 'text' column
assert bookcorpus.features.type == wiki.features.type
raw_datasets = concatenate_datasets([bookcorpus, wiki])
我們不打算做一些高階的資料集準備工作,比如去重、過濾或任何其他預處理。如果你計劃應用這個筆記本來從頭訓練你自己的 BERT 模型,我強烈建議將這些資料準備步驟納入你的工作流程。這將有助於你改進你的語言模型。
2. 訓練 Tokenizer
為了能夠訓練我們的模型,我們需要將文字轉換為分詞格式。大多數 Transformer 模型都帶有預訓練的 Tokenizer,但由於我們是從頭開始預訓練模型,我們也需要在我們的資料上訓練一個 Tokenizer。我們可以使用 transformers 和 BertTokenizerFast 類在我們的資料上訓練一個 Tokenizer。
關於訓練新 Tokenizer 的更多資訊可以在我們的 Hugging Face 課程中找到。
from tqdm import tqdm
from transformers import BertTokenizerFast
# repositor id for saving the tokenizer
tokenizer_id="bert-base-uncased-2022-habana"
# create a python generator to dynamically load the data
def batch_iterator(batch_size=10000):
for i in tqdm(range(0, len(raw_datasets), batch_size)):
yield raw_datasets[i : i + batch_size]["text"]
# create a tokenizer from existing one to re-use special tokens
tokenizer = BertTokenizerFast.from_pretrained("bert-base-uncased")
我們可以用 train_new_from_iterator() 開始訓練 Tokenizer。
bert_tokenizer = tokenizer.train_new_from_iterator(text_iterator=batch_iterator(), vocab_size=32_000)
bert_tokenizer.save_pretrained("tokenizer")
我們將 Tokenizer 推送到 Hugging Face Hub,以便後續訓練我們的模型。
# you need to be logged in to push the tokenizer
bert_tokenizer.push_to_hub(tokenizer_id)
3. 預處理資料集
在我們開始訓練模型之前,最後一步是預處理/分詞我們的資料集。我們將使用我們訓練好的 Tokenizer 對資料集進行分詞,然後將其推送到 Hub,以便稍後在我們的訓練中輕鬆載入。分詞過程也保持得相當簡單,如果文件長於 512 個詞元,它們將被截斷,而不會被分割成多個文件。
from transformers import AutoTokenizer
import multiprocessing
# load tokenizer
# tokenizer = AutoTokenizer.from_pretrained(f"{user_id}/{tokenizer_id}")
tokenizer = AutoTokenizer.from_pretrained("tokenizer")
num_proc = multiprocessing.cpu_count()
print(f"The max length for the tokenizer is: {tokenizer.model_max_length}")
def group_texts(examples):
tokenized_inputs = tokenizer(
examples["text"], return_special_tokens_mask=True, truncation=True, max_length=tokenizer.model_max_length
)
return tokenized_inputs
# preprocess dataset
tokenized_datasets = raw_datasets.map(group_texts, batched=True, remove_columns=["text"], num_proc=num_proc)
tokenized_datasets.features
作為資料處理函式,我們將連線資料集中的所有文字,並生成長度為 tokenizer.model_max_length (512) 的塊。
from itertools import chain
# Main data processing function that will concatenate all texts from our dataset and generate chunks of
# max_seq_length.
def group_texts(examples):
# Concatenate all texts.
concatenated_examples = {k: list(chain(*examples[k])) for k in examples.keys()}
total_length = len(concatenated_examples[list(examples.keys())[0]])
# We drop the small remainder, we could add padding if the model supported it instead of this drop, you can
# customize this part to your needs.
if total_length >= tokenizer.model_max_length:
total_length = (total_length // tokenizer.model_max_length) * tokenizer.model_max_length
# Split by chunks of max_len.
result = {
k: [t[i : i + tokenizer.model_max_length] for i in range(0, total_length, tokenizer.model_max_length)]
for k, t in concatenated_examples.items()
}
return result
tokenized_datasets = tokenized_datasets.map(group_texts, batched=True, num_proc=num_proc)
# shuffle dataset
tokenized_datasets = tokenized_datasets.shuffle(seed=34)
print(f"the dataset contains in total {len(tokenized_datasets)*tokenizer.model_max_length} tokens")
# the dataset contains in total 3417216000 tokens
在我們開始訓練之前,最後一步是將我們準備好的資料集推送到 Hub。
# push dataset to hugging face
dataset_id=f"{user_id}/processed_bert_dataset"
tokenized_datasets.push_to_hub(f"{user_id}/processed_bert_dataset")
4. 在 Habana Gaudi 上預訓練 BERT
在這個例子中,我們將使用 AWS 上的 Habana Gaudi DL1 例項來執行預訓練。我們將使用 Remote Runner 工具包,從我們的本地設定輕鬆地在遠端 DL1 例項上啟動預訓練。如果你想了解更多關於其工作原理的資訊,可以檢視使用 EC2 Remote Runner 和 Habana Gaudi 輕鬆設定深度學習。
!pip install rm-runner
如果使用 GPU,你會使用 Trainer 和 TrainingArguments。由於我們將在 Habana Gaudi 上執行訓練,我們利用了 optimum-habana 庫,因此我們可以使用 GaudiTrainer 和 GaudiTrainingArguments 來替代。GaudiTrainer 是 Trainer 的一個包裝器,它允許你在 Habana Gaudi 例項上預訓練或微調 Transformer 模型。
-from transformers import Trainer, TrainingArguments
+from optimum.habana import GaudiTrainer, GaudiTrainingArguments
# define the training arguments
-training_args = TrainingArguments(
+training_args = GaudiTrainingArguments(
+ use_habana=True,
+ use_lazy_mode=True,
+ gaudi_config_name=path_to_gaudi_config,
...
)
# Initialize our Trainer
-trainer = Trainer(
+trainer = GaudiTrainer(
model=model,
args=training_args,
train_dataset=train_dataset
... # other arguments
)
我們使用的 DL1 例項有 8 個可用的 HPU 核心,這意味著我們可以為我們的模型利用分散式資料並行訓練。為了以分散式方式執行我們的訓練,我們需要建立一個訓練指令碼,該指令碼可以與多程序一起在所有 HPU 上執行。我們建立了一個 run_mlm.py 指令碼,使用 GaudiTrainer 實現掩碼語言建模。為了執行我們的分散式訓練,我們使用 optimum-habana 中的 DistributedRunner 並傳入我們的引數。或者,你可以檢視 optimum-habana 倉庫中的 gaudi_spawn.py。
在開始訓練之前,我們需要定義我們想用於訓練的 超引數。我們利用 GaudiTrainer 的 Hugging Face Hub 整合功能,在訓練期間自動將我們的檢查點、日誌和指標推送到一個倉庫中。
from huggingface_hub import HfFolder
# hyperparameters
hyperparameters = {
"model_config_id": "bert-base-uncased",
"dataset_id": "philschmid/processed_bert_dataset",
"tokenizer_id": "philschmid/bert-base-uncased-2022-habana",
"gaudi_config_id": "philschmid/bert-base-uncased-2022-habana",
"repository_id": "bert-base-uncased-2022",
"hf_hub_token": HfFolder.get_token(), # need to be logged in with `huggingface-cli login`
"max_steps": 100_000,
"per_device_train_batch_size": 32,
"learning_rate": 5e-5,
}
hyperparameters_string = " ".join(f"--{key} {value}" for key, value in hyperparameters.items())
我們可以透過建立一個 EC2RemoteRunner 然後 launch 它來開始我們的訓練。這將啟動我們的 AWS EC2 DL1 例項,並使用 huggingface/optimum-habana:latest 容器在其上執行我們的 run_mlm.py 指令碼。
from rm_runner import EC2RemoteRunner
# create ec2 remote runner
runner = EC2RemoteRunner(
instance_type="dl1.24xlarge",
profile="hf-sm", # adjust to your profile
region="us-east-1",
container="huggingface/optimum-habana:4.21.1-pt1.11.0-synapse1.5.0"
)
# launch my script with gaudi_spawn for distributed training
runner.launch(
command=f"python3 gaudi_spawn.py --use_mpi --world_size=8 run_mlm.py {hyperparameters_string}",
source_dir="scripts",
)
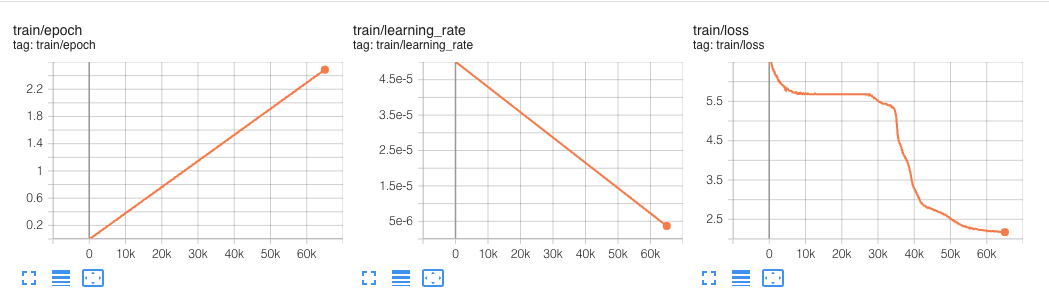
這個實驗運行了 6 萬步。
在我們的 超引數 中,我們定義了一個 max_steps 屬性,將預訓練限制在僅 100_000 步。這 100_000 步,全域性批處理大小為 256,大約耗時 12.5 小時。
BERT 最初是在100 萬步上預訓練的,全域性批處理大小為 256。
我們以 256 個序列的批次大小進行訓練(256 個序列 * 512 個詞元 = 128,000 個詞元/批次),共進行 1,000,000 步,這大約相當於在 33 億詞的語料庫上訓練 40 個 epoch。
這意味著如果我們想要進行完整的預訓練,大約需要 125 小時(12.5 小時 * 10),使用 AWS 上的 Habana Gaudi 成本約為 1,650 美元,這是非常便宜的。
作為比較,保持最快 BERT 預訓練記錄的 DeepSpeed 團隊報告稱,在 1 臺 DGX-2(由 16 個 NVIDIA V100 GPU 驅動,每個 GPU 有 32GB 記憶體)上預訓練 BERT 大約需要 33.25 小時。
為了比較成本,我們可以使用 p3dn.24xlarge 作為參考,它配備了 8 個 NVIDIA V100 32GB GPU,每小時成本約為 31.22 美元。我們需要兩臺這樣的例項才能擁有與 DeepSpeed 報告的相同的“設定”,暫時我們忽略多節點設定帶來的任何開銷(I/O、網路等)。這將使在 AWS 上基於 DeepSpeed GPU 的訓練成本約為 2,075 美元,比 Habana Gaudi 目前提供的成本高出 25%。
這裡需要注意的是,使用DeepSpeed 通常能將效能提高約 1.5 - 2 倍。這意味著,沒有 DeepSpeed 的相同預訓練任務可能會花費兩倍的時間和兩倍的成本,即約 3000-4000 美元。
我們期待在 Gaudi DeepSpeed 整合更廣泛可用後再次進行此實驗。
結論
本教程到此結束。現在你已經瞭解瞭如何使用 Hugging Face Transformers 和 Habana Gaudi 從頭開始預訓練 BERT 的基礎知識。你也看到了從 Trainer 遷移到 GaudiTrainer 是多麼容易。
我們將我們的實現與最快的 BERT 預訓練結果進行了比較,發現 Habana Gaudi 仍然能降低 25% 的成本,並允許我們以約 1,650 美元的價格預訓練 BERT。
這些結果令人難以置信,因為它將允許公司根據自己的語言和領域調整其預訓練模型,與通用的 BERT 模型相比,準確率可提高高達 10%。
如果你有興趣從頭開始訓練自己的 BERT 或其他 Transformer 模型以降低成本並提高準確性,請聯絡我們的專家,瞭解我們的。要了解更多關於 Habana 解決方案的資訊,請閱讀關於我們的合作伙伴關係以及如何聯絡他們。
感謝閱讀!如果你有任何問題,隨時透過 Github 或在論壇上聯絡我。你也可以在 Twitter 或 LinkedIn 上與我聯絡。




