使用 PyTorch Fully Sharded Data Parallel 加速大型模型訓練








在這篇文章中,我們將探討如何利用 Accelerate 庫來訓練大型模型,該庫使使用者能夠利用 PyTorch FullyShardedDataParallel (FSDP) 的最新功能。
動機 🤗
隨著機器學習 (ML) 模型規模、大小和引數的不斷增長,ML 從業人員發現很難在其硬體上訓練甚至載入如此大的模型。一方面,已經發現大型模型學習速度快(資料和計算效率高),並且與小型模型相比效能顯著提高 [1];另一方面,在大多數可用硬體上訓練此類模型變得 prohibitive。
分散式訓練是實現大型 ML 模型訓練的關鍵。大規模分散式訓練領域最近取得了重大進展。以下是一些最顯著的進展:
- 使用 ZeRO - Zero Redundancy Optimizer [2] 的資料並行
- 階段 1:在資料並行 worker/GPU 之間分片最佳化器狀態
- 階段 2:在資料並行 worker/GPU 之間分片最佳化器狀態 + 梯度
- 階段 3:在資料並行 worker/GPU 之間分片最佳化器狀態 + 梯度 + 模型引數
- CPU 解除安裝:在 ZERO 階段 2 [3] 的基礎上將梯度 + 最佳化器狀態解除安裝到 CPU
- 張量並行 [4]:一種模型並行形式,透過巧妙的方式在加速器/GPU 之間分片具有大量引數的單個層的引數,以實現平行計算,同時避免昂貴的通訊同步開銷。
- 流水線並行 [5]:一種模型並行形式,將模型的不同層放置在不同的加速器/GPU 上,並採用流水線技術使所有加速器同時執行。例如,第二個加速器/GPU 計算第一個微批次,而第一個加速器/GPU 計算第二個微批次。
- 3D 並行 [3]:結合使用 ZERO 的資料並行 + 張量並行 + 流水線並行來訓練數千億引數的龐大模型。例如,BigScience 176B 引數語言模型就採用了這種技術 [6]。
在這篇文章中,我們將探討使用 ZeRO 進行資料並行,更具體地說是最新的 PyTorch 功能 FullyShardedDataParallel (FSDP)。 DeepSpeed 和 FairScale 已經實現了 ZERO 論文的核心思想。這些功能已整合到 `transformers` Trainer 中,並附有精彩的部落格文章 透過 DeepSpeed 和 FairScale 使用 ZeRO 適應更多模型並更快地訓練 [10]。 PyTorch 最近將 Fairscale FSDP 上游整合到 PyTorch Distributed 中,並進行了額外的最佳化。
Accelerate 🚀:無需任何程式碼更改即可利用 PyTorch FSDP
我們將研究使用 GPT-2 Large (762M) 和 XL (1.5B) 模型變體進行因果語言建模的任務。
下面是 GPT-2 模型預訓練的程式碼。它類似於官方的因果語言建模示例 此處,增加了 2 個引數 `n_train` (2000) 和 `n_val` (500) 以防止在整個資料上進行預處理/訓練,從而進行快速概念驗證基準測試。
執行命令 `accelerate config` 後的示例 FSDP 配置
compute_environment: LOCAL_MACHINE
deepspeed_config: {}
distributed_type: FSDP
fsdp_config:
min_num_params: 2000
offload_params: false
sharding_strategy: 1
machine_rank: 0
main_process_ip: null
main_process_port: null
main_training_function: main
mixed_precision: 'no'
num_machines: 1
num_processes: 2
use_cpu: false
多 GPU FSDP
在這裡,我們對單節點多 GPU 設定進行了實驗。我們比較了分散式資料並行 (DDP) 和 FSDP 在各種配置下的效能。首先,使用 GPT-2 Large (762M) 模型,其中 DDP 在特定批大小下可以正常工作,而不會丟擲記憶體不足 (OOM) 錯誤。接下來,使用 GPT-2 XL (1.5B) 模型,其中 DDP 即使在批大小為 1 的情況下也會因 OOM 錯誤而失敗。我們觀察到 FSDP 允許 GPT-2 Large 模型使用更大的批大小,並且它能夠以不錯的批大小訓練 GPT-2 XL 模型,這與 DDP 不同。
硬體設定:2 塊 24GB NVIDIA Titan RTX GPU。
訓練 GPT-2 Large 模型(762M 引數)的命令
export BS=#`try with different batch sizes till you don't get OOM error,
#i.e., start with larger batch size and go on decreasing till it fits on GPU`
time accelerate launch run_clm_no_trainer.py \
--model_name_or_path gpt2-large \
--dataset_name wikitext \
--dataset_config_name wikitext-2-raw-v1 \
--per_device_train_batch_size $BS
--per_device_eval_batch_size $BS
--num_train_epochs 1
--block_size 12
FSDP 執行示例:
| 方法 | 最大批處理大小 ($BS) | 大致訓練時間(分鐘) | 備註 |
|---|---|---|---|
| DDP(分散式資料並行) | 7 | 15 | |
| DDP + FP16 | 7 | 8 | |
| 使用 SHARD_GRAD_OP 的 FSDP | 11 | 11 | |
| 使用 min_num_params = 1M + FULL_SHARD 的 FSDP | 15 | 12 | |
| 使用 min_num_params = 2K + FULL_SHARD 的 FSDP | 15 | 13 | |
| 使用 min_num_params = 1M + FULL_SHARD + 解除安裝到 CPU 的 FSDP | 20 | 23 | |
| 使用 min_num_params = 2K + FULL_SHARD + 解除安裝到 CPU 的 FSDP | 22 | 24 |
表 1:GPT-2 Large (762M) 模型上的 FSDP 基準測試
與 DDP 相比,從表 1 中我們可以觀察到 FSDP 能夠實現更大的批處理大小,在不使用 CPU 解除安裝和使用 CPU 解除安裝的情況下分別達到 2 倍到 3 倍。在訓練時間方面,DDP 混合精度最快,其次是使用 ZERO 階段 2 和階段 3 的 FSDP。由於因果語言建模任務始終具有固定的上下文序列長度(--block_size),因此 FSDP 在訓練時間方面的提速並不明顯。對於動態批處理的應用,FSDP 能夠實現更大的批處理大小,因此在訓練時間方面可能會有顯著的提速。FSDP 混合精度支援目前在 Transformer 上存在一些 問題。一旦支援,訓練時間將進一步大幅提高。
CPU 解除安裝以實現無法適應 GPU 記憶體的龐大模型訓練
訓練 GPT-2 XL 模型(1.5B 引數)的命令
export BS=#`try with different batch sizes till you don't get OOM error,
#i.e., start with larger batch size and go on decreasing till it fits on GPU`
time accelerate launch run_clm_no_trainer.py \
--model_name_or_path gpt2-xl \
--dataset_name wikitext \
--dataset_config_name wikitext-2-raw-v1 \
--per_device_train_batch_size $BS
--per_device_eval_batch_size $BS
--num_train_epochs 1
--block_size 12
| 方法 | 最大批處理大小 ($BS) | GPU 數量 | 大致訓練時間(小時) | 備註 |
|---|---|---|---|---|
| DDP | 1 | 1 | 不適用 | OOM 錯誤 RuntimeError: CUDA 記憶體不足。嘗試分配 40.00 MiB(GPU 0;總容量 23.65 GiB;已分配 22.27 GiB;剩餘 20.31 MiB;PyTorch 總共保留 22.76 GiB) |
| DDP | 1 | 2 | 不適用 | OOM 錯誤 RuntimeError: CUDA 記憶體不足。嘗試分配 40.00 MiB(GPU 0;總容量 23.65 GiB;已分配 22.27 GiB;剩餘 20.31 MiB;PyTorch 總共保留 22.76 GiB) |
| DDP + FP16 | 1 | 1 | 不適用 | OOM 錯誤 RuntimeError: CUDA 記憶體不足。嘗試分配 40.00 MiB(GPU 0;總容量 23.65 GiB;已分配 22.27 GiB;剩餘 20.31 MiB;PyTorch 總共保留 22.76 GiB) |
| 使用 min_num_params = 2K 的 FSDP | 5 | 2 | 0.6 | |
| 使用 min_num_params = 2K + 解除安裝到 CPU 的 FSDP | 10 | 1 | 3 | |
| 使用 min_num_params = 2K + 解除安裝到 CPU 的 FSDP | 14 | 2 | 1.16 |
表 2:GPT-2 XL (1.5B) 模型上的 FSDP 基準測試
從表 2 中,我們可以觀察到 DDP(有和沒有 fp16)甚至無法以批大小為 1 的方式執行,並導致 CUDA OOM 錯誤。FSDP 與 Zero-Stage 3 能夠在 2 個 GPU 上以批大小 5(有效批大小 = 10 (5 X 2))執行。FSDP 與 CPU 解除安裝可以在使用 2 個 GPU 時進一步將每個 GPU 的最大批大小增加到 14。FSDP 與 CPU 解除安裝能夠在單個 GPU 上以批大小 10 訓練 GPT-2 1.5B 模型。這使得計算資源最少的 ML 從業人員能夠訓練此類大型模型,從而使大型模型訓練民主化。
FSDP 整合的功能和限制
讓我們深入瞭解 Accelerate 為 FSDP 整合提供的當前支援和已知限制。
FSDP 支援所需的 PyTorch 版本:PyTorch Nightly(或 1.12.0,如果您在此釋出後閱讀此內容),因為 FSDP 啟用後的模型儲存僅在最近的修復後才可用。
透過 CLI 配置
- 分片策略:[1] FULL_SHARD,[2] SHARD_GRAD_OP
- 最小引數數量:FSDP 預設自動包裝的最小引數數量。
- 解除安裝引數:決定是否將引數和梯度解除安裝到 CPU。
為了獲得更多控制,使用者可以利用 `FullyShardedDataParallelPlugin`,其中他們可以指定 `auto_wrap_policy`、`backward_prefetch` 和 `ignored_modules`。
建立此類的例項後,使用者可以在建立 Accelerator 物件時將其傳入。
有關這些選項的更多資訊,請參閱 PyTorch FullyShardedDataParallel 程式碼。
接下來,我們將看到 `min_num_params` 配置的重要性。下面是 [8] 中關於 FSDP 自動包裝策略重要性的摘錄。

(來源: 連結)
當使用 `default_auto_wrap_policy` 時,如果層中的引數數量超過 `min_num_params`,則該層將被包裝在 FSDP 模組中。用於在 GLUE MRPC 任務上微調 BERT-Large (330M) 模型的程式碼是官方完整的 NLP 示例,概述瞭如何正確使用 FSDP 功能,並增加了用於跟蹤峰值記憶體使用量的實用程式。
fsdp_with_peak_mem_tracking.py
我們利用 Accelerate 中的跟蹤功能支援來記錄訓練和評估的峰值記憶體使用情況以及評估指標。下面是來自 wandb 執行 的圖表快照。 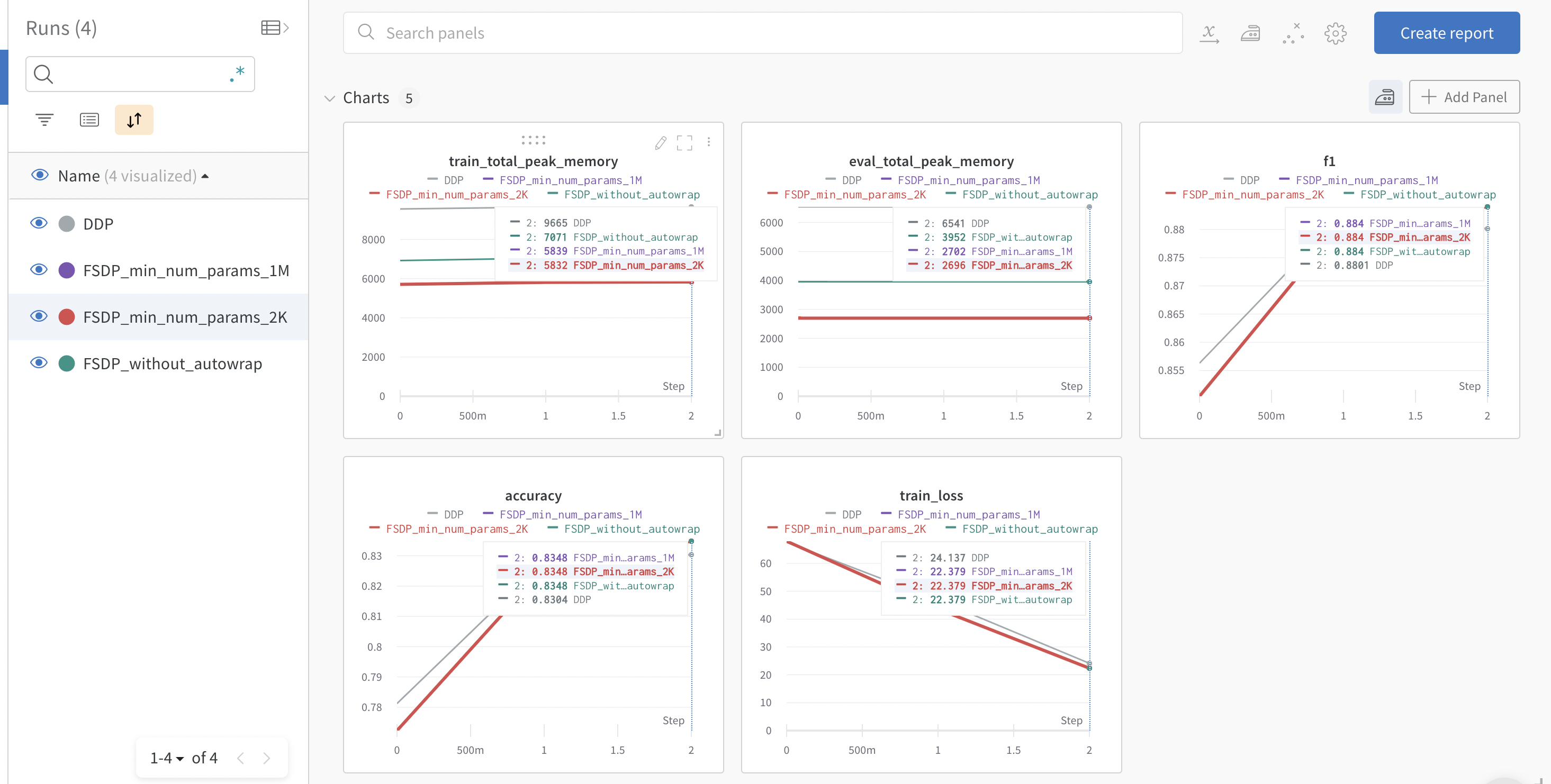
我們可以觀察到,DDP 消耗的記憶體是 FSDP 自動包裝的兩倍。FSDP 不帶自動包裝的記憶體消耗比帶自動包裝的 FSDP 多,但遠低於 DDP。帶自動包裝且 `min_num_params=2k` 的 FSDP 記憶體消耗略低於 `min_num_params=1M` 的設定。這突出顯示了 FSDP 自動包裝策略的重要性,使用者應該嘗試使用 `min_num_params` 來找到能夠顯著節省記憶體且不會導致大量通訊開銷的設定。PyTorch 團隊正在開發此配置的自動調優工具,如 [8] 中所述。
需要注意的一些注意事項
PyTorch FSDP 自動包裝子模組,扁平化引數並就地分片引數。因此,在模型包裝之前建立的任何最佳化器都會損壞並佔用更多記憶體。因此,強烈建議在建立最佳化器之前準備模型,這會更有效率。在單個模型的情況下,`Accelerate` 將自動包裝模型併為您建立一個最佳化器,併發出警告訊息。
FSDP 警告:使用 FSDP 時,建議在建立最佳化器之前為模型呼叫 prepare,這樣更有效率。
然而,以下是使用 FSDP 時準備模型和最佳化器的推薦方法
model = AutoModelForSequenceClassification.from_pretrained("bert-base-cased", return_dict=True)
+ model = accelerator.prepare(model)
optimizer = torch.optim.AdamW(params=model.parameters(), lr=lr)
- model, optimizer, train_dataloader, eval_dataloader, lr_scheduler = accelerator.prepare(model,
- optimizer, train_dataloader, eval_dataloader, lr_scheduler
- )
+ optimizer, train_dataloader, eval_dataloader, lr_scheduler = accelerator.prepare(
+ optimizer, train_dataloader, eval_dataloader, lr_scheduler
+ )
在單個模型的情況下,如果您已經使用多個引數組建立了最佳化器並一起呼叫了 prepare,那麼引數組將丟失並顯示以下警告:
FSDP 警告:使用 FSDP 時,由於巢狀模組包裝和引數扁平化,多個引數組將被合併為單個引數組。
這是因為在包裝之前建立的引數組在包裝之後將失去意義,因為巢狀 FSDP 模組的引數將被扁平化為一維陣列(這可能會佔用多層)。例如,以下是 GPU 0 上 FSDP 模型的命名引數(當使用 2 個 GPU 時。一維陣列中大約有 55M(110M/2)個引數,因為這將是引數的第一個分片)。在這裡,如果一個模型對未包裝的 BERT-Base 模型的 [bias, LayerNorm.weight] 命名引數應用了不權重衰減,則不能將其應用於下面的 FSDP 包裝模型,因為沒有這些字串的命名引數,並且這些層的引數與各種其他層的引數連線在一起。更多細節請參閱此 問題(`原始模型引數的 .grads 未設定,這意味著它們無法單獨最佳化(這就是我們不支援多個引數組的原因)`)。
```
{
'_fsdp_wrapped_module.flat_param': torch.Size([494209]),
'_fsdp_wrapped_module._fpw_module.bert.embeddings.word_embeddings._fsdp_wrapped_module.flat_param': torch.Size([11720448]),
'_fsdp_wrapped_module._fpw_module.bert.encoder._fsdp_wrapped_module.flat_param': torch.Size([42527232])
}
```
在多個模型的情況下,必須在建立最佳化器之前準備模型,否則會丟擲錯誤。
FSDP 目前不支援混合精度,我們正在等待 PyTorch 修復對其的支援。
工作原理 📝
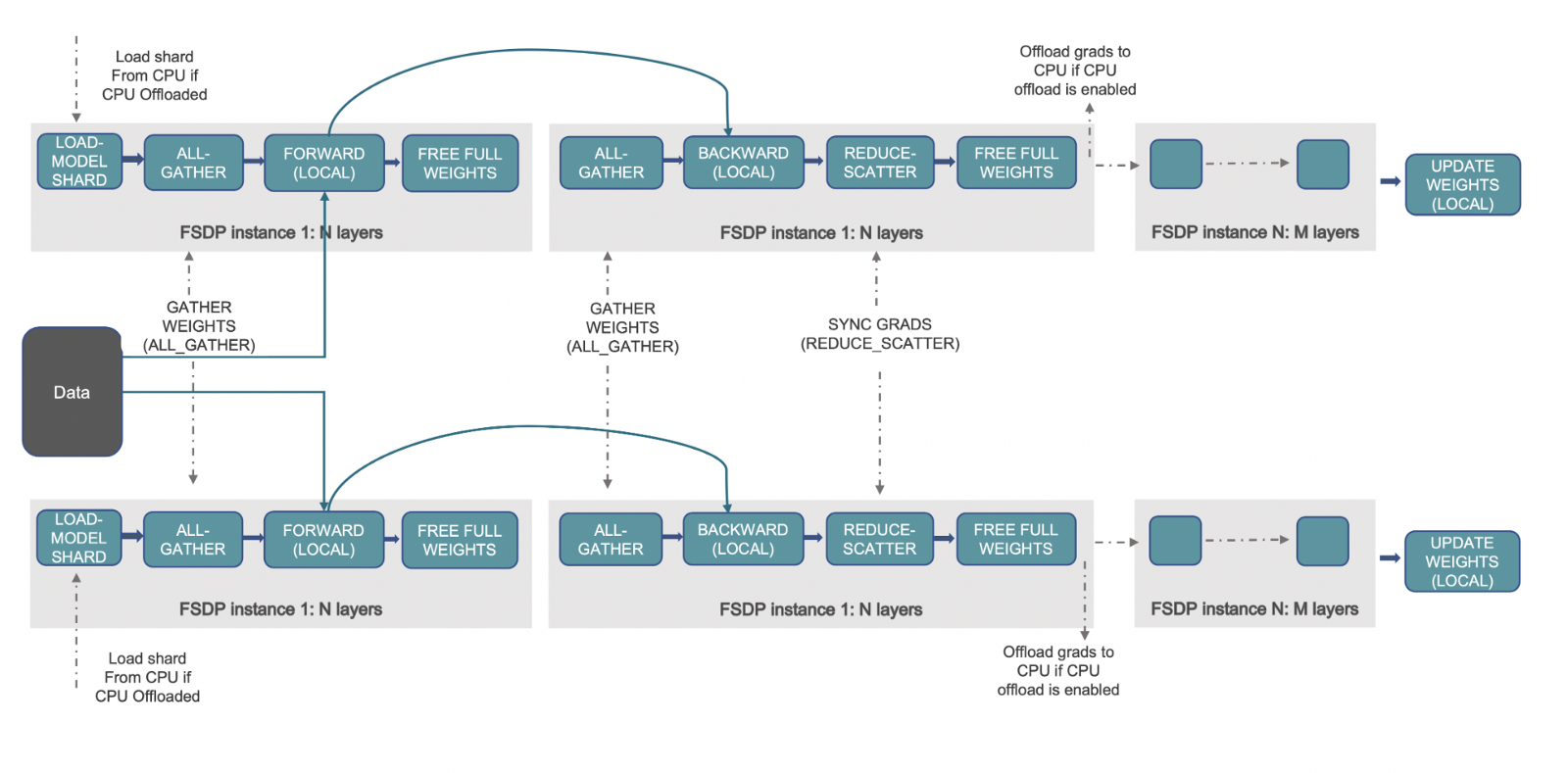
(來源: 連結)
上述工作流程概述了 FSDP 啟用後幕後發生的事情。讓我們首先了解 DDP 的工作原理以及 FSDP 如何改進它。在 DDP 中,每個 worker/加速器/GPU 都有一個完整的模型引數、梯度和最佳化器狀態副本。每個 worker 獲得不同的資料批次,它透過前向傳播,計算損失,然後是反向傳播以生成梯度。現在,執行一次 all-reduce 操作,其中每個 worker 從其餘 worker 獲取梯度並進行平均。這樣,每個 worker 現在擁有相同的全域性梯度,最佳化器使用這些梯度更新模型引數。我們可以看到,擁有完整的副本會在每個 GPU 上消耗大量冗餘記憶體,這限制了批處理大小以及模型的大小。
FSDP 精確地透過在資料並行 worker 之間分片最佳化器狀態、梯度和模型引數來解決這個問題。它進一步促進了所有這些張量的 CPU 解除安裝,從而能夠載入無法適應可用 GPU 記憶體的大型模型。與 DDP 類似,每個 worker 獲得不同的資料批次。在前向傳播期間,如果啟用了 CPU 解除安裝,則本地分片的引數首先複製到 GPU/加速器。然後,每個 worker 對給定的 FSDP 包裝模組/層執行 all-gather 操作以獲取所有所需的引數,執行計算,然後釋放/清空其他 worker 的引數分片。這適用於所有 FSDP 模組。在前向傳播之後計算損失,在反向傳播期間,再次執行 all-gather 操作以獲取給定 FSDP 模組所需的所有引數,執行計算以獲取區域性梯度,然後釋放其他 worker 的分片。現在,區域性梯度被平均並透過 reduce-scatter 操作分片到每個相關 worker。這允許每個 worker 更新其本地分片的引數。如果激活了 CPU 解除安裝,梯度將傳遞到 CPU 以直接在 CPU 上更新引數。
請參閱 [7, 8, 9] 以獲取有關 PyTorch FSDP 工作原理和使用此功能進行的廣泛實驗的所有深入細節。
問題
如果您在使用 PyTorch FSDP 整合部分遇到任何問題,請在 accelerate 中提出問題。
但是,如果您在 PyTorch FSDP 配置和部署方面遇到問題,則需要諮詢相關領域的專家,因此,請改為提出 PyTorch 問題。
參考
[1] 先訓練大模型,再壓縮:重新思考 Transformer 高效訓練和推理的模型大小
[3] DeepSpeed:人人可用的極限規模模型訓練 - 微軟研究院
[4] Megatron-LM:使用模型並行訓練數十億引數語言模型
[5] 隆重推出 GPipe,一個用於高效訓練大規模神經網路模型的開源庫
[7] PyTorch Fully Sharded Data Parallel (FSDP) API 介紹 | PyTorch
[8] Fully Sharded Data Parallel (FSDP) 入門 — PyTorch 教程 1.11.0+cu102 文件
[9] 使用 PyTorch Fully Sharded Data Parallel 在 AWS 上訓練萬億引數模型 | PyTorch | PyTorch | 2022 年 3 月 | Medium


