分散式訓練:使用 🤗 Transformers 和 Amazon SageMaker 訓練 BART/T5 進行文字摘要



如果您錯過了:3 月 25 日,我們宣佈與 Amazon SageMaker 合作,以簡化最先進機器學習模型的建立,並更快地釋出尖端 NLP 功能。
我們與 SageMaker 團隊一起構建了 🤗 Transformers 最佳化深度學習容器,以加速基於 Transformers 的模型的訓練。感謝 AWS 的朋友們!🤗 🚀
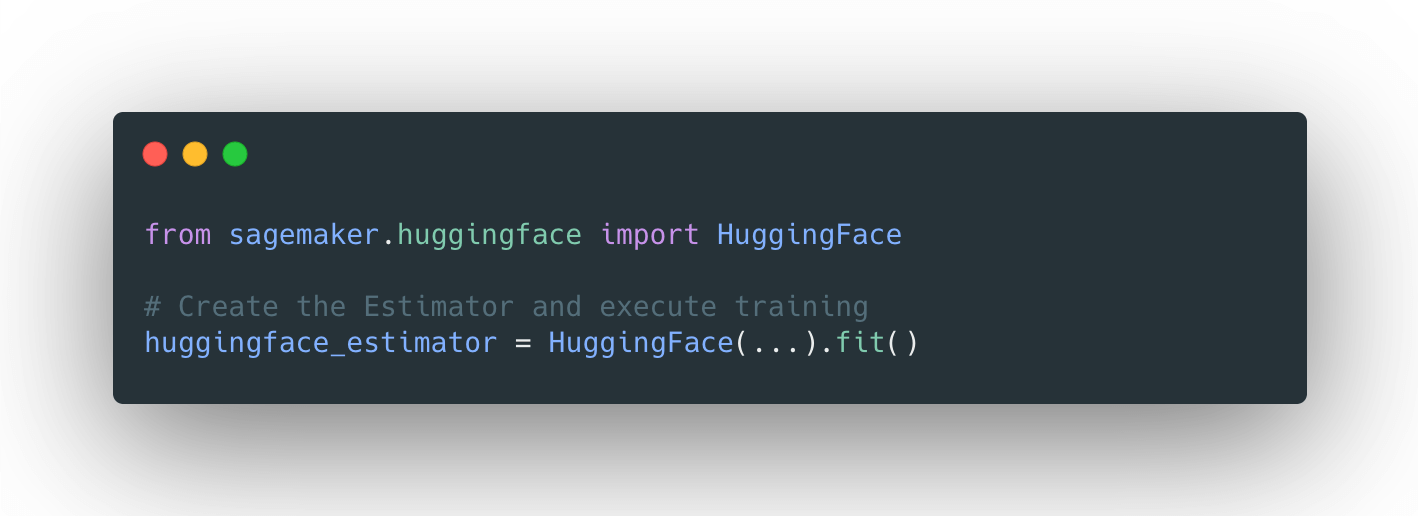
藉助 SageMaker Python SDK 中新的 HuggingFace 估計器,您只需一行程式碼即可開始訓練。
公告部落格文章提供了您需要了解的有關整合的所有資訊,包括“入門”示例以及文件、示例和功能的連結。
此處再次列出
- 🤗 Transformers 文件:Amazon SageMaker
- 示例筆記本
- Amazon SageMaker 關於 Hugging Face 的文件
- Python SDK SageMaker 關於 Hugging Face 的文件
- 深度學習容器
如果您不熟悉 Amazon SageMaker:“Amazon SageMaker 是一項完全託管的服務,為每位開發人員和資料科學家提供了快速構建、訓練和部署機器學習 (ML) 模型的能力。SageMaker 消除了機器學習過程中每個步驟的繁重工作,使開發高質量模型變得更容易。”[參考]
教程
我們將使用新的 Hugging Face DLCs 和 Amazon SageMaker 擴充套件來訓練分散式 Seq2Seq-transformer 模型,用於摘要任務,使用transformers和datasets庫,然後將模型上傳到 huggingface.co 並進行測試。
作為分散式訓練策略,我們將使用SageMaker 資料並行,該功能已內建到 Trainer API 中。要使用資料並行,我們只需在 HuggingFace 估計器中定義 distribution 引數即可。
# configuration for running training on smdistributed Data Parallel
distribution = {'smdistributed':{'dataparallel':{ 'enabled': True }}}
在本教程中,我們將使用 Amazon SageMaker Notebook 例項執行我們的訓練作業。您可以在此處瞭解如何設定 Notebook 例項。
我們將要做什麼
- 設定開發環境並安裝 sagemaker
- 選擇 🤗 Transformers
examples/指令碼 - 配置分散式訓練和超引數
- 建立
HuggingFace估計器並開始訓練 - 將微調模型上傳到 huggingface.co
- 測試推理
模型和資料集
我們將在 samsum 資料集上微調 facebook/bart-large-cnn。“BART 是一種以去噪為預訓練目標的序列到序列模型。”[參考]
samsum 資料集包含約 1.6 萬個類似即時通訊的對話及其摘要。
{"id": "13818513",
"summary": "Amanda baked cookies and will bring Jerry some tomorrow.",
"dialogue": "Amanda: I baked cookies. Do you want some?\r\nJerry: Sure!\r\nAmanda: I'll bring you tomorrow :-)"}
設定開發環境並安裝 SageMaker
SageMaker Notebook 例項執行後,我們可以選擇 Jupyter Notebook 或 JupyterLab,並使用 conda_pytorch_p36 kernel 建立新的 Notebook。
注意: 使用 Jupyter 是可選的:我們也可以從任何安裝了 SDK、連線到雲和具有適當許可權的地方啟動 SageMaker 訓練作業,例如筆記型電腦、其他 IDE 或任務排程器(如 Airflow 或 AWS Step Functions)。
之後我們可以安裝所需的依賴項
!pip install transformers "datasets[s3]" sagemaker --upgrade
為模型上傳安裝 git-lfs。
!curl -s https://packagecloud.io/install/repositories/github/git-lfs/script.rpm.sh | sudo bash
!sudo yum install git-lfs -y
!git lfs install
要在 SageMaker 上執行訓練,我們需要建立一個 sagemaker Session 並提供具有正確許可權的 IAM 角色。此 IAM 角色稍後將附加到 TrainingJob,使其能夠下載資料,例如從 Amazon S3。
import sagemaker
sess = sagemaker.Session()
role = sagemaker.get_execution_role()
print(f"IAM role arn used for running training: {role}")
print(f"S3 bucket used for storing artifacts: {sess.default_bucket()}")
選擇 🤗 Transformers examples/ 指令碼
🤗 Transformers 儲存庫包含幾個 examples/ 指令碼,用於對從 language-modeling 到 token-classification 的任務進行模型微調。在我們的例子中,我們使用 seq2seq/ 示例中的 run_summarization.py。
注意:您可以按原樣使用本教程,以使用不同的示例指令碼訓練您的模型。
由於 HuggingFace Estimator 內建了 git 支援,我們可以指定一個儲存在 GitHub 儲存庫中的訓練指令碼作為 entry_point 和 source_dir。
我們將使用 transformers 4.4.2 DLC,這意味著我們需要將 v4.4.2 配置為拉取相容示例指令碼的分支。
#git_config = {'repo': 'https://github.com/huggingface/transformers.git','branch': 'v4.4.2'} # v4.4.2 is referring to the `transformers_version you use in the estimator.
# used due an missing package in v4.4.2
git_config = {'repo': 'https://github.com/philschmid/transformers.git','branch': 'master'} # v4.4.2 is referring to the `transformers_version you use in the estimator.
配置分散式訓練和超引數
接下來,我們將定義我們的 hyperparameters 並配置我們的分散式訓練策略。作為超引數,我們可以定義任何 Seq2SeqTrainingArguments 和 run_summarization.py 中定義的引數。
# hyperparameters, which are passed into the training job
hyperparameters={
'per_device_train_batch_size': 4,
'per_device_eval_batch_size': 4,
'model_name_or_path':'facebook/bart-large-cnn',
'dataset_name':'samsum',
'do_train':True,
'do_predict': True,
'predict_with_generate': True,
'output_dir':'/opt/ml/model',
'num_train_epochs': 3,
'learning_rate': 5e-5,
'seed': 7,
'fp16': True,
}
# configuration for running training on smdistributed Data Parallel
distribution = {'smdistributed':{'dataparallel':{ 'enabled': True }}}
由於我們使用的是 SageMaker 資料並行,我們的 total_batch_size 將是 per_device_train_batch_size * n_gpus。
建立 HuggingFace 估計器並開始訓練
訓練前的最後一步是建立 HuggingFace 估計器。該估計器處理端到端的 Amazon SageMaker 訓練。我們定義哪個微調指令碼應作為 entry_point 使用,應使用哪個 instance_type,以及傳入哪個 hyperparameters。
from sagemaker.huggingface import HuggingFace
# create the Estimator
huggingface_estimator = HuggingFace(
entry_point='run_summarization.py', # script
source_dir='./examples/seq2seq', # relative path to example
git_config=git_config,
instance_type='ml.p3dn.24xlarge',
instance_count=2,
transformers_version='4.4.2',
pytorch_version='1.6.0',
py_version='py36',
role=role,
hyperparameters = hyperparameters,
distribution = distribution
)
我們使用的 instance_type 是 ml.p3dn.24xlarge,它包含 8 個 NVIDIA A100,instance_count 為 2。這意味著我們將在 16 個 GPU 上執行訓練,total_batch_size 為 16*4=64。我們將訓練一個 4 億引數的模型,total_batch_size 為 64,這真是太棒了。要開始訓練,我們呼叫 .fit() 方法。
# starting the training job
huggingface_estimator.fit()
2021-04-01 13:00:35 Starting - Starting the training job...
2021-04-01 13:01:03 Starting - Launching requested ML instancesProfilerReport-1617282031: InProgress
2021-04-01 13:02:23 Starting - Preparing the instances for training......
2021-04-01 13:03:25 Downloading - Downloading input data...
2021-04-01 13:04:04 Training - Downloading the training image...............
2021-04-01 13:06:33 Training - Training image download completed. Training in progress
....
....
2021-04-01 13:16:47 Uploading - Uploading generated training model
2021-04-01 13:27:49 Completed - Training job completed
Training seconds: 2882
Billable seconds: 2882
訓練時間為 2882 秒,因為它們乘以例項數。如果我們將 2882/2=1441 計算出來,它就是從“Downloading the training image”(下載訓練映象)到“Training job completed”(訓練作業完成)的持續時間。轉換為實際費用,我們在 16 個 NVIDIA Tesla V100-GPU 上訓練一個最先進的摘要模型大約花費 28 美元。
將微調模型上傳到 huggingface.co
由於我們的模型取得了相當好的分數,我們將其上傳到 huggingface.co,建立一個 model_card 並使用託管推理小部件進行測試。要上傳模型,您需要在此處建立一個帳戶。
我們可以使用以下程式碼片段從 Amazon S3 下載模型並將其解壓縮。
import os
import tarfile
from sagemaker.s3 import S3Downloader
local_path = 'my_bart_model'
os.makedirs(local_path, exist_ok = True)
# download model from S3
S3Downloader.download(
s3_uri=huggingface_estimator.model_data, # s3 uri where the trained model is located
local_path=local_path, # local path where *.tar.gz will be saved
sagemaker_session=sess # sagemaker session used for training the model
)
# unzip model
tar = tarfile.open(f"{local_path}/model.tar.gz", "r:gz")
tar.extractall(path=local_path)
tar.close()
os.remove(f"{local_path}/model.tar.gz")
在我們將模型上傳到 huggingface.co 之前,我們需要建立一個 model_card。model_card 描述了模型,包括超引數、結果,並指定了用於訓練的資料集。為了建立 model_card,我們在 local_path 中建立一個 README.md
# read eval and test results
with open(f"{local_path}/eval_results.json") as f:
eval_results_raw = json.load(f)
eval_results={}
eval_results["eval_rouge1"] = eval_results_raw["eval_rouge1"]
eval_results["eval_rouge2"] = eval_results_raw["eval_rouge2"]
eval_results["eval_rougeL"] = eval_results_raw["eval_rougeL"]
eval_results["eval_rougeLsum"] = eval_results_raw["eval_rougeLsum"]
with open(f"{local_path}/test_results.json") as f:
test_results_raw = json.load(f)
test_results={}
test_results["test_rouge1"] = test_results_raw["test_rouge1"]
test_results["test_rouge2"] = test_results_raw["test_rouge2"]
test_results["test_rougeL"] = test_results_raw["test_rougeL"]
test_results["test_rougeLsum"] = test_results_raw["test_rougeLsum"]
在提取所有需要包含的指標後,我們將建立 README.md。除了自動生成結果表之外,我們還將指標手動新增到模型卡元資料中的 model-index 下。
import json
MODEL_CARD_TEMPLATE = """
---
language: en
tags:
- sagemaker
- bart
- summarization
license: apache-2.0
datasets:
- samsum
model-index:
- name: {model_name}
results:
- task:
name: Abstractive Text Summarization
type: abstractive-text-summarization
dataset:
name: "SAMSum Corpus: A Human-annotated Dialogue Dataset for Abstractive Summarization"
type: samsum
metrics:
- name: Validation ROGUE-1
type: rogue-1
value: 42.621
- name: Validation ROGUE-2
type: rogue-2
value: 21.9825
- name: Validation ROGUE-L
type: rogue-l
value: 33.034
- name: Test ROGUE-1
type: rogue-1
value: 41.3174
- name: Test ROGUE-2
type: rogue-2
value: 20.8716
- name: Test ROGUE-L
type: rogue-l
value: 32.1337
widget:
- text: |
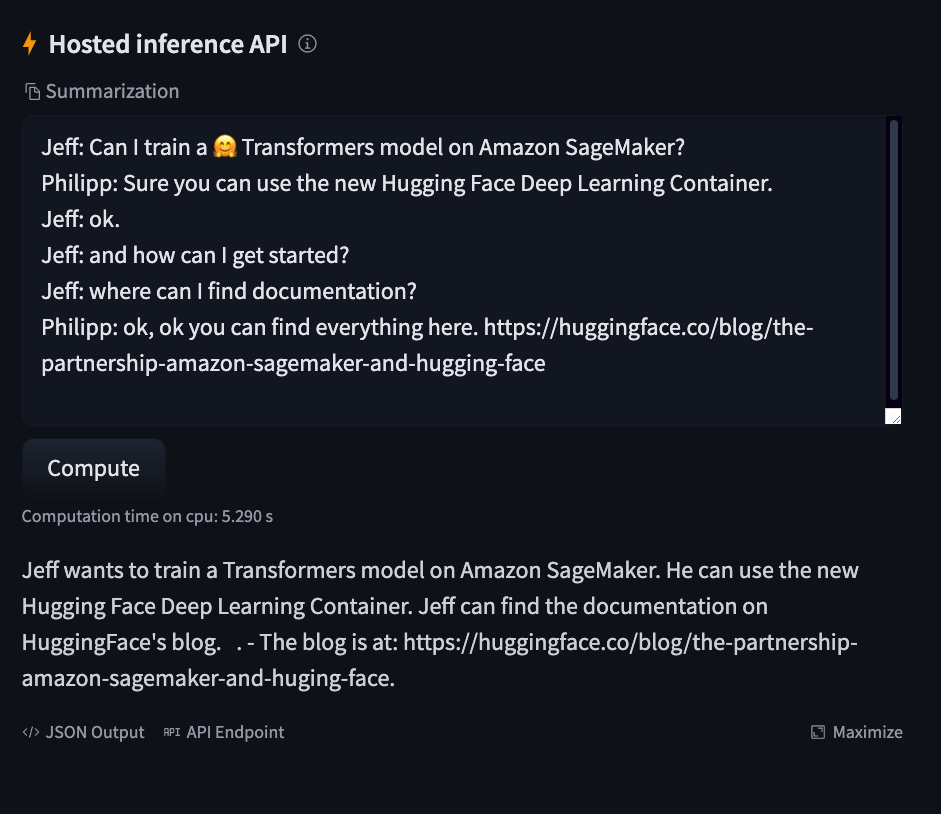
Jeff: Can I train a 🤗 Transformers model on Amazon SageMaker?
Philipp: Sure you can use the new Hugging Face Deep Learning Container.
Jeff: ok.
Jeff: and how can I get started?
Jeff: where can I find documentation?
Philipp: ok, ok you can find everything here. https://huggingface.co/blog/the-partnership-amazon-sagemaker-and-hugging-face
---
## `{model_name}`
This model was trained using Amazon SageMaker and the new Hugging Face Deep Learning container.
For more information look at:
- [🤗 Transformers Documentation: Amazon SageMaker](https://huggingface.co/transformers/sagemaker.html)
- [Example Notebooks](https://github.com/huggingface/notebooks/tree/master/sagemaker)
- [Amazon SageMaker documentation for Hugging Face](https://docs.aws.amazon.com/sagemaker/latest/dg/hugging-face.html)
- [Python SDK SageMaker documentation for Hugging Face](https://sagemaker.readthedocs.io/en/stable/frameworks/huggingface/index.html)
- [Deep Learning Container](https://github.com/aws/deep-learning-containers/blob/master/available_images.md#huggingface-training-containers)
## Hyperparameters
{hyperparameters}
## Usage
from transformers import pipeline
summarizer = pipeline("summarization", model="philschmid/{model_name}")
conversation = '''Jeff: Can I train a 🤗 Transformers model on Amazon SageMaker?
Philipp: Sure you can use the new Hugging Face Deep Learning Container.
Jeff: ok.
Jeff: and how can I get started?
Jeff: where can I find documentation?
Philipp: ok, ok you can find everything here. https://huggingface.co/blog/the-partnership-amazon-sagemaker-and-hugging-face
'''
nlp(conversation)
## Results
| key | value |
| --- | ----- |
{eval_table}
{test_table}
"""
# Generate model card (todo: add more data from Trainer)
model_card = MODEL_CARD_TEMPLATE.format(
model_name=f"{hyperparameters['model_name_or_path'].split('/')[1]}-{hyperparameters['dataset_name']}",
hyperparameters=json.dumps(hyperparameters, indent=4, sort_keys=True),
eval_table="\n".join(f"| {k} | {v} |" for k, v in eval_results.items()),
test_table="\n".join(f"| {k} | {v} |" for k, v in test_results.items()),
)
with open(f"{local_path}/README.md", "w") as f:
f.write(model_card)
將解壓縮後的模型和模型卡放在 my_bart_model 中後,我們可以使用 huggingface_hub SDK 建立一個儲存庫並將其上傳到 huggingface.co,或者直接到 https://huggingface.co/new 建立一個新的儲存庫並上傳。
from getpass import getpass
from huggingface_hub import HfApi, Repository
hf_username = "philschmid" # your username on huggingface.co
hf_email = "philipp@huggingface.co" # email used for commit
repository_name = f"{hyperparameters['model_name_or_path'].split('/')[1]}-{hyperparameters['dataset_name']}" # repository name on huggingface.co
password = getpass("Enter your password:") # creates a prompt for entering password
# get hf token
token = HfApi().login(username=hf_username, password=password)
# create repository
repo_url = HfApi().create_repo(token=token, name=repository_name, exist_ok=True)
# create a Repository instance
model_repo = Repository(use_auth_token=token,
clone_from=repo_url,
local_dir=local_path,
git_user=hf_username,
git_email=hf_email)
# push model to the hub
model_repo.push_to_hub()
測試推理
上傳模型後,我們可以透過 https://huggingface.co/{hf_username}/{repository_name} 訪問它。
print(f"https://huggingface.co/{hf_username}/{repository_name}")
並使用“託管推理 API”小部件進行測試。
https://huggingface.co/philschmid/bart-large-cnn-samsum