在英特爾 CPU 上加速 Stable Diffusion 推理




最近,我們介紹了最新一代的 英特爾至強 CPU(代號 Sapphire Rapids),及其用於深度學習加速的新硬體特性,以及如何使用它們來加速自然語言處理 Transformers 的分散式微調和推理。
在本文中,我們將向您展示在 Sapphire Rapids CPU 上加速 Stable Diffusion 模型的不同技術。後續文章將介紹分散式微調的類似內容。
在撰寫本文時,體驗 Sapphire Rapids 伺服器最簡單的方法是使用 Amazon EC2 R7iz 例項系列。由於它仍處於預覽階段,您必須註冊才能獲得訪問許可權。與之前的文章一樣,我使用的是 r7iz.metal-16xl 例項(64 vCPU,512GB RAM),並搭配 Ubuntu 20.04 AMI (ami-07cd3e6c4915b2d18)。
讓我們開始吧!程式碼示例可在 Gitlab 上獲取。
Diffusers 庫
Diffusers 庫使得使用 Stable Diffusion 模型生成影像變得極其簡單。如果您不熟悉這些模型,這裡有一篇很棒的圖文並茂的介紹。
首先,讓我們建立一個包含所需庫的虛擬環境:Transformers、Diffusers、Accelerate 和 PyTorch。
virtualenv sd_inference
source sd_inference/bin/activate
pip install pip --upgrade
pip install transformers diffusers accelerate torch==1.13.1
然後,我們編寫一個簡單的基準測試函式,該函式會重複執行推理,並返回單張影像生成的平均延遲。
import time
def elapsed_time(pipeline, prompt, nb_pass=10, num_inference_steps=20):
# warmup
images = pipeline(prompt, num_inference_steps=10).images
start = time.time()
for _ in range(nb_pass):
_ = pipeline(prompt, num_inference_steps=num_inference_steps, output_type="np")
end = time.time()
return (end - start) / nb_pass
現在,讓我們用預設的 float32 資料型別構建一個 StableDiffusionPipeline,並測量其推理延遲。
from diffusers import StableDiffusionPipeline
model_id = "runwayml/stable-diffusion-v1-5"
pipe = StableDiffusionPipeline.from_pretrained(model_id)
prompt = "sailing ship in storm by Rembrandt"
latency = elapsed_time(pipe, prompt)
print(latency)
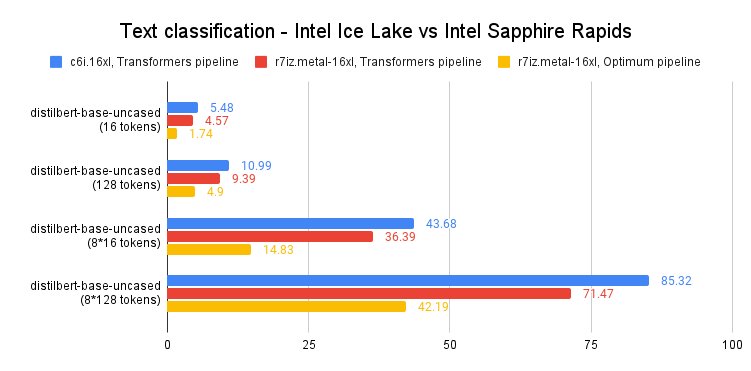
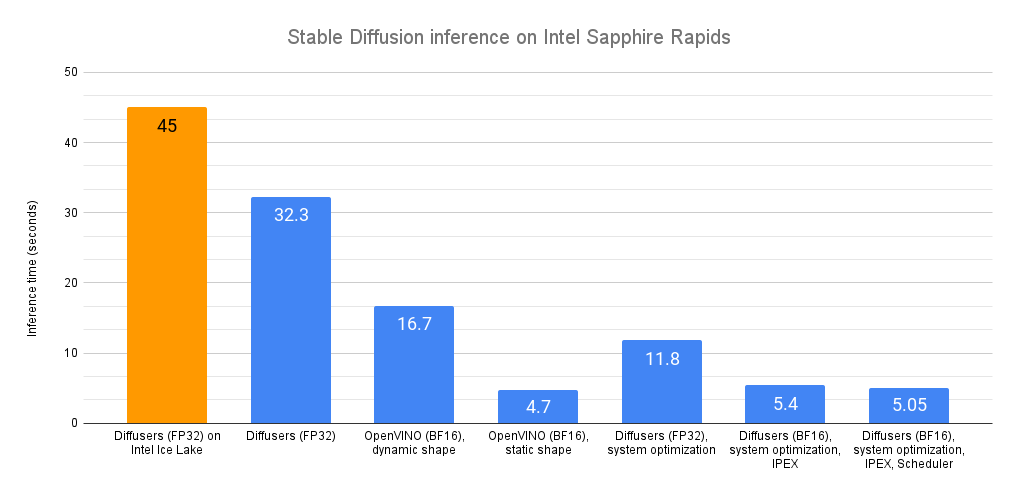
平均延遲為 32.3 秒。正如這個 Intel Space 所演示的,同樣的程式碼在上一代英特爾至強 CPU(代號 Ice Lake)上執行大約需要 45 秒。
開箱即用,我們可以看到,在沒有任何程式碼更改的情況下,Sapphire Rapids CPU 的速度要快得多!
現在,讓我們來加速吧!
Optimum Intel 與 OpenVINO
Optimum Intel 可在英特爾架構上加速端到端流水線。它的 API 與原生的 Diffusers API 極其相似,使得適配現有程式碼變得非常簡單。
Optimum Intel 支援 OpenVINO,這是一個用於高效能推理的英特爾開源工具套件。
Optimum Intel 和 OpenVINO 可以按如下方式安裝:
pip install optimum[openvino]
從上面的程式碼開始,我們只需要將 StableDiffusionPipeline 替換為 OVStableDiffusionPipeline。要載入 PyTorch 模型並將其即時轉換為 OpenVINO 格式,您可以在載入模型時設定 export=True。
from optimum.intel.openvino import OVStableDiffusionPipeline
...
ov_pipe = OVStableDiffusionPipeline.from_pretrained(model_id, export=True)
latency = elapsed_time(ov_pipe, prompt)
print(latency)
# Don't forget to save the exported model
ov_pipe.save_pretrained("./openvino")
OpenVINO 會自動為 bfloat16 格式最佳化模型。得益於此,平均延遲現在為 16.7 秒,實現了不錯的 2 倍加速。
上述流水線支援動態輸入形狀,對影像數量或其解析度沒有限制。對於 Stable Diffusion,您的應用程式通常僅限於一種(或幾種)不同的輸出解析度,例如 512x512 或 256x256。因此,透過將流水線重塑為固定解析度來解鎖顯著的加速是非常有意義的。如果您需要多種輸出解析度,可以簡單地維護幾個流水線例項,每種解析度一個。
ov_pipe.reshape(batch_size=1, height=512, width=512, num_images_per_prompt=1)
latency = elapsed_time(ov_pipe, prompt)
在靜態形狀下,平均延遲被削減至 4.7 秒,實現了額外的 3.5 倍加速。
如您所見,OpenVINO 是加速 Stable Diffusion 推理的一種簡單而高效的方法。當與 Sapphire Rapids CPU 結合使用時,與在 Ice Lake 至強 CPU 上的原生推理相比,它提供了近 10 倍的加速。
如果您不能或不想使用 OpenVINO,本文的其餘部分將向您展示一系列其他最佳化技術。請繫好安全帶!
系統級最佳化
Diffuser 模型是數 GB 大的模型,影像生成是記憶體密集型操作。透過安裝一個高效能的記憶體分配庫,我們應該能夠加速記憶體操作,並在至強核心之間並行化它們。請注意,這將更改您系統上的預設記憶體分配庫。當然,您可以透過解除安裝新庫來恢復到預設庫。
jemalloc 和 tcmalloc 同樣值得關注。在這裡,我安裝了 jemalloc,因為我的測試表明它有輕微的效能優勢。它還可以針對特定工作負載進行調整,例如最大化 CPU 利用率。您可以參考調優指南瞭解詳情。
sudo apt-get install -y libjemalloc-dev
export LD_PRELOAD=$LD_PRELOAD:/usr/lib/x86_64-linux-gnu/libjemalloc.so
export MALLOC_CONF="oversize_threshold:1,background_thread:true,metadata_thp:auto,dirty_decay_ms: 60000,muzzy_decay_ms:60000"
接下來,我們安裝 libiomp 庫以最佳化並行處理。它是 Intel OpenMP* 執行時 的一部分。
sudo apt-get install intel-mkl
export LD_PRELOAD=$LD_PRELOAD:/usr/lib/x86_64-linux-gnu/libiomp5.so
export OMP_NUM_THREADS=32
最後,我們安裝 numactl 命令列工具。這讓我們能夠將 Python 程序固定到特定的核心,並避免一些與上下文切換相關的開銷。
numactl -C 0-31 python sd_blog_1.py
得益於這些最佳化,我們最初的 Diffusers 程式碼現在的預測時間為 11.8 秒。這幾乎快了 3 倍,而且沒有任何程式碼更改。這些工具在我們的 32 核至強 CPU 上確實表現出色。
我們還遠未完成。讓我們將 Intel Extension for PyTorch 也加入進來。
IPEX 與 BF16
Intel Extension for Pytorch (IPEX) 擴充套件了 PyTorch,並利用了英特爾 CPU 上的硬體加速功能,例如 AVX-512 向量神經網路指令 (AVX512 VNNI) 和高階矩陣擴充套件 (AMX)。
讓我們安裝它。
pip install intel_extension_for_pytorch==1.13.100
然後我們更新程式碼,用 IPEX 最佳化每個流水線元素(您可以透過列印 pipe 物件來列出它們)。這需要將它們轉換為 channels-last 格式。
import torch
import intel_extension_for_pytorch as ipex
...
pipe = StableDiffusionPipeline.from_pretrained(model_id)
# to channels last
pipe.unet = pipe.unet.to(memory_format=torch.channels_last)
pipe.vae = pipe.vae.to(memory_format=torch.channels_last)
pipe.text_encoder = pipe.text_encoder.to(memory_format=torch.channels_last)
pipe.safety_checker = pipe.safety_checker.to(memory_format=torch.channels_last)
# Create random input to enable JIT compilation
sample = torch.randn(2,4,64,64)
timestep = torch.rand(1)*999
encoder_hidden_status = torch.randn(2,77,768)
input_example = (sample, timestep, encoder_hidden_status)
# optimize with IPEX
pipe.unet = ipex.optimize(pipe.unet.eval(), dtype=torch.bfloat16, inplace=True, sample_input=input_example)
pipe.vae = ipex.optimize(pipe.vae.eval(), dtype=torch.bfloat16, inplace=True)
pipe.text_encoder = ipex.optimize(pipe.text_encoder.eval(), dtype=torch.bfloat16, inplace=True)
pipe.safety_checker = ipex.optimize(pipe.safety_checker.eval(), dtype=torch.bfloat16, inplace=True)
我們還啟用了 bfloat16 資料格式,以利用 Sapphire Rapids CPU 上的 AMX 瓦片矩陣乘法單元 (TMMU) 加速器。
with torch.cpu.amp.autocast(enabled=True, dtype=torch.bfloat16):
latency = elapsed_time(pipe, prompt)
print(latency)
透過這個更新版本,推理延遲從 11.9 秒進一步減少到 5.4 秒。得益於 IPEX 和 AMX,這實現了超過 2 倍的加速。
我們還能榨取更多效能嗎?可以,用排程器!
排程器
Diffusers 庫允許我們為 Stable Diffusion 流水線附加一個排程器。排程器試圖在去噪速度和去噪質量之間找到最佳平衡。
根據文件:“在撰寫本文件時,DPMSolverMultistepScheduler 提供了可以說是最佳的速度/質量權衡,並且只需 20 個步驟即可執行。”
讓我們試試看。
from diffusers import StableDiffusionPipeline, DPMSolverMultistepScheduler
...
dpm = DPMSolverMultistepScheduler.from_pretrained(model_id, subfolder="scheduler")
pipe = StableDiffusionPipeline.from_pretrained(model_id, scheduler=dpm)
透過這個最終版本,推理延遲現在降至 5.05 秒。與我們最初的 Sapphire Rapids 基準(32.3 秒)相比,這幾乎快了 6.5 倍!
 *環境:Amazon EC2 r7iz.metal-16xl, Ubuntu 20.04, Linux 5.15.0-1031-aws, libjemalloc-dev 5.2.1-1, intel-mkl 2020.0.166-1, PyTorch 1.13.1, Intel Extension for PyTorch 1.13.1, transformers 4.27.2, diffusers 0.14, accelerate 0.17.1, openvino 2023.0.0.dev20230217, optimum 1.7.1, optimum-intel 1.7*
*環境:Amazon EC2 r7iz.metal-16xl, Ubuntu 20.04, Linux 5.15.0-1031-aws, libjemalloc-dev 5.2.1-1, intel-mkl 2020.0.166-1, PyTorch 1.13.1, Intel Extension for PyTorch 1.13.1, transformers 4.27.2, diffusers 0.14, accelerate 0.17.1, openvino 2023.0.0.dev20230217, optimum 1.7.1, optimum-intel 1.7*結論
在幾秒鐘內生成高質量影像的能力應該適用於許多用例,例如客戶應用、營銷和媒體內容生成,或用於資料集增強的合成數據。
以下是一些資源可幫助您入門:
- Diffusers 文件
- Optimum Intel 文件
- Intel IPEX 在 GitHub 上
- Intel 和 Hugging Face 提供的開發人員資源。
如果您有任何問題或反饋,我們非常樂意在 Hugging Face 論壇上閱讀。
感謝閱讀!