Transformers 文件
FastSpeech2Conformer
並獲得增強的文件體驗
開始使用
FastSpeech2Conformer
概述
FastSpeech2Conformer 模型是 Pengcheng Guo、Florian Boyer、Xuankai Chang、Tomoki Hayashi、Yosuke Higuchi、Hirofumi Inaguma、Naoyuki Kamo、Chenda Li、Daniel Garcia-Romero、Jiatong Shi、Jing Shi、Shinji Watanabe、Kun Wei、Wangyou Zhang 和 Yuekai Zhang 在論文 由 Conformer 推動的 Espnet 工具包的最新發展 中提出的。
原始 FastSpeech2 論文的摘要如下:
非自迴歸文字到語音 (TTS) 模型,如 FastSpeech (Ren et al., 2019),可以比以前的自迴歸模型更快地合成語音,同時保持可比的質量。FastSpeech 模型的訓練依賴於自迴歸教師模型進行時長預測(提供更多資訊作為輸入)和知識蒸餾(簡化輸出資料分佈),這可以緩解 TTS 中的一對多對映問題(即多個語音變體對應相同的文字)。然而,FastSpeech 有幾個缺點:1) 教師-學生蒸餾流程複雜且耗時,2) 從教師模型提取的時長不夠準確,以及從教師模型蒸餾的目標 Mel 譜圖由於資料簡化而遭受資訊損失,這兩者都限制了語音質量。在本文中,我們提出了 FastSpeech 2,它透過以下方式解決了 FastSpeech 中的問題並更好地解決了一對多對映問題:1) 直接使用真實目標而不是教師模型的簡化輸出來訓練模型,2) 引入更多語音變異資訊(例如音高、能量和更準確的時長)作為條件輸入。具體來說,我們從語音波形中提取時長、音高和能量,並在訓練中直接將其作為條件輸入,在推理中使用預測值。我們進一步設計了 FastSpeech 2s,這是首次嘗試並行地從文字直接生成語音波形,從而享受了完全端到端推理的優勢。實驗結果表明:1) FastSpeech 2 實現了比 FastSpeech 快 3 倍的訓練速度,FastSpeech 2s 甚至享有更快的推理速度;2) FastSpeech 2 和 2s 在語音質量上優於 FastSpeech,FastSpeech 2 甚至可以超越自迴歸模型。音訊樣本可在 https://speechresearch.github.io/fastspeech2/ 獲取。
該模型由 Connor Henderson 貢獻。原始程式碼可以在 此處 找到。
🤗 模型架構
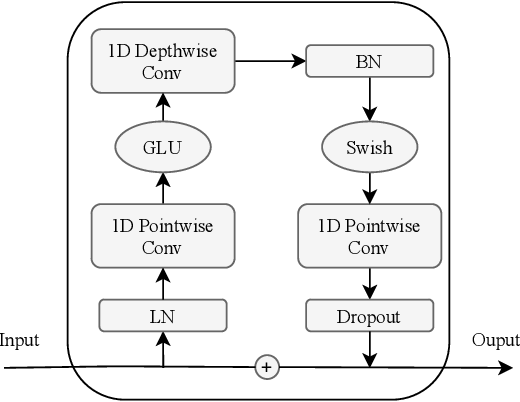
FastSpeech2 的通用結構與 Mel 譜圖解碼器相結合,並且傳統 Transformer 塊被 Conformer 塊取代,正如 ESPnet 庫中所示。
FastSpeech2 模型架構

Conformer 塊

卷積模組
🤗 Transformers 用法
您可以使用 🤗 Transformers 庫在本地執行 FastSpeech2Conformer。
- 首先安裝 🤗 Transformers 庫, g2p-en
pip install --upgrade pip pip install --upgrade transformers g2p-en
- 透過 Transformer 建模程式碼分別執行模型和 hifigan 的推理
from transformers import FastSpeech2ConformerTokenizer, FastSpeech2ConformerModel, FastSpeech2ConformerHifiGan
import soundfile as sf
tokenizer = FastSpeech2ConformerTokenizer.from_pretrained("espnet/fastspeech2_conformer")
inputs = tokenizer("Hello, my dog is cute.", return_tensors="pt")
input_ids = inputs["input_ids"]
model = FastSpeech2ConformerModel.from_pretrained("espnet/fastspeech2_conformer")
output_dict = model(input_ids, return_dict=True)
spectrogram = output_dict["spectrogram"]
hifigan = FastSpeech2ConformerHifiGan.from_pretrained("espnet/fastspeech2_conformer_hifigan")
waveform = hifigan(spectrogram)
sf.write("speech.wav", waveform.squeeze().detach().numpy(), samplerate=22050)- 透過 Transformer 建模程式碼執行模型和 hifigan 的組合推理
from transformers import FastSpeech2ConformerTokenizer, FastSpeech2ConformerWithHifiGan
import soundfile as sf
tokenizer = FastSpeech2ConformerTokenizer.from_pretrained("espnet/fastspeech2_conformer")
inputs = tokenizer("Hello, my dog is cute.", return_tensors="pt")
input_ids = inputs["input_ids"]
model = FastSpeech2ConformerWithHifiGan.from_pretrained("espnet/fastspeech2_conformer_with_hifigan")
output_dict = model(input_ids, return_dict=True)
waveform = output_dict["waveform"]
sf.write("speech.wav", waveform.squeeze().detach().numpy(), samplerate=22050)- 使用管道執行推理並指定要使用的聲碼器
from transformers import pipeline, FastSpeech2ConformerHifiGan
import soundfile as sf
vocoder = FastSpeech2ConformerHifiGan.from_pretrained("espnet/fastspeech2_conformer_hifigan")
synthesiser = pipeline(model="espnet/fastspeech2_conformer", vocoder=vocoder)
speech = synthesiser("Hello, my dog is cooler than you!")
sf.write("speech.wav", speech["audio"].squeeze(), samplerate=speech["sampling_rate"])FastSpeech2ConformerConfig
class transformers.FastSpeech2ConformerConfig
< 來源 >( hidden_size = 384 vocab_size = 78 num_mel_bins = 80 encoder_num_attention_heads = 2 encoder_layers = 4 encoder_linear_units = 1536 decoder_layers = 4 decoder_num_attention_heads = 2 decoder_linear_units = 1536 speech_decoder_postnet_layers = 5 speech_decoder_postnet_units = 256 speech_decoder_postnet_kernel = 5 positionwise_conv_kernel_size = 3 encoder_normalize_before = False decoder_normalize_before = False encoder_concat_after = False decoder_concat_after = False reduction_factor = 1 speaking_speed = 1.0 use_macaron_style_in_conformer = True use_cnn_in_conformer = True encoder_kernel_size = 7 decoder_kernel_size = 31 duration_predictor_layers = 2 duration_predictor_channels = 256 duration_predictor_kernel_size = 3 energy_predictor_layers = 2 energy_predictor_channels = 256 energy_predictor_kernel_size = 3 energy_predictor_dropout = 0.5 energy_embed_kernel_size = 1 energy_embed_dropout = 0.0 stop_gradient_from_energy_predictor = False pitch_predictor_layers = 5 pitch_predictor_channels = 256 pitch_predictor_kernel_size = 5 pitch_predictor_dropout = 0.5 pitch_embed_kernel_size = 1 pitch_embed_dropout = 0.0 stop_gradient_from_pitch_predictor = True encoder_dropout_rate = 0.2 encoder_positional_dropout_rate = 0.2 encoder_attention_dropout_rate = 0.2 decoder_dropout_rate = 0.2 decoder_positional_dropout_rate = 0.2 decoder_attention_dropout_rate = 0.2 duration_predictor_dropout_rate = 0.2 speech_decoder_postnet_dropout = 0.5 max_source_positions = 5000 use_masking = True use_weighted_masking = False num_speakers = None num_languages = None speaker_embed_dim = None is_encoder_decoder = True **kwargs )
引數
- hidden_size (
int, 可選, 預設為 384) — 隱藏層維度。 - vocab_size (
int, 可選, 預設為 78) — 詞彙表大小。 - num_mel_bins (
int, 可選, 預設為 80) — 濾波器組中使用的 Mel 濾波器數量。 - encoder_num_attention_heads (
int, 可選, 預設為 2) — 編碼器中的注意力頭數量。 - encoder_layers (
int, 可選, 預設為 4) — 編碼器中的層數。 - encoder_linear_units (
int, 可選, 預設為 1536) — 編碼器線性層中的單元數量。 - decoder_layers (
int, 可選, 預設為 4) — 解碼器中的層數。 - decoder_num_attention_heads (
int, 可選, 預設為 2) — 解碼器中的注意力頭數量。 - decoder_linear_units (
int, 可選, 預設為 1536) — 解碼器線性層中的單元數量。 - speech_decoder_postnet_layers (
int, 可選, 預設為 5) — 語音解碼器後處理網路中的層數。 - speech_decoder_postnet_units (
int, 可選, 預設為 256) — 語音解碼器後處理網路層中的單元數量。 - speech_decoder_postnet_kernel (
int, 可選, 預設為 5) — 語音解碼器後處理網路中的核大小。 - positionwise_conv_kernel_size (
int, 可選, 預設為 3) — 位置感知層中使用的卷積核大小。 - encoder_normalize_before (
bool, 可選, 預設為False) — 指定是否在編碼器層之前進行歸一化。 - decoder_normalize_before (
bool, 可選, 預設為False) — 指定是否在解碼器層之前進行歸一化。 - encoder_concat_after (
bool, 可選, 預設為False) — 指定是否在編碼器層之後進行連線。 - decoder_concat_after (
bool, 可選, 預設為False) — 指定是否在解碼器層之後進行連線。 - reduction_factor (
int, 可選, 預設為 1) — 語音幀速率的縮減因子。 - speaking_speed (
float, 可選, 預設為 1.0) — 生成語音的速度。 - use_macaron_style_in_conformer (
bool, 可選, 預設為True) — 指定是否在 conformer 中使用馬卡龍風格。 - use_cnn_in_conformer (
bool, 可選, 預設為True) — 指定是否在 conformer 中使用卷積神經網路。 - encoder_kernel_size (
int, 可選, 預設為 7) — 編碼器中使用的核大小。 - decoder_kernel_size (
int, 可選, 預設為 31) — 解碼器中使用的核大小。 - duration_predictor_layers (
int, 可選, 預設為 2) — 時長預測器中的層數。 - duration_predictor_channels (
int, 可選, 預設為 256) — 時長預測器中的通道數量。 - duration_predictor_kernel_size (
int, 可選, 預設為 3) — 時長預測器中使用的核大小。 - energy_predictor_layers (
int, 可選, 預設為 2) — 能量預測器中的層數。 - energy_predictor_channels (
int, 可選, 預設為 256) — 能量預測器中的通道數量。 - energy_predictor_kernel_size (
int, 可選, 預設為 3) — 能量預測器中使用的核大小。 - energy_predictor_dropout (
float, 可選, 預設為 0.5) — 能量預測器中的 dropout 率。 - energy_embed_kernel_size (
int, 可選, 預設為 1) — 能量嵌入層中使用的核大小。 - energy_embed_dropout (
float, 可選, 預設為 0.0) — 能量嵌入層中的 dropout 率。 - stop_gradient_from_energy_predictor (
bool, 可選, 預設為False) — 指定是否阻止能量預測器的梯度。 - pitch_predictor_layers (
int, 可選, 預設為 5) — 音高預測器中的層數。 - pitch_predictor_channels (
int, 可選, 預設為 256) — 音高預測器中的通道數量。 - pitch_predictor_kernel_size (
int, 可選, 預設為 5) — 音高預測器中使用的核大小。 - pitch_predictor_dropout (
float, optional, 預設為 0.5) — 音高預測器中的 dropout 率。 - pitch_embed_kernel_size (
int, optional, 預設為 1) — 音高嵌入層中使用的核大小。 - pitch_embed_dropout (
float, optional, 預設為 0.0) — 音高嵌入層中的 dropout 率。 - stop_gradient_from_pitch_predictor (
bool, optional, 預設為True) — 指定是否停止音高預測器的梯度。 - encoder_dropout_rate (
float, optional, 預設為 0.2) — 編碼器中的 dropout 率。 - encoder_positional_dropout_rate (
float, optional, 預設為 0.2) — 編碼器中的位置 dropout 率。 - encoder_attention_dropout_rate (
float, optional, 預設為 0.2) — 編碼器中的注意力 dropout 率。 - decoder_dropout_rate (
float, optional, 預設為 0.2) — 解碼器中的 dropout 率。 - decoder_positional_dropout_rate (
float, optional, 預設為 0.2) — 解碼器中的位置 dropout 率。 - decoder_attention_dropout_rate (
float, optional, 預設為 0.2) — 解碼器中的注意力 dropout 率。 - duration_predictor_dropout_rate (
float, optional, 預設為 0.2) — 時長預測器中的 dropout 率。 - speech_decoder_postnet_dropout (
float, optional, 預設為 0.5) — 語音解碼器 postnet 中的 dropout 率。 - max_source_positions (
int, optional, 預設為 5000) — 如果使用"relative"位置嵌入,定義最大源輸入位置。 - use_masking (
bool, optional, 預設為True) — 指定是否在模型中使用掩碼。 - use_weighted_masking (
bool, optional, 預設為False) — 指定是否在模型中使用加權掩碼。 - num_speakers (
int, optional) — 說話人數量。如果設定為 > 1,則假定說話人 ID 將作為輸入提供,並使用說話人 ID 嵌入層。 - num_languages (
int, optional) — 語言數量。如果設定為 > 1,則假定語言 ID 將作為輸入提供,並使用語言 ID 嵌入層。 - speaker_embed_dim (
int, optional) — 說話人嵌入維度。如果設定為 > 0,則假定 speaker_embedding 將作為輸入提供。 - is_encoder_decoder (
bool, optional, 預設為True) — 指定模型是否為編碼器-解碼器。
這是用於儲存 FastSpeech2ConformerModel 配置的配置類。它用於根據指定的引數例項化 FastSpeech2Conformer 模型,定義模型架構。使用預設值例項化配置將產生與 FastSpeech2Conformer espnet/fastspeech2_conformer 架構類似的配置。
配置物件繼承自 PretrainedConfig,可用於控制模型輸出。有關更多資訊,請參閱 PretrainedConfig 的文件。
示例
>>> from transformers import FastSpeech2ConformerModel, FastSpeech2ConformerConfig
>>> # Initializing a FastSpeech2Conformer style configuration
>>> configuration = FastSpeech2ConformerConfig()
>>> # Initializing a model from the FastSpeech2Conformer style configuration
>>> model = FastSpeech2ConformerModel(configuration)
>>> # Accessing the model configuration
>>> configuration = model.configFastSpeech2ConformerHifiGanConfig
class transformers.FastSpeech2ConformerHifiGanConfig
< source >( model_in_dim = 80 upsample_initial_channel = 512 upsample_rates = [8, 8, 2, 2] upsample_kernel_sizes = [16, 16, 4, 4] resblock_kernel_sizes = [3, 7, 11] resblock_dilation_sizes = [[1, 3, 5], [1, 3, 5], [1, 3, 5]] initializer_range = 0.01 leaky_relu_slope = 0.1 normalize_before = True **kwargs )
引數
- model_in_dim (
int, optional, 預設為 80) — 輸入 log-mel 語譜圖中的頻率 bin 數量。 - upsample_initial_channel (
int, optional, 預設為 512) — 上取樣網路中的輸入通道數量。 - upsample_rates (
tuple[int]或list[int], optional, 預設為[8, 8, 2, 2]) — 定義上取樣網路中每個一維卷積層的步幅的整數元組。upsample_rates 的長度定義了卷積層的數量,並且必須與 upsample_kernel_sizes 的長度匹配。 - upsample_kernel_sizes (
tuple[int]或list[int], optional, 預設為[16, 16, 4, 4]) — 定義上取樣網路中每個一維卷積層的核大小的整數元組。upsample_kernel_sizes 的長度定義了卷積層的數量,並且必須與 upsample_rates 的長度匹配。 - resblock_kernel_sizes (
tuple[int]或list[int], optional, 預設為[3, 7, 11]) — 定義多感受野融合 (MRF) 模組中一維卷積層核大小的整數元組。 - resblock_dilation_sizes (
tuple[tuple[int]]或list[list[int]], optional, 預設為[[1, 3, 5], [1, 3, 5], [1, 3, 5]]) — 定義多感受野融合 (MRF) 模組中膨脹一維卷積層膨脹率的巢狀整數元組。 - initializer_range (
float, optional, 預設為 0.01) — 用於初始化所有權重矩陣的 truncated_normal_initializer 的標準差。 - leaky_relu_slope (
float, optional, 預設為 0.1) — Leaky ReLU 啟用函式使用的負斜率角度。 - normalize_before (
bool, optional, 預設為True) — 是否在使用聲碼器學習到的均值和方差對聲譜圖進行歸一化。
這是用於儲存 FastSpeech2ConformerHifiGanModel 配置的配置類。它用於根據指定的引數例項化 FastSpeech2Conformer HiFi-GAN 聲碼器模型,定義模型架構。使用預設值例項化配置將產生與 FastSpeech2Conformer espnet/fastspeech2_conformer_hifigan 架構類似的配置。
配置物件繼承自 PretrainedConfig,可用於控制模型輸出。有關更多資訊,請參閱 PretrainedConfig 的文件。
示例
>>> from transformers import FastSpeech2ConformerHifiGan, FastSpeech2ConformerHifiGanConfig
>>> # Initializing a FastSpeech2ConformerHifiGan configuration
>>> configuration = FastSpeech2ConformerHifiGanConfig()
>>> # Initializing a model (with random weights) from the configuration
>>> model = FastSpeech2ConformerHifiGan(configuration)
>>> # Accessing the model configuration
>>> configuration = model.configFastSpeech2ConformerWithHifiGanConfig
class transformers.FastSpeech2ConformerWithHifiGanConfig
< source >( model_config: typing.Optional[dict] = None vocoder_config: typing.Optional[dict] = None **kwargs )
這是用於儲存 FastSpeech2ConformerWithHifiGan 配置的配置類。它用於根據指定的子模型配置例項化 FastSpeech2ConformerWithHifiGanModel 模型,定義模型架構。
使用預設值例項化配置將產生與 FastSpeech2ConformerModel espnet/fastspeech2_conformer 和 FastSpeech2ConformerHifiGan espnet/fastspeech2_conformer_hifigan 架構類似的配置。
配置物件繼承自 PretrainedConfig,可用於控制模型輸出。有關更多資訊,請參閱 PretrainedConfig 的文件。
model_config (FastSpeech2ConformerConfig, optional): 文字轉語音模型的配置。vocoder_config (FastSpeech2ConformerHiFiGanConfig, optional): 聲碼器模型的配置。
示例
>>> from transformers import (
... FastSpeech2ConformerConfig,
... FastSpeech2ConformerHifiGanConfig,
... FastSpeech2ConformerWithHifiGanConfig,
... FastSpeech2ConformerWithHifiGan,
... )
>>> # Initializing FastSpeech2ConformerWithHifiGan sub-modules configurations.
>>> model_config = FastSpeech2ConformerConfig()
>>> vocoder_config = FastSpeech2ConformerHifiGanConfig()
>>> # Initializing a FastSpeech2ConformerWithHifiGan module style configuration
>>> configuration = FastSpeech2ConformerWithHifiGanConfig(model_config.to_dict(), vocoder_config.to_dict())
>>> # Initializing a model (with random weights)
>>> model = FastSpeech2ConformerWithHifiGan(configuration)
>>> # Accessing the model configuration
>>> configuration = model.configFastSpeech2ConformerTokenizer
class transformers.FastSpeech2ConformerTokenizer
< source >( vocab_file bos_token = '<sos/eos>' eos_token = '<sos/eos>' pad_token = '<blank>' unk_token = '<unk>' should_strip_spaces = False **kwargs )
引數
- vocab_file (
str) — 詞彙表文件的路徑。 - bos_token (
str, optional, 預設為"<sos/eos>") — 序列開始標記。請注意,對於 FastSpeech2,它與eos_token相同。 - eos_token (
str, optional, 預設為"<sos/eos>") — 序列結束標記。請注意,對於 FastSpeech2,它與bos_token相同。 - pad_token (
str, optional, 預設為"<blank>") — 用於填充的標記,例如在批處理不同長度的序列時。 - unk_token (
str, optional, 預設為"<unk>") — 未知標記。不在詞彙表中的標記不能轉換為 ID,而是設定為此標記。 - should_strip_spaces (
bool, optional, 預設為False) — 是否從標記列表中去除空格。
構建 FastSpeech2Conformer 分詞器。
__call__
< source >( text: typing.Union[str, list[str], list[list[str]], NoneType] = None text_pair: typing.Union[str, list[str], list[list[str]], NoneType] = None text_target: typing.Union[str, list[str], list[list[str]], NoneType] = None text_pair_target: typing.Union[str, list[str], list[list[str]], NoneType] = None add_special_tokens: bool = True padding: typing.Union[bool, str, transformers.utils.generic.PaddingStrategy] = False truncation: typing.Union[bool, str, transformers.tokenization_utils_base.TruncationStrategy, NoneType] = None max_length: typing.Optional[int] = None stride: int = 0 is_split_into_words: bool = False pad_to_multiple_of: typing.Optional[int] = None padding_side: typing.Optional[str] = None return_tensors: typing.Union[str, transformers.utils.generic.TensorType, NoneType] = None return_token_type_ids: typing.Optional[bool] = None return_attention_mask: typing.Optional[bool] = None return_overflowing_tokens: bool = False return_special_tokens_mask: bool = False return_offsets_mapping: bool = False return_length: bool = False verbose: bool = True **kwargs → BatchEncoding
引數
- text (
str,list[str],list[list[str]], optional) — 要編碼的序列或序列批次。每個序列可以是字串或字串列表(預分詞字串)。如果序列以字串列表(預分詞)形式提供,則必須設定is_split_into_words=True(以消除與序列批次的歧義)。 - text_pair (
str,list[str],list[list[str]], optional) — 要編碼的序列或序列批次。每個序列可以是字串或字串列表(預分詞字串)。如果序列以字串列表(預分詞)形式提供,則必須設定is_split_into_words=True(以消除與序列批次的歧義)。 - text_target (
str,list[str],list[list[str]], optional) — 要作為目標文字編碼的序列或序列批次。每個序列可以是字串或字串列表(預分詞字串)。如果序列以字串列表(預分詞)形式提供,則必須設定is_split_into_words=True(以消除與序列批次的歧義)。 - text_pair_target (
str,list[str],list[list[str]], optional) — 要作為目標文字編碼的序列或序列批次。每個序列可以是字串或字串列表(預分詞字串)。如果序列以字串列表(預分詞)形式提供,則必須設定is_split_into_words=True(以消除與序列批次的歧義)。 - add_special_tokens (
bool, optional, 預設為True) — 編碼序列時是否新增特殊標記。這將使用底層PretrainedTokenizerBase.build_inputs_with_special_tokens函式,該函式定義哪些標記會自動新增到輸入 ID。如果您想自動新增bos或eos標記,這會很有用。 - padding (
bool,str或 PaddingStrategy, optional, 預設為False) — 啟用並控制填充。接受以下值:True或'longest':填充到批次中最長的序列(如果只提供一個序列,則不填充)。'max_length':填充到由引數max_length指定的最大長度,如果未提供該引數,則填充到模型可接受的最大輸入長度。False或'do_not_pad'(預設):不填充(即,可以輸出包含不同長度序列的批次)。
- truncation (
bool,str或 TruncationStrategy, 可選, 預設為False) — 啟用並控制截斷。接受以下值:True或'longest_first':截斷到由引數max_length指定的最大長度,如果未提供該引數,則截斷到模型可接受的最大輸入長度。這將逐個截斷標記,如果提供了一對序列(或一批對),則從最長序列中移除一個標記。'only_first':截斷到由引數max_length指定的最大長度,如果未提供該引數,則截斷到模型可接受的最大輸入長度。如果提供了一對序列(或一批對),這將僅截斷一對中的第一個序列。'only_second':截斷到由引數max_length指定的最大長度,如果未提供該引數,則截斷到模型可接受的最大輸入長度。如果提供了一對序列(或一批對),這將僅截斷一對中的第二個序列。False或'do_not_truncate'(預設):不進行截斷(即,可以輸出序列長度大於模型最大允許輸入大小的批次)。
- max_length (
int, 可選) — 控制截斷/填充引數使用的最大長度。如果未設定或設定為
None,則如果截斷/填充引數需要最大長度,將使用預定義的模型最大長度。如果模型沒有特定的最大輸入長度(如 XLNet),則最大長度的截斷/填充將被停用。 - stride (
int, 可選, 預設為 0) — 如果與max_length一起設定為一個數字,當return_overflowing_tokens=True時返回的溢位標記將包含截斷序列末尾的一些標記,以在截斷序列和溢位序列之間提供一些重疊。此引數的值定義了重疊標記的數量。 - is_split_into_words (
bool, 可選, 預設為False) — 輸入是否已預先分詞(例如,按單詞分割)。如果設定為True,分詞器假定輸入已按單詞分割(例如,透過在空白處分割),然後它將對其進行分詞。這對於 NER 或標記分類很有用。 - pad_to_multiple_of (
int, 可選) — 如果設定,將序列填充到所提供值的倍數。需要啟用padding。這對於在計算能力>= 7.5(Volta) 的 NVIDIA 硬體上使用 Tensor Cores 特別有用。 - padding_side (
str, 可選) — 模型應在其上應用填充的側面。應在 ['right', 'left'] 之間選擇。預設值從同名的類屬性中選取。 - return_tensors (
str或 TensorType, 可選) — 如果設定,將返回張量而不是 Python 整數列表。可接受的值為:'tf':返回 TensorFlowtf.constant物件。'pt':返回 PyTorchtorch.Tensor物件。'np':返回 Numpynp.ndarray物件。
- return_token_type_ids (
bool, 可選) — 是否返回標記型別 ID。如果保留預設值,將根據特定分詞器的預設值(由return_outputs屬性定義)返回標記型別 ID。 - return_attention_mask (
bool, 可選) — 是否返回注意力掩碼。如果保留預設值,將根據特定分詞器的預設值(由return_outputs屬性定義)返回注意力掩碼。 - return_overflowing_tokens (
bool, 可選, 預設為False) — 是否返回溢位標記序列。如果提供了輸入 ID 的一對序列(或一批對),並且truncation_strategy = longest_first或True,則會引發錯誤而不是返回溢位標記。 - return_special_tokens_mask (
bool, 可選, 預設為False) — 是否返回特殊標記掩碼資訊。 - return_offsets_mapping (
bool, 可選, 預設為False) — 是否為每個標記返回(char_start, char_end)。這僅在繼承自 PreTrainedTokenizerFast 的快速分詞器上可用,如果使用 Python 的分詞器,此方法將引發
NotImplementedError。 - return_length (
bool, 可選, 預設為False) — 是否返回編碼輸入的長度。 - verbose (
bool, 可選, 預設為True) — 是否列印更多資訊和警告。 - **kwargs — 傳遞給
self.tokenize()方法
一個 BatchEncoding,包含以下欄位:
-
input_ids — 要輸入到模型中的標記 ID 列表。
-
token_type_ids — 要輸入到模型中的標記型別 ID 列表(當
return_token_type_ids=True或如果 *“token_type_ids”* 在self.model_input_names中時)。 -
attention_mask — 指定模型應關注哪些標記的索引列表(當
return_attention_mask=True或如果 *“attention_mask”* 在self.model_input_names中時)。 -
overflowing_tokens — 溢位標記序列列表(當指定
max_length且return_overflowing_tokens=True時)。 -
num_truncated_tokens — 截斷標記的數量(當指定
max_length且return_overflowing_tokens=True時)。 -
special_tokens_mask — 0 和 1 的列表,其中 1 表示新增的特殊標記,0 表示常規序列標記(當
add_special_tokens=True且return_special_tokens_mask=True時)。 -
length — 輸入的長度(當
return_length=True時)
將一個或多個序列或一對或多對序列標記化並準備用於模型的主要方法。
save_vocabulary
< 源 >( save_directory: str filename_prefix: typing.Optional[str] = None ) → Tuple(str)
將詞彙表和特殊標記檔案儲存到目錄。
batch_decode
< 源 >( sequences: typing.Union[list[int], list[list[int]], ForwardRef('np.ndarray'), ForwardRef('torch.Tensor'), ForwardRef('tf.Tensor')] skip_special_tokens: bool = False clean_up_tokenization_spaces: typing.Optional[bool] = None **kwargs ) → list[str]
引數
- sequences (
Union[list[int], list[list[int]], np.ndarray, torch.Tensor, tf.Tensor]) — 標記化的輸入 ID 列表。可以使用__call__方法獲取。 - skip_special_tokens (
bool, 可選, 預設為False) — 解碼時是否刪除特殊標記。 - clean_up_tokenization_spaces (
bool, 可選) — 是否清理分詞空間。如果為None,將預設為self.clean_up_tokenization_spaces。 - kwargs (附加關鍵字引數, 可選) — 將傳遞給底層模型特定的解碼方法。
返回
list[str]
解碼後的句子列表。
透過呼叫 decode 將標記 ID 列表的列表轉換為字串列表。
FastSpeech2ConformerModel
class transformers.FastSpeech2ConformerModel
< 源 >( config: FastSpeech2ConformerConfig )
引數
- config (FastSpeech2ConformerConfig) — 模型配置類,包含模型的所有引數。使用配置檔案初始化不載入與模型相關的權重,只加載配置。請檢視 from_pretrained() 方法載入模型權重。
FastSpeech2Conformer 模型。
此模型繼承自 PreTrainedModel。請檢視超類文件,瞭解庫為其所有模型實現的一般方法(例如下載或儲存、調整輸入嵌入大小、修剪頭部等)。
此模型也是 PyTorch torch.nn.Module 子類。將其作為常規 PyTorch 模組使用,並參考 PyTorch 文件瞭解所有與一般用法和行為相關的事項。
forward
< 源 >( input_ids: LongTensor attention_mask: typing.Optional[torch.LongTensor] = None spectrogram_labels: typing.Optional[torch.FloatTensor] = None duration_labels: typing.Optional[torch.LongTensor] = None pitch_labels: typing.Optional[torch.FloatTensor] = None energy_labels: typing.Optional[torch.FloatTensor] = None speaker_ids: typing.Optional[torch.LongTensor] = None lang_ids: typing.Optional[torch.LongTensor] = None speaker_embedding: typing.Optional[torch.FloatTensor] = None return_dict: typing.Optional[bool] = None output_attentions: typing.Optional[bool] = None output_hidden_states: typing.Optional[bool] = None ) → transformers.models.fastspeech2_conformer.modeling_fastspeech2_conformer.FastSpeech2ConformerModelOutput 或 tuple(torch.FloatTensor)
引數
- input_ids (形狀為
(batch_size, sequence_length)的torch.LongTensor) — 文字向量的輸入序列。 - attention_mask (形狀為
(batch_size, sequence_length)的torch.LongTensor, 可選) — 避免對填充標記索引執行注意力操作的掩碼。掩碼值選擇在[0, 1]之間:- 1 表示 未被掩碼 的標記,
- 0 表示 被掩碼 的標記。
- spectrogram_labels (形狀為
(batch_size, max_spectrogram_length, num_mel_bins)的torch.FloatTensor, 可選, 預設為None) — 填充的目標特徵批次。 - duration_labels (形狀為
(batch_size, sequence_length + 1)的torch.LongTensor, 可選, 預設為None) — 填充的持續時間批次。 - pitch_labels (形狀為
(batch_size, sequence_length + 1, 1)的torch.FloatTensor, 可選, 預設為None) — 填充的按標記平均的音高批次。 - energy_labels (形狀為
(batch_size, sequence_length + 1, 1)的torch.FloatTensor, 可選, 預設為None) — 填充的按標記平均的能量批次。 - speaker_ids (形狀為
(batch_size, 1)的torch.LongTensor, 可選, 預設為None) — 用於透過模型調節語音輸出特徵的說話人 ID。 - lang_ids (形狀為
(batch_size, 1)的torch.LongTensor, 可選, 預設為None) — 用於透過模型調節語音輸出特徵的語言 ID。 - speaker_embedding (形狀為
(batch_size, embedding_dim)的torch.FloatTensor, 可選, 預設為None) — 包含語音特徵調節訊號的嵌入。 - return_dict (
bool, 可選) — 是否返回 ModelOutput 而不是純元組。 - output_attentions (
bool, 可選) — 是否返回所有注意力層的注意力張量。有關更多詳細資訊,請參閱返回張量下的attentions。 - output_hidden_states (
bool, 可選) — 是否返回所有層的隱藏狀態。有關更多詳細資訊,請參閱返回張量下的hidden_states。
返回
transformers.models.fastspeech2_conformer.modeling_fastspeech2_conformer.FastSpeech2ConformerModelOutput 或 tuple(torch.FloatTensor)
一個 transformers.models.fastspeech2_conformer.modeling_fastspeech2_conformer.FastSpeech2ConformerModelOutput 或一個 torch.FloatTensor 元組(如果傳遞 return_dict=False 或當 config.return_dict=False 時),包含根據配置 (FastSpeech2ConformerConfig) 和輸入的不同元素。
-
loss (形狀為
(1,)的torch.FloatTensor, 可選, 提供labels時返回) — 頻譜圖生成損失。 -
spectrogram (形狀為
(batch_size, sequence_length, num_bins)的torch.FloatTensor, 可選, 預設為None) — 預測的頻譜圖。 -
encoder_last_hidden_state (形狀為
(batch_size, sequence_length, hidden_size)的torch.FloatTensor, 可選, 預設為None) — 模型編碼器最後一層輸出的隱藏狀態序列。 -
encoder_hidden_states (
tuple[torch.FloatTensor], 可選, 傳遞output_hidden_states=True或當config.output_hidden_states=True時返回) — 形狀為(batch_size, sequence_length, hidden_size)的torch.FloatTensor元組(一個用於嵌入層輸出,如果模型有嵌入層,+一個用於每層輸出)。編碼器在每一層輸出時的隱藏狀態以及初始嵌入輸出。
-
encoder_attentions (
tuple[torch.FloatTensor], 可選, 傳遞output_attentions=True或當config.output_attentions=True時返回) — 形狀為(batch_size, num_heads, sequence_length, sequence_length)的torch.FloatTensor元組(每層一個)。編碼器的注意力權重,在注意力 softmax 之後,用於計算自注意力頭中的加權平均。
-
decoder_hidden_states (
tuple[torch.FloatTensor], 可選, 傳遞output_hidden_states=True或當config.output_hidden_states=True時返回) — 形狀為(batch_size, sequence_length, hidden_size)的torch.FloatTensor元組(一個用於嵌入層輸出,如果模型有嵌入層,+一個用於每層輸出)。解碼器在每一層輸出時的隱藏狀態以及初始嵌入輸出。
-
decoder_attentions (
tuple[torch.FloatTensor], 可選, 傳遞output_attentions=True或當config.output_attentions=True時返回) — 形狀為(batch_size, num_heads, sequence_length, sequence_length)的torch.FloatTensor元組(每層一個)。解碼器的注意力權重,在注意力 softmax 之後,用於計算自注意力頭中的加權平均。
-
duration_outputs (形狀為
(batch_size, max_text_length + 1)的torch.LongTensor, 可選) — 持續時間預測器的輸出。 -
pitch_outputs (形狀為
(batch_size, max_text_length + 1, 1)的torch.FloatTensor, 可選) — 音高預測器的輸出。 -
energy_outputs (形狀為
(batch_size, max_text_length + 1, 1)的torch.FloatTensor, 可選) — 能量預測器的輸出。
FastSpeech2ConformerModel 的 forward 方法,覆蓋了 __call__ 特殊方法。
儘管前向傳播的配方需要在該函式內定義,但之後應呼叫 Module 例項,而不是此函式,因為前者負責執行預處理和後處理步驟,而後者則默默忽略它們。
示例
>>> from transformers import (
... FastSpeech2ConformerTokenizer,
... FastSpeech2ConformerModel,
... FastSpeech2ConformerHifiGan,
... )
>>> tokenizer = FastSpeech2ConformerTokenizer.from_pretrained("espnet/fastspeech2_conformer")
>>> inputs = tokenizer("some text to convert to speech", return_tensors="pt")
>>> input_ids = inputs["input_ids"]
>>> model = FastSpeech2ConformerModel.from_pretrained("espnet/fastspeech2_conformer")
>>> output_dict = model(input_ids, return_dict=True)
>>> spectrogram = output_dict["spectrogram"]
>>> vocoder = FastSpeech2ConformerHifiGan.from_pretrained("espnet/fastspeech2_conformer_hifigan")
>>> waveform = vocoder(spectrogram)
>>> print(waveform.shape)
torch.Size([1, 49664])FastSpeech2ConformerHifiGan
class transformers.FastSpeech2ConformerHifiGan
< 源 >( config: FastSpeech2ConformerHifiGanConfig )
引數
- config (FastSpeech2ConformerHifiGanConfig) — 模型配置類,包含模型的所有引數。使用配置檔案初始化不載入與模型相關的權重,只加載配置。請檢視 from_pretrained() 方法載入模型權重。
HiFi-GAN 聲碼器。
此模型繼承自 PreTrainedModel。請檢視超類文件,瞭解庫為其所有模型實現的一般方法(例如下載或儲存、調整輸入嵌入大小、修剪頭部等)。
此模型也是 PyTorch torch.nn.Module 子類。將其作為常規 PyTorch 模組使用,並參考 PyTorch 文件瞭解所有與一般用法和行為相關的事項。
forward
< 源 >( spectrogram: FloatTensor **kwargs ) → torch.FloatTensor
將對數梅爾譜圖轉換為語音波形。傳遞一批對數梅爾譜圖將返回一批語音波形。傳遞單個未批處理的對數梅爾譜圖將返回單個未批處理的語音波形。
FastSpeech2ConformerWithHifiGan
class transformers.FastSpeech2ConformerWithHifiGan
< source >( config: FastSpeech2ConformerWithHifiGanConfig )
引數
- config (FastSpeech2ConformerWithHifiGanConfig) — 模型配置類,包含模型的所有引數。用配置檔案初始化並不會載入與模型相關的權重,只加載配置。請檢視 from_pretrained() 方法載入模型權重。
帶有 FastSpeech2ConformerHifiGan 聲碼器頭的 FastSpeech2ConformerModel,用於執行文字到語音(波形)轉換。
此模型繼承自 PreTrainedModel。請檢視超類文件,瞭解庫為其所有模型實現的一般方法(例如下載或儲存、調整輸入嵌入大小、修剪頭部等)。
此模型也是 PyTorch torch.nn.Module 子類。將其作為常規 PyTorch 模組使用,並參考 PyTorch 文件瞭解所有與一般用法和行為相關的事項。
forward
< source >( input_ids: LongTensor attention_mask: typing.Optional[torch.LongTensor] = None spectrogram_labels: typing.Optional[torch.FloatTensor] = None duration_labels: typing.Optional[torch.LongTensor] = None pitch_labels: typing.Optional[torch.FloatTensor] = None energy_labels: typing.Optional[torch.FloatTensor] = None speaker_ids: typing.Optional[torch.LongTensor] = None lang_ids: typing.Optional[torch.LongTensor] = None speaker_embedding: typing.Optional[torch.FloatTensor] = None return_dict: typing.Optional[bool] = None output_attentions: typing.Optional[bool] = None output_hidden_states: typing.Optional[bool] = None ) → transformers.models.fastspeech2_conformer.modeling_fastspeech2_conformer.FastSpeech2ConformerModelOutput 或 tuple(torch.FloatTensor)
引數
- input_ids (
torch.LongTensor,形狀為(batch_size, sequence_length)) — 文字向量輸入序列。 - attention_mask (
torch.LongTensor,形狀為(batch_size, sequence_length), 可選) — 用於避免對填充標記索引執行注意力操作的掩碼。掩碼值選擇在[0, 1]之間:- 1 表示 未被掩碼 的標記,
- 0 表示 被掩碼 的標記。
- spectrogram_labels (
torch.FloatTensor,形狀為(batch_size, max_spectrogram_length, num_mel_bins), 可選, 預設為None) — 填充後的目標特徵批次。 - duration_labels (
torch.LongTensor,形狀為(batch_size, sequence_length + 1), 可選, 預設為None) — 填充後的持續時間批次。 - pitch_labels (
torch.FloatTensor,形狀為(batch_size, sequence_length + 1, 1), 可選, 預設為None) — 填充後的音高標記平均值批次。 - energy_labels (
torch.FloatTensor,形狀為(batch_size, sequence_length + 1, 1), 可選, 預設為None) — 填充後的能量標記平均值批次。 - speaker_ids (
torch.LongTensor,形狀為(batch_size, 1), 可選, 預設為None) — 用於根據模型輸出的語音特徵進行條件化的說話人 ID。 - lang_ids (
torch.LongTensor,形狀為(batch_size, 1), 可選, 預設為None) — 用於根據模型輸出的語音特徵進行條件化的語言 ID。 - speaker_embedding (
torch.FloatTensor,形狀為(batch_size, embedding_dim), 可選, 預設為None) — 包含語音特徵條件訊號的嵌入。 - return_dict (
bool, 可選) — 是否返回 ModelOutput 而不是普通元組。 - output_attentions (
bool, 可選) — 是否返回所有注意力層的注意力張量。更多詳情請參見返回張量中的attentions。 - output_hidden_states (
bool, 可選) — 是否返回所有層的隱藏狀態。更多詳情請參見返回張量中的hidden_states。
返回
transformers.models.fastspeech2_conformer.modeling_fastspeech2_conformer.FastSpeech2ConformerModelOutput 或 tuple(torch.FloatTensor)
一個 transformers.models.fastspeech2_conformer.modeling_fastspeech2_conformer.FastSpeech2ConformerModelOutput 或一個 torch.FloatTensor 元組(如果傳遞 return_dict=False 或當 config.return_dict=False 時),包含根據配置 (FastSpeech2ConformerConfig) 和輸入的不同元素。
-
loss (形狀為
(1,)的torch.FloatTensor, 可選, 提供labels時返回) — 頻譜圖生成損失。 -
spectrogram (形狀為
(batch_size, sequence_length, num_bins)的torch.FloatTensor, 可選, 預設為None) — 預測的頻譜圖。 -
encoder_last_hidden_state (形狀為
(batch_size, sequence_length, hidden_size)的torch.FloatTensor, 可選, 預設為None) — 模型編碼器最後一層輸出的隱藏狀態序列。 -
encoder_hidden_states (
tuple[torch.FloatTensor], 可選, 傳遞output_hidden_states=True或當config.output_hidden_states=True時返回) — 形狀為(batch_size, sequence_length, hidden_size)的torch.FloatTensor元組(一個用於嵌入層輸出,如果模型有嵌入層,+一個用於每層輸出)。編碼器在每一層輸出時的隱藏狀態以及初始嵌入輸出。
-
encoder_attentions (
tuple[torch.FloatTensor], 可選, 傳遞output_attentions=True或當config.output_attentions=True時返回) — 形狀為(batch_size, num_heads, sequence_length, sequence_length)的torch.FloatTensor元組(每層一個)。編碼器的注意力權重,在注意力 softmax 之後,用於計算自注意力頭中的加權平均。
-
decoder_hidden_states (
tuple[torch.FloatTensor], 可選, 傳遞output_hidden_states=True或當config.output_hidden_states=True時返回) — 形狀為(batch_size, sequence_length, hidden_size)的torch.FloatTensor元組(一個用於嵌入層輸出,如果模型有嵌入層,+一個用於每層輸出)。解碼器在每一層輸出時的隱藏狀態以及初始嵌入輸出。
-
decoder_attentions (
tuple[torch.FloatTensor], 可選, 傳遞output_attentions=True或當config.output_attentions=True時返回) — 形狀為(batch_size, num_heads, sequence_length, sequence_length)的torch.FloatTensor元組(每層一個)。解碼器的注意力權重,在注意力 softmax 之後,用於計算自注意力頭中的加權平均。
-
duration_outputs (形狀為
(batch_size, max_text_length + 1)的torch.LongTensor, 可選) — 持續時間預測器的輸出。 -
pitch_outputs (形狀為
(batch_size, max_text_length + 1, 1)的torch.FloatTensor, 可選) — 音高預測器的輸出。 -
energy_outputs (形狀為
(batch_size, max_text_length + 1, 1)的torch.FloatTensor, 可選) — 能量預測器的輸出。
FastSpeech2ConformerWithHifiGan 的 forward 方法,重寫了 __call__ 特殊方法。
儘管前向傳播的配方需要在該函式內定義,但之後應呼叫 Module 例項,而不是此函式,因為前者負責執行預處理和後處理步驟,而後者則默默忽略它們。
示例
>>> from transformers import (
... FastSpeech2ConformerTokenizer,
... FastSpeech2ConformerWithHifiGan,
... )
>>> tokenizer = FastSpeech2ConformerTokenizer.from_pretrained("espnet/fastspeech2_conformer")
>>> inputs = tokenizer("some text to convert to speech", return_tensors="pt")
>>> input_ids = inputs["input_ids"]
>>> model = FastSpeech2ConformerWithHifiGan.from_pretrained("espnet/fastspeech2_conformer_with_hifigan")
>>> output_dict = model(input_ids, return_dict=True)
>>> waveform = output_dict["waveform"]
>>> print(waveform.shape)
torch.Size([1, 49664])