TRL 文件
TRL - Transformer 強化學習
加入 Hugging Face 社群
並獲得增強的文件體驗
開始使用

TRL - Transformer 強化學習
TRL 是一個全棧庫,我們提供了一套工具,用於透過監督式微調 (SFT)、組相對策略最佳化 (GRPO)、直接偏好最佳化 (DPO)、獎勵建模等方法訓練 Transformer 語言模型。該庫已與 🤗 transformers 整合。
🎉 最新動態
✨ 支援 OpenAI GPT OSS:TRL 現在完全支援微調最新的 OpenAI GPT OSS 模型!請檢視
您還可以在 TRL Hugging Face 組織中探索與 TRL 相關的模型、資料集和演示。
學習
在 🤗 smol 課程中學習使用 TRL 和其他庫進行後訓練。
內容
文件分為以下幾個部分
- 入門:安裝和快速入門指南。
- 概念指南:資料集格式、訓練常見問題解答和理解日誌。
- 操作指南:減少記憶體使用、加速訓練、分散式訓練等。
- 整合:DeepSpeed、Liger Kernel、PEFT 等。
- 示例:示例概覽、社群教程等。
- API:訓練器、工具等。
部落格文章

釋出於 2025 年 6 月 3 日
不讓任何 GPU 掉隊:透過在 TRL 中共置 vLLM 解鎖效率

釋出於 2025 年 5 月 25 日
🐯 Liger GRPO 與 TRL 的相遇

釋出於 2025 年 1 月 28 日
Open-R1:DeepSeek-R1 的完全開源復現

釋出於 2024 年 7 月 10 日
使用 TRL 對視覺語言模型進行偏好最佳化

釋出於 2024 年 6 月 12 日
讓 RL 重回 RLHF

釋出於 2023 年 9 月 29 日
透過 TRL 使用 DDPO 微調 Stable Diffusion 模型

釋出於 2023 年 8 月 8 日
使用 DPO 微調 Llama 2

釋出於 2023 年 4 月 5 日
StackLLaMA:使用 RLHF 訓練 LLaMA 的實踐指南

釋出於 2023 年 3 月 9 日
在 24GB 消費級 GPU 上使用 RLHF 微調 20B LLM
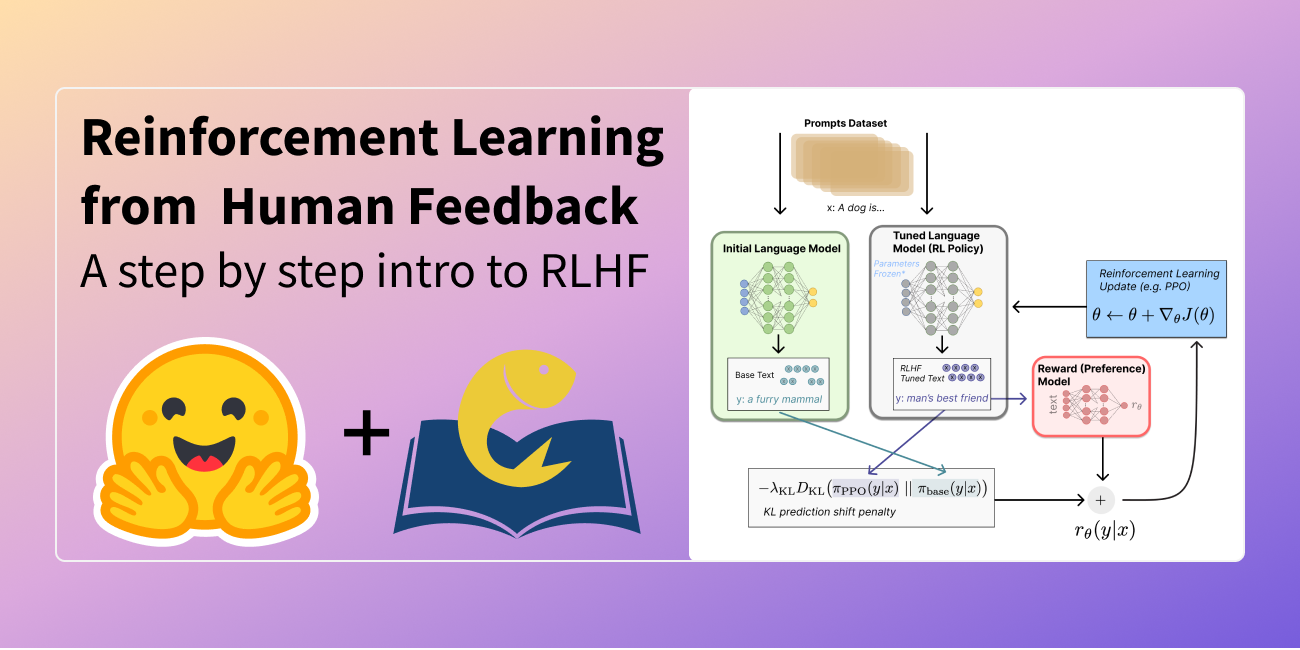
釋出於 2022 年 12 月 9 日
圖解人類反饋強化學習