使用 DeepSpeed 加速大型模型訓練








在這篇文章中,我們將探討如何利用 Accelerate 庫來訓練大型模型,該庫使使用者能夠利用 DeeSpeed 的 ZeRO 功能。
動機 🤗
在嘗試訓練大型模型時,是否厭倦了記憶體不足(OOM)錯誤?我們已為您解決。大型模型效能非常出色 [1],但難以用現有硬體進行訓練。為了最大限度地利用現有硬體訓練大型模型,可以使用 ZeRO - 零冗餘最佳化器 [2] 進行資料並行。.
下面是使用 ZeRO 進行資料並行的簡要描述,並附有來自這篇部落格文章的圖表 
(來源:連結)
a. 階段 1:在資料並行工作器/GPU 之間分片最佳化器狀態
b. 階段 2:在資料並行工作器/GPU 之間分片最佳化器狀態 + 梯度
c. 階段 3:在資料並行工作器/GPU 之間分片最佳化器狀態 + 梯度 + 模型引數
d. 最佳化器解除安裝:在 ZERO 階段 2 的基礎上,將梯度 + 最佳化器狀態解除安裝到 CPU/磁碟
e. 引數解除安裝:在 ZERO 階段 3 的基礎上,將模型引數解除安裝到 CPU/磁碟
在這篇部落格文章中,我們將探討如何使用 Accelerate 來利用 ZeRO 進行資料並行。DeepSpeed、FairScale 和 PyTorch FullyShardedDataParallel (FSDP) 已經實現了 ZERO 論文的核心思想。這些功能已經整合到 🤗 transformers Trainer 和 🤗 accelerate 中,並附有精彩的部落格文章 透過 DeepSpeed 和 FairScale 使用 ZeRO 適應更多並訓練更快 [4] 和 使用 PyTorch Fully Sharded Data Parallel 加速大型模型訓練 [5]。我們將其背後的解釋推遲到這些部落格文章,主要關注使用 Accelerate 利用 DeepSpeed ZeRO。
Accelerate 🚀:無需任何程式碼更改即可利用 DeepSpeed ZeRO
硬體設定:2X24GB NVIDIA Titan RTX GPU。60GB RAM。
我們將研究用於文字分類的僅編碼器模型微調任務。我們將使用預訓練的 microsoft/deberta-v2-xlarge-mnli(900M 引數)在 MRPC GLUE 資料集上進行微調。
程式碼可在此處找到 run_cls_no_trainer.py。它與此處的官方文字分類示例類似,但增加了測量訓練和評估時間的邏輯。讓我們比較多 GPU 設定中分散式資料並行(DDP)和 DeepSpeed ZeRO Stage-2 的效能。
要在不更改任何程式碼的情況下啟用 DeepSpeed ZeRO Stage-2,請執行 accelerate config 並利用 Accelerate DeepSpeed 外掛。
ZeRO Stage-2 DeepSpeed 外掛示例
compute_environment: LOCAL_MACHINE
deepspeed_config:
gradient_accumulation_steps: 1
gradient_clipping: 1.0
offload_optimizer_device: none
offload_param_device: none
zero3_init_flag: false
zero_stage: 2
distributed_type: DEEPSPEED
fsdp_config: {}
machine_rank: 0
main_process_ip: null
main_process_port: null
main_training_function: main
mixed_precision: fp16
num_machines: 1
num_processes: 2
use_cpu: false
現在,執行以下命令進行訓練
accelerate launch run_cls_no_trainer.py \
--model_name_or_path "microsoft/deberta-v2-xlarge-mnli" \
--task_name "mrpc" \
--ignore_mismatched_sizes \
--max_length 128 \
--per_device_train_batch_size 40 \
--learning_rate 2e-5 \
--num_train_epochs 3 \
--output_dir "/tmp/mrpc/deepspeed_stage2/" \
--with_tracking \
--report_to "wandb" \
在我們的單節點多 GPU 設定中,DDP 在不出現 OOM 錯誤的情況下支援的最大批次大小為 8。相比之下,DeepSpeed Zero-Stage 2 可以在不出現 OOM 錯誤的情況下支援批次大小為 40。因此,與 DDP 相比,DeepSpeed 使得每個 GPU 可以容納 5 倍 的資料。以下是 wandb 執行的圖表快照以及比較 DDP 與 DeepSpeed 的基準測試表。
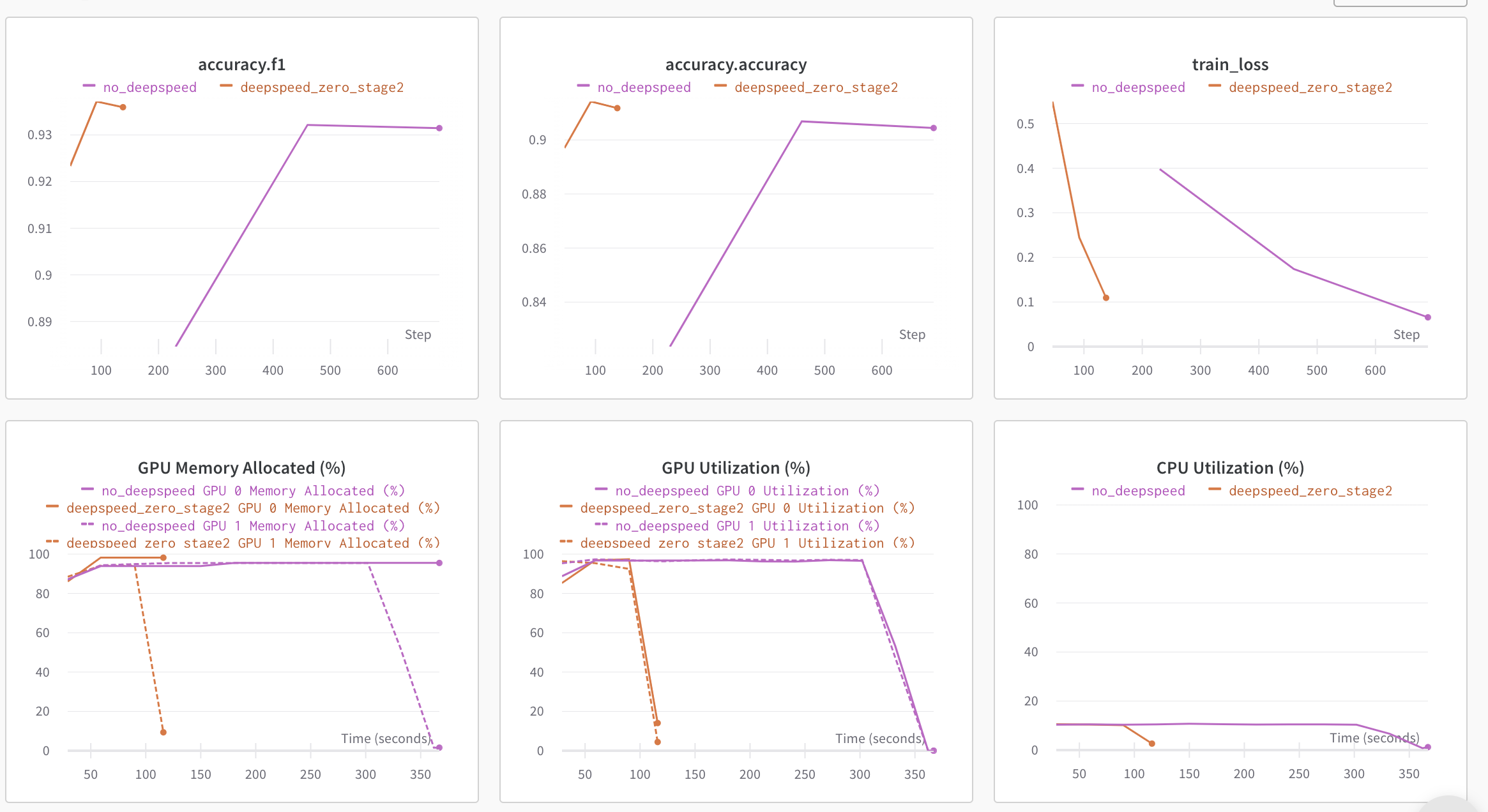
| 方法 | 最大批次大小 | 每個 epoch 的訓練時間(秒) | 每個 epoch 的評估時間(秒) | F1 分數 | 準確率 |
|---|---|---|---|---|---|
| DDP(分散式資料並行) | 8 | 103.57 | 2.04 | 0.931 | 0.904 |
| DeepSpeed ZeRO Stage 2 | 40 | 28.98 | 1.79 | 0.936 | 0.912 |
表 1:DeBERTa-XL (900M) 模型上的 DeepSpeed ZeRO Stage-2 基準測試
在不改變任何程式碼的情況下,使用更大的批次大小,我們觀察到總訓練時間加速了約 3.5 倍,而效能指標沒有任何下降。太棒了!🤗。
為了調整更多選項,您將需要使用 DeepSpeed 配置檔案和最少的程式碼更改。讓我們看看如何做到這一點。
Accelerate 🚀:利用 DeepSpeed 配置檔案調整更多選項
首先,我們將研究微調序列到序列模型以訓練我們自己的聊天機器人的任務。具體來說,我們將在 smangrul/MuDoConv(多領域對話)資料集上微調 facebook/blenderbot-400M-distill。該資料集包含來自 10 個不同資料來源的對話,涵蓋了人物、特定情感背景下的基礎、目標導向(例如,餐廳預訂)和一般維基百科主題(例如,板球)。
程式碼可在此處找到 run_seq2seq_no_trainer.py。目前有效衡量聊天機器人“參與度”和“人性化”的方法是透過人工評估,但這成本高昂 [6]。因此,對於此示例,跟蹤的指標是 BLEU 分數(儘管不理想,但它是此類任務的常規指標)。如果您可以使用支援 bfloat16 精度的 GPU,則可以調整程式碼以訓練更大的 T5 模型,否則您將遇到 NaN 損失值。我們將對 10000 個訓練樣本和 1000 個評估樣本進行快速基準測試,因為我們關注的是 DeepSpeed 與 DDP 的比較。
我們將利用 DeepSpeed Zero Stage-2 配置 zero2_config_accelerate.json(如下所示)進行訓練。有關各種配置功能的詳細資訊,請參閱 DeeSpeed 文件。
{
"fp16": {
"enabled": "true",
"loss_scale": 0,
"loss_scale_window": 1000,
"initial_scale_power": 15,
"hysteresis": 2,
"min_loss_scale": 1
},
"optimizer": {
"type": "AdamW",
"params": {
"lr": "auto",
"weight_decay": "auto",
"torch_adam": true,
"adam_w_mode": true
}
},
"scheduler": {
"type": "WarmupDecayLR",
"params": {
"warmup_min_lr": "auto",
"warmup_max_lr": "auto",
"warmup_num_steps": "auto",
"total_num_steps": "auto"
}
},
"zero_optimization": {
"stage": 2,
"allgather_partitions": true,
"allgather_bucket_size": 2e8,
"overlap_comm": true,
"reduce_scatter": true,
"reduce_bucket_size": 2e8,
"contiguous_gradients": true
},
"gradient_accumulation_steps": 1,
"gradient_clipping": "auto",
"steps_per_print": 2000,
"train_batch_size": "auto",
"train_micro_batch_size_per_gpu": "auto",
"wall_clock_breakdown": false
}
要使用上述配置啟用 DeepSpeed ZeRO Stage-2,請執行 accelerate config 並在要求時提供配置檔案路徑。有關更多詳細資訊,請參閱 🤗 accelerate 官方文件中的 DeepSpeed 配置檔案。
ZeRO Stage-2 DeepSpeed 配置檔案示例
compute_environment: LOCAL_MACHINE
deepspeed_config:
deepspeed_config_file: /path/to/zero2_config_accelerate.json
zero3_init_flag: false
distributed_type: DEEPSPEED
fsdp_config: {}
machine_rank: 0
main_process_ip: null
main_process_port: null
main_training_function: main
mixed_precision: fp16
num_machines: 1
num_processes: 2
use_cpu: false
現在,執行以下命令進行訓練
accelerate launch run_seq2seq_no_trainer.py \
--dataset_name "smangrul/MuDoConv" \
--max_source_length 128 \
--source_prefix "chatbot: " \
--max_target_length 64 \
--val_max_target_length 64 \
--val_min_target_length 20 \
--n_val_batch_generations 5 \
--n_train 10000 \
--n_val 1000 \
--pad_to_max_length \
--num_beams 10 \
--model_name_or_path "facebook/blenderbot-400M-distill" \
--per_device_train_batch_size 200 \
--per_device_eval_batch_size 100 \
--learning_rate 1e-6 \
--weight_decay 0.0 \
--num_train_epochs 1 \
--gradient_accumulation_steps 1 \
--num_warmup_steps 100 \
--output_dir "/tmp/deepspeed_zero_stage2_accelerate_test" \
--seed 25 \
--logging_steps 100 \
--with_tracking \
--report_to "wandb" \
--report_name "blenderbot_400M_finetuning"
當使用 DeepSpeed 配置時,如果使用者在配置中指定了 optimizer 和 scheduler,則使用者必須使用 accelerate.utils.DummyOptim 和 accelerate.utils.DummyScheduler。這些是使用者必須進行的唯一微小更改。下面我們展示了使用 DeepSpeed 配置時所需的最少更改示例
- optimizer = torch.optim.Adam(optimizer_grouped_parameters, lr=args.learning_rate)
+ optimizer = accelerate.utils.DummyOptim(optimizer_grouped_parameters, lr=args.learning_rate)
- lr_scheduler = get_scheduler(
- name=args.lr_scheduler_type,
- optimizer=optimizer,
- num_warmup_steps=args.num_warmup_steps,
- num_training_steps=args.max_train_steps,
- )
+ lr_scheduler = accelerate.utils.DummyScheduler(
+ optimizer, total_num_steps=args.max_train_steps, warmup_num_steps=args.num_warmup_steps
+ )
| 方法 | 最大批次大小 | 最大評估大小 | 每個 epoch 的訓練時間(秒) | 每個 epoch 的評估時間(秒) |
|---|---|---|---|---|
| DDP(分散式資料並行) | 100 | 50 | 27.36 | 48.41 |
| DeepSpeed ZeRO Stage 2 | 200 | 100 | 19.06 | 39.27 |
表 2:在 BlenderBot (400M) 模型上對 DeepSpeed ZeRO Stage-2 進行基準測試
在我們的單節點多 GPU 設定中,DDP 在不出現 OOM 錯誤的情況下支援的最大批次大小為 100。相比之下,DeepSpeed Zero-Stage 2 可以在不出現 OOM 錯誤的情況下支援批次大小為 200。因此,與 DDP 相比,DeepSpeed 使得每個 GPU 可以容納 2 倍 的資料。我們觀察到訓練加速約 1.44 倍,評估加速約 1.23 倍,因為我們能夠在相同的可用硬體上容納更多資料。由於該模型屬於中等大小,因此加速效果並非特別令人興奮,但對於更大的模型,這將有所改善。您可以透過 🤗 Space smangrul/Chat-E 與使用整個資料訓練的聊天機器人進行交流。您可以為機器人設定一個角色,將對話置於特定的情感背景下,用於目標導向的任務或以自由流式方式進行。下面是與聊天機器人進行的一次有趣的對話 💬。您可以在此處找到使用不同上下文進行更多對話的快照。
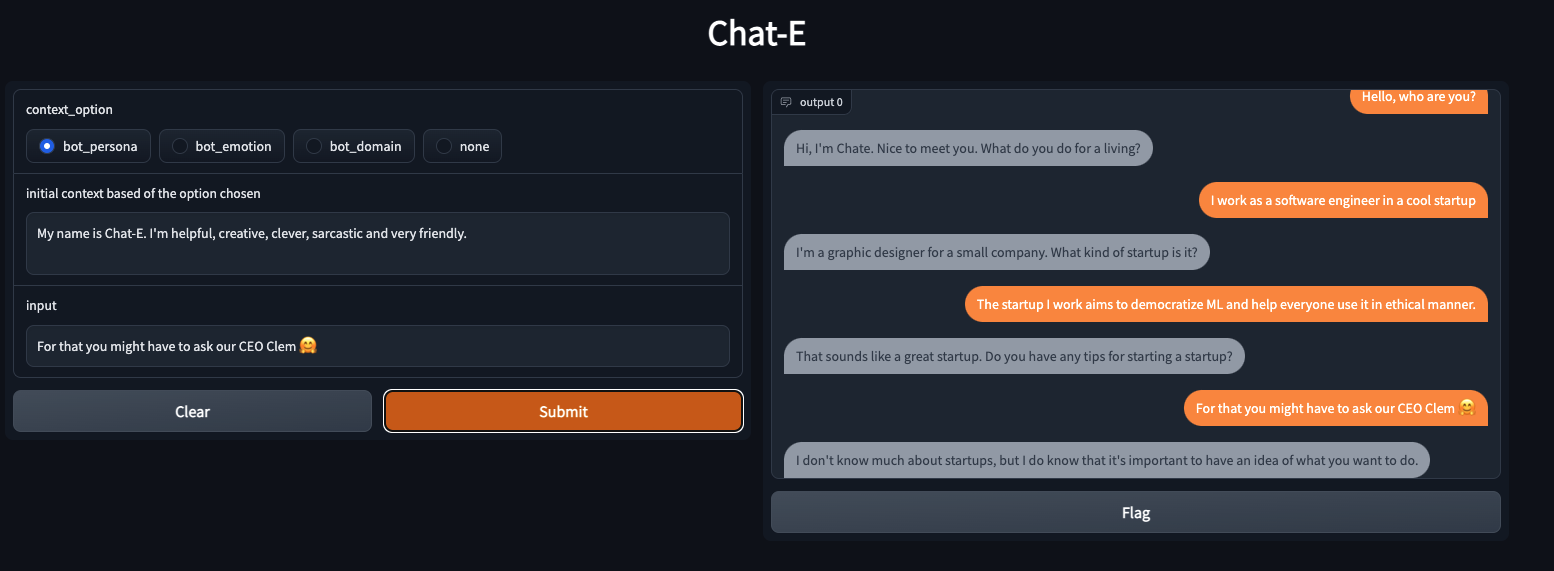
CPU/磁碟解除安裝以啟用無法適應 GPU 記憶體的巨型模型訓練
在單個 24GB NVIDIA Titan RTX GPU 上,即使批次大小為 1,也無法訓練 GPT-XL 模型(1.5B 引數)。我們將探討如何使用 DeepSpeed ZeRO Stage-3 和最佳化器狀態、梯度和引數的 CPU 解除安裝來訓練 GPT-XL 模型。
我們將利用 DeepSpeed Zero Stage-3 CPU 解除安裝配置 zero3_offload_config_accelerate.json(如下所示)進行訓練。使用 🤗 accelerate 配置的其餘過程與上述實驗類似。
{
"fp16": {
"enabled": true,
"loss_scale": 0,
"loss_scale_window": 1000,
"initial_scale_power": 16,
"hysteresis": 2,
"min_loss_scale": 1
},
"optimizer": {
"type": "AdamW",
"params": {
"lr": "auto",
"weight_decay": "auto"
}
},
"scheduler": {
"type": "WarmupDecayLR",
"params": {
"warmup_min_lr": "auto",
"warmup_max_lr": "auto",
"warmup_num_steps": "auto",
"total_num_steps": "auto"
}
},
"zero_optimization": {
"stage": 3,
"offload_optimizer": {
"device": "cpu",
"pin_memory": true
},
"offload_param": {
"device": "cpu",
"pin_memory": true
},
"overlap_comm": true,
"contiguous_gradients": true,
"reduce_bucket_size": "auto",
"stage3_prefetch_bucket_size": "auto",
"stage3_param_persistence_threshold": "auto",
"sub_group_size": 1e9,
"stage3_max_live_parameters": 1e9,
"stage3_max_reuse_distance": 1e9,
"stage3_gather_16bit_weights_on_model_save": true
},
"gradient_accumulation_steps": 1,
"gradient_clipping": "auto",
"steps_per_print": 2000,
"train_batch_size": "auto",
"train_micro_batch_size_per_gpu": "auto",
"wall_clock_breakdown": false
}
ZeRO Stage-3 CPU 解除安裝 DeepSpeed 配置檔案示例
compute_environment: LOCAL_MACHINE
deepspeed_config:
deepspeed_config_file: /path/to/zero3_offload_config_accelerate.json
zero3_init_flag: true
distributed_type: DEEPSPEED
fsdp_config: {}
machine_rank: 0
main_process_ip: null
main_process_port: null
main_training_function: main
mixed_precision: fp16
num_machines: 1
num_processes: 2
use_cpu: false
現在,執行以下命令進行訓練
accelerate launch run_clm_no_trainer.py \
--config_name "gpt2-xl" \
--tokenizer_name "gpt2-xl" \
--dataset_name "wikitext" \
--dataset_config_name "wikitext-2-raw-v1" \
--block_size 128 \
--output_dir "/tmp/clm_deepspeed_stage3_offload__accelerate" \
--learning_rate 5e-4 \
--per_device_train_batch_size 16 \
--per_device_eval_batch_size 1 \
--num_train_epochs 1 \
--with_tracking \
--report_to "wandb"\
| 方法 | 最大批次大小 | 每個 epoch 的訓練時間(秒) | 備註 |
|---|---|---|---|
| DDP(分散式資料並行) | - | - | OOM 錯誤 |
| DeepSpeed ZeRO 階段 3 | 16 | 6608.35 |
表 3:在 GPT-XL(1.5B)模型上進行 DeepSpeed ZeRO 階段 3 CPU 解除安裝的基準測試
即使批次大小為 1,DDP 也會導致 OOM 錯誤。另一方面,使用 DeepSpeed ZeRO Stage-3 CPU 解除安裝,我們可以以 16 的批次大小進行訓練。
最後,請記住,🤗 Accelerate 僅集成了 DeepSpeed,因此如果您在使用 DeepSpeed 方面有任何問題,請向 DeepSpeed GitHub 提交問題。
參考文獻
[1] 先訓練大模型,再壓縮:重新思考 Transformer 的高效訓練和推理模型大小
[3] DeepSpeed:人人可用的極致規模模型訓練 - 微軟研究院
[4] 透過 DeepSpeed 和 FairScale 使用 ZeRO 適應更多並訓練更快
[5] 使用 PyTorch Fully Sharded Data Parallel 加速大型模型訓練
[6] 構建開放領域聊天機器人的秘訣


