我們如何為 🤗 API 客戶將 Transformer 推理速度提升 100 倍
🤗 Transformers 已成為全球資料科學家探索最先進的自然語言處理(NLP)模型和構建新 NLP 功能的預設庫。它擁有超過 5,000 個預訓練和微調模型,支援超過 250 種語言,無論您使用哪種框架,它都是一個豐富且易於訪問的樂園。
儘管在 🤗 Transformers 中試驗模型很容易,但要在生產環境中以最高效能部署這些大型模型,並將它們管理在一個可隨使用量擴充套件的架構中,對任何機器學習工程師來說都是一個**艱鉅的工程挑戰**。
這 100 倍的效能提升和內建的可擴充套件性,是我們託管的 加速推理 API 的訂閱者選擇在其之上構建 NLP 功能的原因。為了實現**最後 10 倍的效能**提升,最佳化需要深入底層,並針對特定模型和目標硬體進行。
這篇文章分享了我們為客戶榨乾每一滴計算資源的一些方法。🍋
實現第一個 10 倍加速
最佳化之旅的第一步是最容易實現的,即使用 Hugging Face 庫 提供的最佳技術組合,這與目標硬體無關。
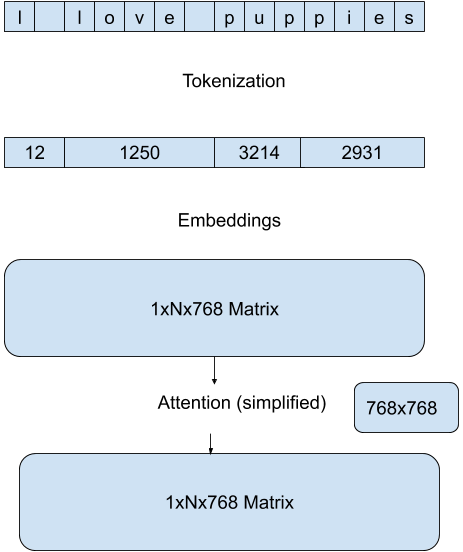
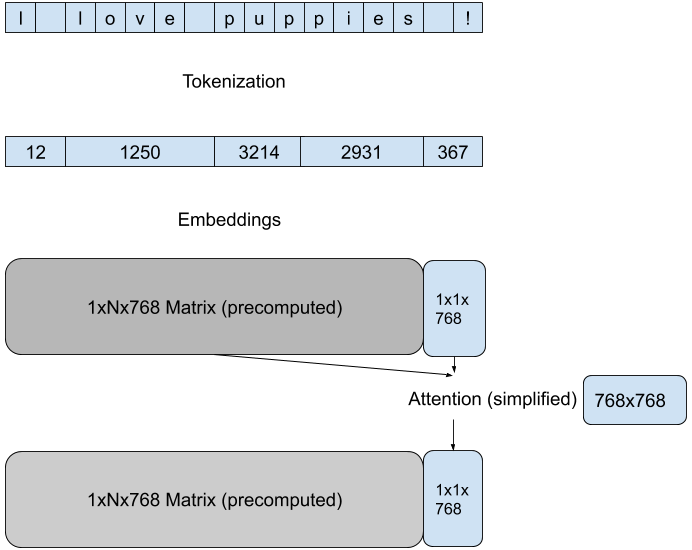
我們使用 Hugging Face 模型 pipelines 中內建的最高效方法,來減少每次前向傳播的計算量。這些方法特定於模型架構和目標任務,例如,對於 GPT 架構上的文字生成任務,我們透過在每次傳遞中專注於最後一個 token 的新注意力來降低注意力矩陣計算的維度。
| - | 樸素版本 | 最佳化版本 |
|---|---|---|
| - |  |
 |
在推理過程中,分詞(Tokenization)通常是效率的瓶頸。我們使用 🤗 Tokenizers 庫中最高效的方法,利用模型分詞器的 Rust 實現,並結合智慧快取,使整體延遲最多可提速 10 倍。
透過利用 Hugging Face 庫的最新功能,我們針對給定的模型/硬體組合,相比於開箱即用的部署方式,實現了可靠的 10 倍加速。由於 Transformers 和 Tokenizers 通常每個月都會發布新版本,我們的 API 客戶無需不斷適應新的最佳化機會,他們的模型會持續執行得更快。
編譯製勝:難以實現的 10 倍
現在,事情變得非常棘手了。為了獲得最佳效能,我們需要修改模型並針對特定的推理硬體進行編譯。硬體本身的選擇將取決於模型(記憶體大小)和需求概況(請求批處理)。即使是為同一個模型提供預測服務,一些 API 客戶可能會從加速 CPU 推理中獲益更多,而另一些則可能從加速 GPU 推理中獲益更多,每種情況都需要應用不同的最佳化技術和庫。
一旦為特定用例選定了計算平臺,我們就可以開始工作了。以下是一些可以在靜態圖上應用的 CPU 特定技術:
- 最佳化計算圖(移除未使用的流程)
- 融合層(使用特定的 CPU 指令)
- 量化操作
使用開源庫(例如 🤗 Transformers 與 ONNX Runtime)中的開箱即用功能不會產生最佳結果,或者可能導致精度的顯著損失,尤其是在量化過程中。沒有一勞永逸的解決方案,對於每種模型架構,最佳路徑都各不相同。但透過深入研究 Transformers 程式碼和 ONNX Runtime 文件,我們可以協調各方因素,再實現一個 10 倍的加速。
不公平優勢
Transformer 架構是機器學習效能的一個決定性轉折點,它始於 NLP 領域。在過去 3 年中,自然語言理解和生成的改進速度急劇加快。另一個相應加速的指標是模型的平均大小,從 BERT 的 1.1 億引數增長到如今 GPT-3 的 1750 億引數。
這一趨勢給機器學習工程師在將最新模型部署到生產環境時帶來了嚴峻的挑戰。雖然 100 倍的加速是一個很高的門檻,但這正是在即時消費者應用中以可接受的延遲提供預測服務所必需的。
作為 Hugging Face 的機器學習工程師,為了達到這個門檻,我們當然擁有一個不公平的優勢,那就是與 🤗 Transformers 和 🤗 Tokenizers 的維護者們在同一個(虛擬)辦公室工作 😬。我們也非常幸運,透過與英特爾、英偉達、高通、亞馬遜和微軟等硬體和雲供應商的開源合作,我們建立了豐富的夥伴關係,這使我們能夠利用最新的硬體最佳化技術來調整我們的模型和基礎設施。
如果您想在我們的基礎設施上感受速度,請開始免費試用,我們會與您聯絡。如果您想在我們最佳化您自己基礎設施的經驗中受益,請參與我們的 。