優勢 Actor-Critic (A2C)






Hugging Face 深度強化學習課程 🤗 第 7 單元
⚠️ 本文的最新版本已釋出在此處 👉 https://huggingface.co/deep-rl-course/unit1/introduction
本文是深度強化學習課程的一部分。這是一個從入門到精通的免費課程。請在此處檢視課程大綱 here.

⚠️ 本文的最新版本已釋出在此處 👉 https://huggingface.co/deep-rl-course/unit1/introduction
本文是深度強化學習課程的一部分。這是一個從入門到精通的免費課程。請在此處檢視課程大綱 here.
在第 5 單元中,我們學習了第一個基於策略的演算法,名為 Reinforce。在基於策略的方法中,我們旨在直接最佳化策略,而不使用值函式。更準確地說,Reinforce 屬於*基於策略方法*的一個子類,稱為*策略梯度方法*。該子類透過使用梯度上升法估計最優策略的權重來直接最佳化策略。
我們看到 Reinforce 效果不錯。然而,由於我們使用蒙特卡洛取樣來估計回報(我們使用整個回合來計算回報),策略梯度估計存在顯著的方差。
請記住,策略梯度估計是回報最陡峭的增長方向。也就是說,如何更新我們的策略權重,以便使導致良好回報的動作有更高的被選擇機率。我們將在本單元進一步研究的蒙特卡洛方差,會導致訓練速度變慢,因為我們需要大量樣本來減輕它。
今天我們將學習 Actor-Critic 方法,這是一種結合了基於值和基於策略的方法的混合架構,透過減少方差來幫助穩定訓練。
- 一個 Actor(演員),控制我們智慧體的行為方式(基於策略的方法)
- 一個 Critic(評論家),衡量所採取動作的好壞(基於值的方法)
我們將研究其中一種混合方法,稱為優勢 Actor Critic (A2C),並使用 Stable-Baselines3 在機器人環境中訓練我們的智慧體。我們將訓練兩個智慧體學會走路:
- 一個雙足步行者 🚶
- 一隻蜘蛛 🕷️

聽起來很刺激吧?我們開始吧!
Reinforce 演算法中的方差問題
在 Reinforce 中,我們希望根據回報的高低成比例地增加軌跡中動作的機率。

- 如果回報高,我們將提高(狀態,動作)組合的機率。
- 反之,如果回報低,它將降低(狀態,動作)組合的機率。
這個回報 是使用*蒙特卡洛取樣*計算的。實際上,我們收集一條軌跡並計算折扣回報,然後使用這個分數來增加或減少該軌跡中每個動作的機率。如果回報好,所有動作都將透過增加其被採取的可能性而得到“加強”。
這種方法的優點是它是無偏的。因為我們沒有估計回報,我們只使用我們獲得的真實回報。
但問題是方差很高,因為由於環境的隨機性(回合中的隨機事件)和策略的隨機性,軌跡可能導致不同的回報。因此,相同的起始狀態可能導致非常不同的回報。正因為如此,從同一狀態開始的回報在不同回合之間可能會有很大差異。
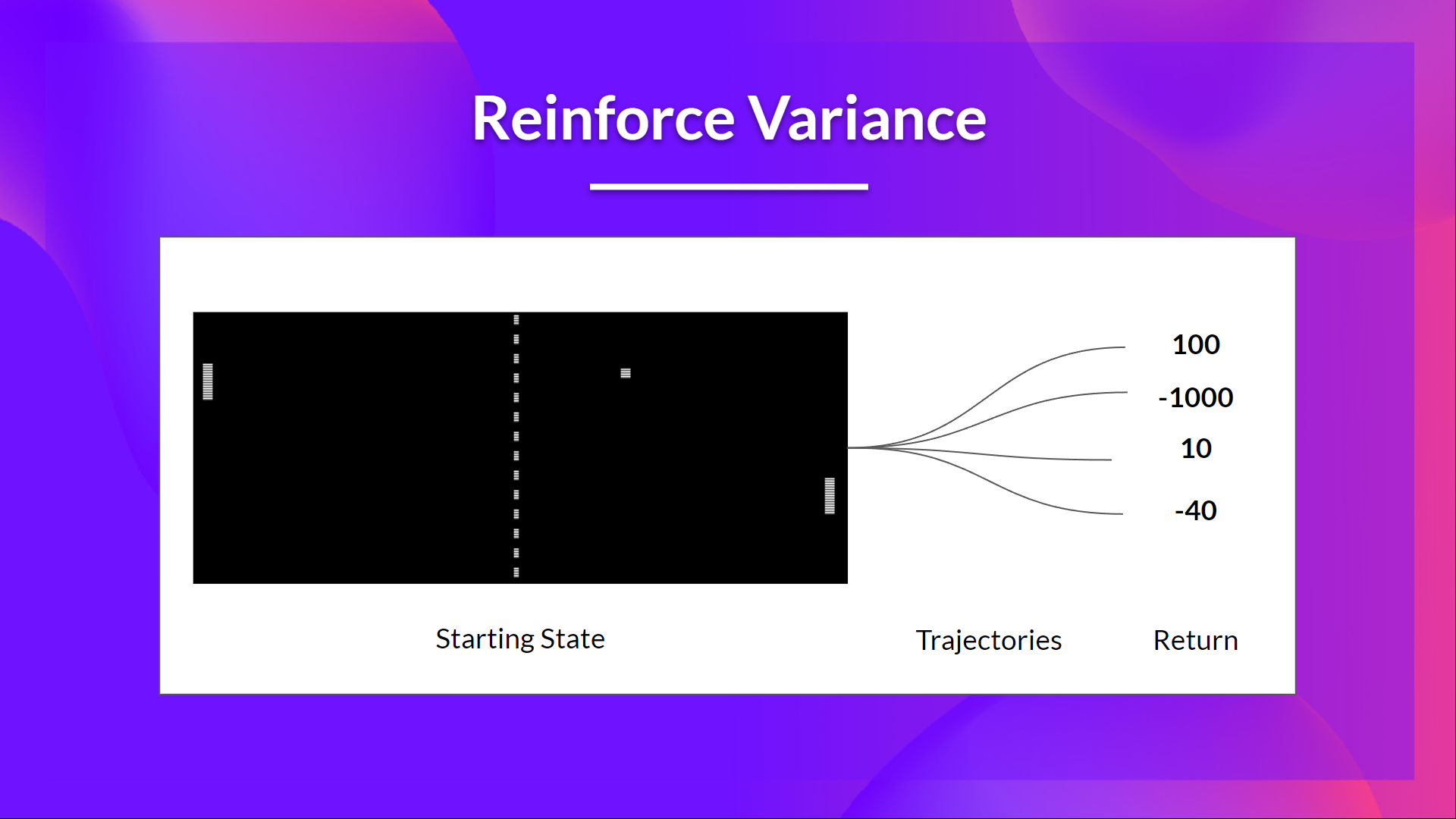
解決方案是透過使用大量軌跡來減輕方差,希望在任何一條軌跡中引入的方差能在總體上減少,並提供一個“真實”的回報估計。
然而,顯著增加批次大小會降低樣本效率。因此,我們需要找到額外的機制來減少方差。
如果你想更深入地瞭解深度強化學習中的方差和偏差權衡問題,可以檢視這兩篇文章: - 理解(深度)強化學習中的偏差/方差權衡 - 強化學習中的偏差-方差權衡
優勢 Actor-Critic (A2C)
使用 Actor-Critic 方法減少方差
減少 Reinforce 演算法方差並更快、更好地訓練我們的智慧體的解決方案是使用基於策略和基於值的方法的組合:Actor-Critic 方法。
要理解 Actor-Critic,想象你在玩一個電子遊戲。你可以和一個會給你反饋的朋友一起玩。你是 Actor(演員),你的朋友是 Critic(評論家)。

一開始你不知道怎麼玩,所以你隨機嘗試一些動作。Critic 觀察你的動作並提供反饋。
從這些反饋中學習, 你將更新你的策略,並在玩這個遊戲時表現得更好。
另一方面,你的朋友(Critic)也會更新他提供反饋的方式,以便下次能做得更好。
這就是 Actor-Critic 背後的思想。我們學習兩個函式近似:
一個策略,它控制我們的智慧體如何行動:
一個值函式,透過衡量所採取動作的好壞來輔助策略更新:
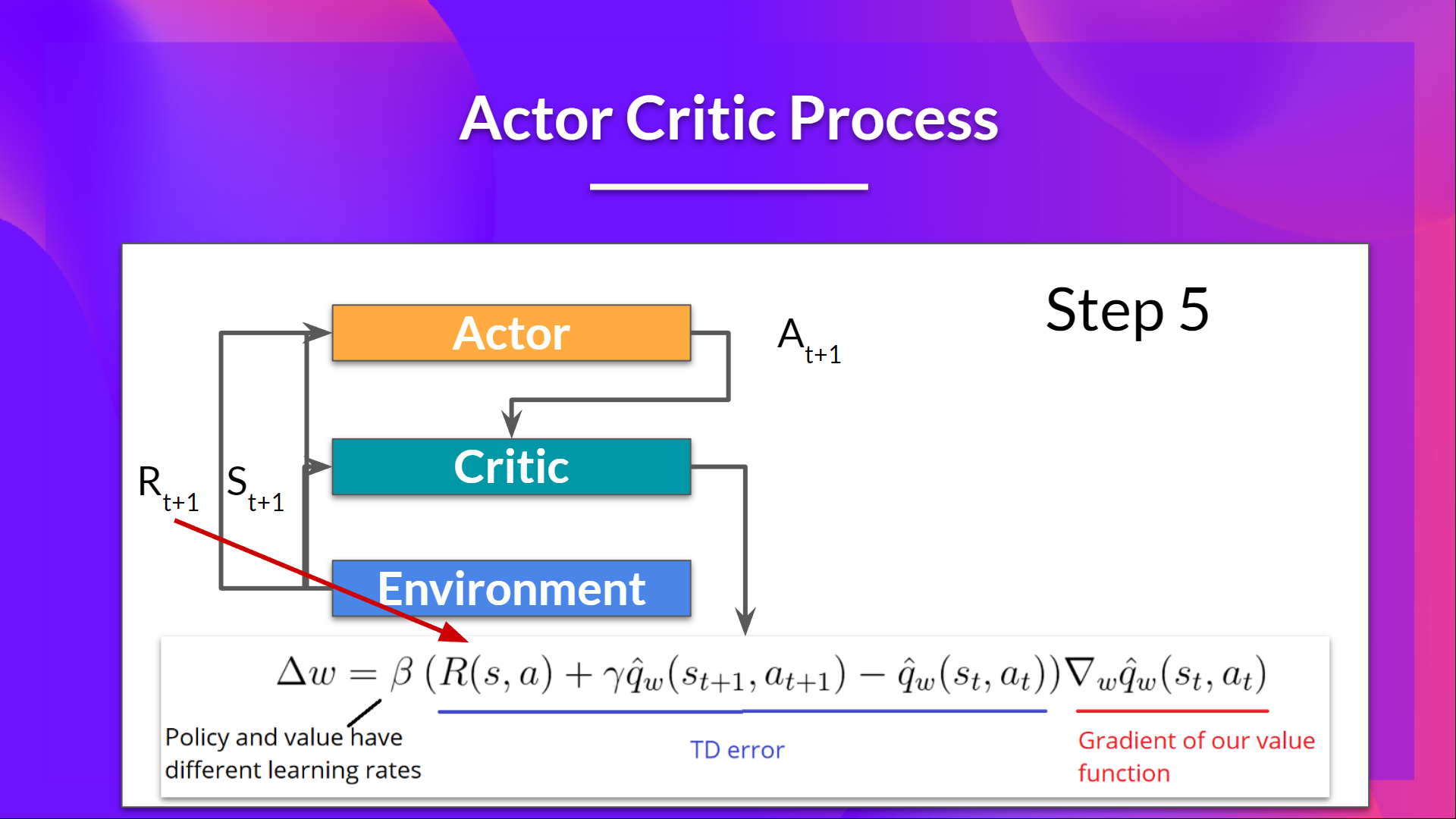
Actor-Critic 流程
現在我們已經瞭解了 Actor-Critic 的大概情況,讓我們深入探討一下 Actor 和 Critic 在訓練過程中是如何共同進步的。
正如我們所見,Actor-Critic 方法中有兩個函式近似(兩個神經網路):
- Actor,一個由 theta 引數化的策略函式:
- Critic,一個由 w 引數化的值函式:
我們來看看訓練過程,以瞭解 Actor 和 Critic 是如何被最佳化的。
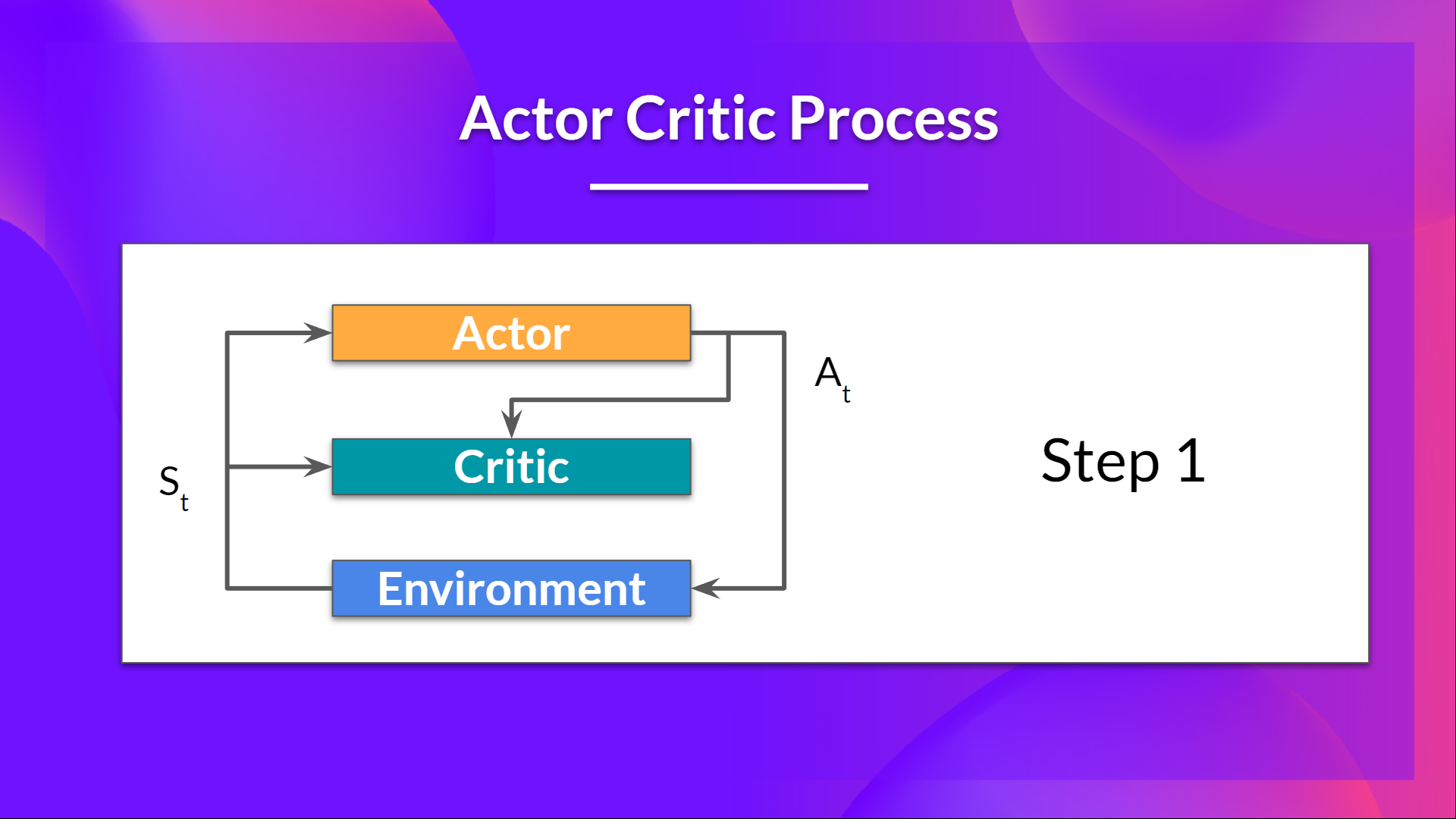
在每個時間步 t,我們從環境中獲得當前狀態 ,並將其作為輸入傳遞給我們的 Actor 和 Critic。
我們的策略接收狀態並輸出一個動作 。
- Critic 也將該動作作為輸入,並使用 和 ,計算在該狀態下采取該動作的價值:即 Q 值。
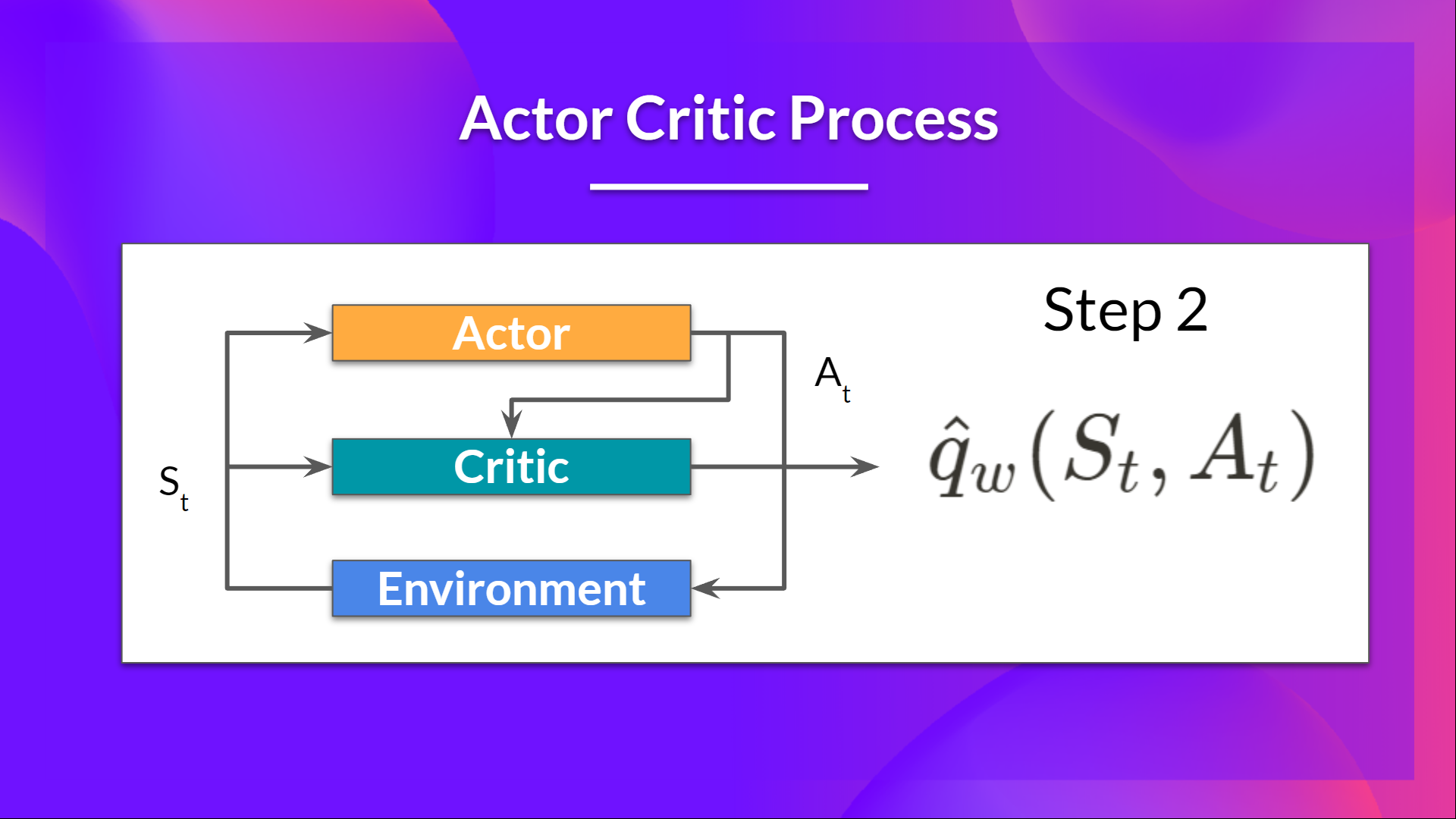
- 在環境中執行的動作 會產生一個新的狀態 和一個獎勵 。
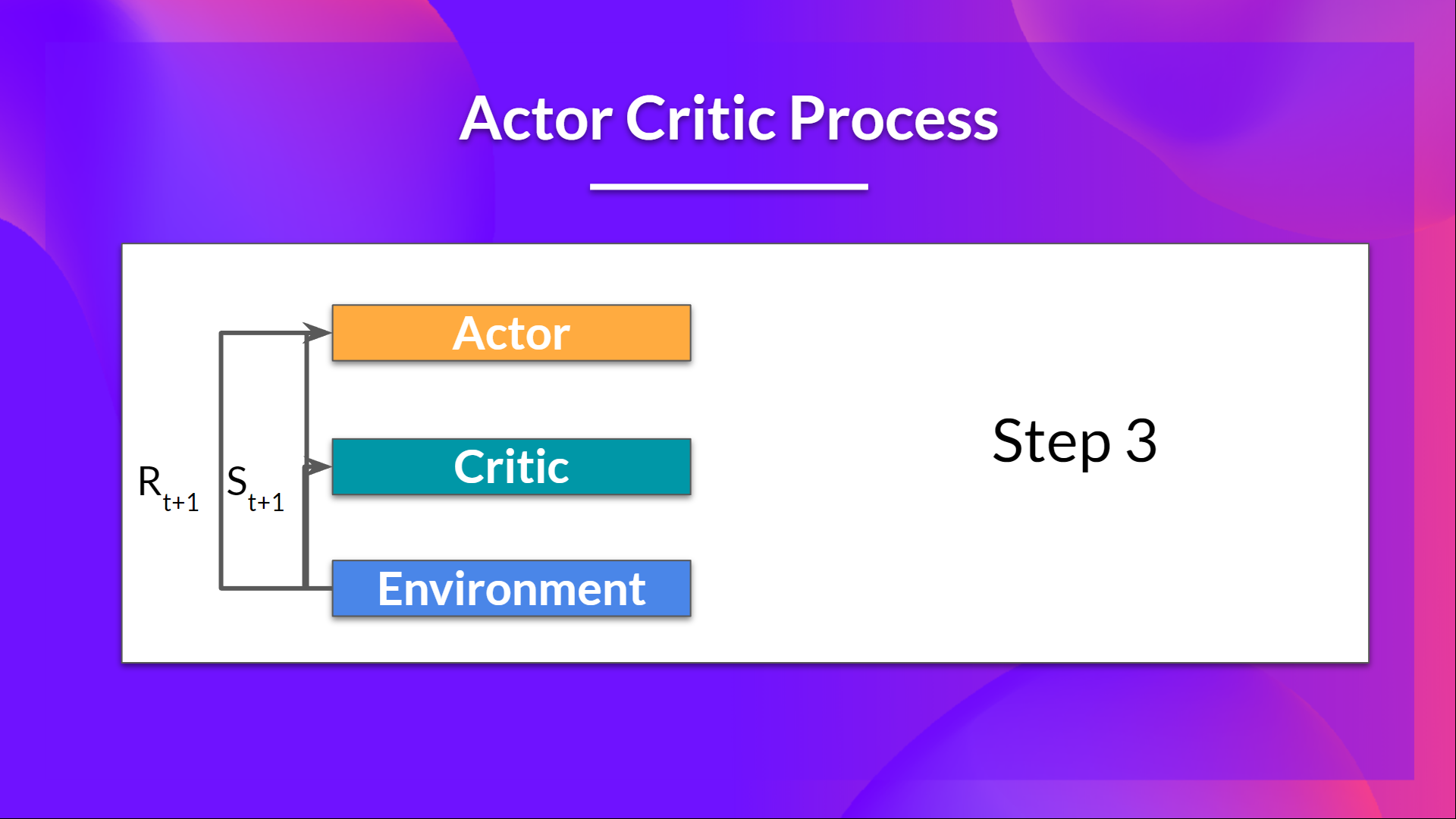
- Actor 使用 Q 值更新其策略引數。

得益於其更新後的引數,Actor 會在給定新狀態 的情況下,生成在 要採取的下一個動作。
然後 Critic 更新其值引數。
優勢 Actor-Critic (A2C)
我們可以透過使用優勢函式作為 Critic 而不是動作值函式來進一步穩定學習。
其思想是,優勢函式計算的是在該狀態下采取該動作相比於該狀態的平均價值有多好。它是從狀態-動作對中減去狀態的平均價值。

換句話說,這個函式計算的是如果我們在這個狀態下采取這個動作,相比於我們在這個狀態下獲得的平均獎勵,我們能獲得的額外獎勵。
額外的獎勵是超出該狀態期望價值的部分。
- 如果 A(s,a) > 0:我們的梯度將朝那個方向推動。
- 如果 A(s,a) < 0(我們的動作比該狀態的平均價值差),我們的梯度將朝相反方向推動。
實現這個優勢函式的問題在於它需要兩個值函式—— 和 。幸運的是, 我們可以使用 TD 誤差作為優勢函式的一個良好估計。

使用 PyBullet 進行機器人模擬的優勢 Actor Critic (A2C) 🤖
現在你已經學習了優勢 Actor Critic (A2C) 背後的理論, 你已經準備好使用 Stable-Baselines3 在機器人環境中訓練你的 A2C 智慧體了 。
點選此處開始教程 👉 https://colab.research.google.com/github/huggingface/deep-rl-class/blob/main/unit7/unit7.ipynb
用於與同學比較結果的排行榜 🏆 👉 https://huggingface.co/spaces/chrisjay/Deep-Reinforcement-Learning-Leaderboard
結論
恭喜你完成本章!這裡有很多資訊。也恭喜你完成了教程。🥳
如果你對所有這些元素仍然感到困惑,這很正常。 我和所有學習強化學習的人都有過同樣的感受。
在繼續之前,花點時間理解這些材料。同時,請檢視我們在本文和教學大綱中提供的額外閱讀材料以進行更深入的學習 👉 https://github.com/huggingface/deep-rl-class/blob/main/unit7/README.md
不要猶豫,在其他環境中訓練你的 Agent。最好的學習方式是自己動手嘗試!
在下一個單元中,我們將學習使用近端策略最佳化(Proximal Policy Optimization)來改進 Actor-Critic 方法。
別忘了與想要學習的朋友分享 🤗!
最後,我們希望透過您的反饋來迭代改進和更新課程。如果您有任何建議,請填寫此表格 👉 https://forms.gle/3HgA7bEHwAmmLfwh9

