近端策略最佳化 (Proximal Policy Optimization, PPO)







Hugging Face 深度強化學習課程 🤗 第八單元
⚠️ 本文的最新更新版本請點選此處 👉 https://huggingface.co/deep-rl-course/unit1/introduction
本文是深度強化學習課程的一部分。這是一個從入門到精通的免費課程。請在此處檢視課程大綱 here. 
⚠️ 本文的最新更新版本請點選此處 👉 https://huggingface.co/deep-rl-course/unit1/introduction
本文是深度強化學習課程的一部分。這是一個從入門到精通的免費課程。請在此處檢視課程大綱 here.
在上一單元中,我們學習了優勢 Actor-Critic (A2C),這是一種結合了基於價值和基於策略方法的混合架構,透過以下方式減少方差來穩定訓練:
- Actor(演員) 控制 我們 Agent 的行為方式 (基於策略的方法)。
- Critic(評論家) 衡量 所採取行動的好壞 (基於價值的方法)。
今天我們將學習近端策略最佳化 (Proximal Policy Optimization, PPO),這是一種透過避免過大的策略更新來提高 Agent 訓練穩定性的架構。為此,我們使用一個比率來表示當前策略和舊策略之間的差異,並將此比率裁剪到一個特定範圍 內。
這樣做可以確保 我們的策略更新不會過大,從而使訓練更加穩定。
然後,在理論之後,我們將使用 PyTorch 從頭開始編寫 PPO 架構,並使用 CartPole-v1 和 LunarLander-v2 對我們的實現進行穩健性測試。
聽起來很刺激吧?我們開始吧!
PPO 背後的直覺
近端策略最佳化 (PPO) 的思想是,我們希望透過限制在每個訓練週期對策略進行的更改來提高策略的訓練穩定性:我們希望避免過大的策略更新。
原因有二:
- 我們從經驗上知道,訓練期間較小的策略更新更有可能收斂到最優解。
- 策略更新中過大的一步可能會導致“跌落懸崖”(得到一個糟糕的策略),並且需要很長時間甚至無法恢復。

因此,使用 PPO,我們保守地更新策略。為此,我們需要使用當前策略和舊策略之間的比率計算來衡量當前策略與之前策略的變化程度。我們將這個比率裁剪在一個範圍 內,這意味著我們消除了當前策略偏離舊策略太遠的動機(因此稱為近端策略項)。
引入裁剪替代目標函式 (Clipped Surrogate Objective)
回顧:策略目標函式
讓我們回顧一下 Reinforce 演算法中需要最佳化的目標函式:
其思想是,透過對這個函式進行梯度上升(等同於對此函式的負值進行梯度下降),我們能夠促使我們的 Agent 採取能帶來更高回報的行動,並避免有害的行動。
然而,問題出在步長上
- 步長太小,訓練過程會太慢
- 步長太大,訓練中會有太大的不確定性
在這裡,PPO 的思想是透過一個名為*裁剪替代目標函式 (Clipped surrogate objective function)* 的新目標函式來約束我們的策略更新,該函式使用裁剪將策略變化限制在一個小範圍內。
這個新函式旨在避免破壞性的大權重更新。

讓我們研究每個部分,以理解其工作原理。
比率函式

這個比率是這樣計算的

它是當前策略下在狀態 採取行動 的機率與前一策略下采取該行動的機率之比。
正如我們所見, 表示當前策略和舊策略之間的機率比。
- 如果 ,那麼在狀態 下采取行動 在當前策略中比在舊策略中更有可能發生。
- 如果 在 0 和 1 之間,那麼該行動在當前策略中比在舊策略中發生的可能性更小。
因此,這個機率比是一種估計舊策略和當前策略之間差異的簡單方法。
裁剪替代目標函式的未裁剪部分

這個比率可以替代我們在策略目標函式中使用的對數機率。這就得到了新目標函式的左半部分:將比率乘以優勢值。

然而,如果沒有約束,如果所採取的行動在當前策略中比在舊策略中更有可能發生,這將導致一個顯著的策略梯度步長,從而導致過度的策略更新。
裁剪替代目標函式的裁剪部分

因此,我們需要透過懲罰導致比率偏離 1 的變化來約束此目標函式(在論文中,比率只能在 0.8 到 1.2 之間變化)。
透過裁剪比率,我們確保不會有太大的策略更新,因為當前策略不能與舊策略相差太大。
為此,我們有兩種解決方案
- TRPO (Trust Region Policy Optimization, 信賴域策略最佳化) 在目標函式之外使用 KL 散度約束來限制策略更新。但這種方法實現複雜且計算耗時較多。
- PPO 透過其裁剪替代目標函式直接在目標函式中裁剪機率比。
這個裁剪部分是 rt(theta) 被裁剪在 之間的一個版本。
有了裁剪替代目標函式,我們就有兩個機率比率,一個未裁剪的,一個裁剪在一定範圍內的(在 之間,epsilon 是一個幫助我們定義這個裁剪範圍的超引數,在論文中 )。
然後,我們取裁剪後和未裁剪目標的最小值,因此最終目標是未裁剪目標的一個下界(悲觀界限)。
取裁剪和未裁剪目標的最小值意味著我們將根據比率和優勢情況選擇裁剪或未裁剪的目標。
視覺化裁剪替代目標函式
別擔心。如果現在這看起來很複雜,這是正常的。但我們將看到這個裁剪替代目標函式是什麼樣子,這將幫助你更好地形象化正在發生的事情。
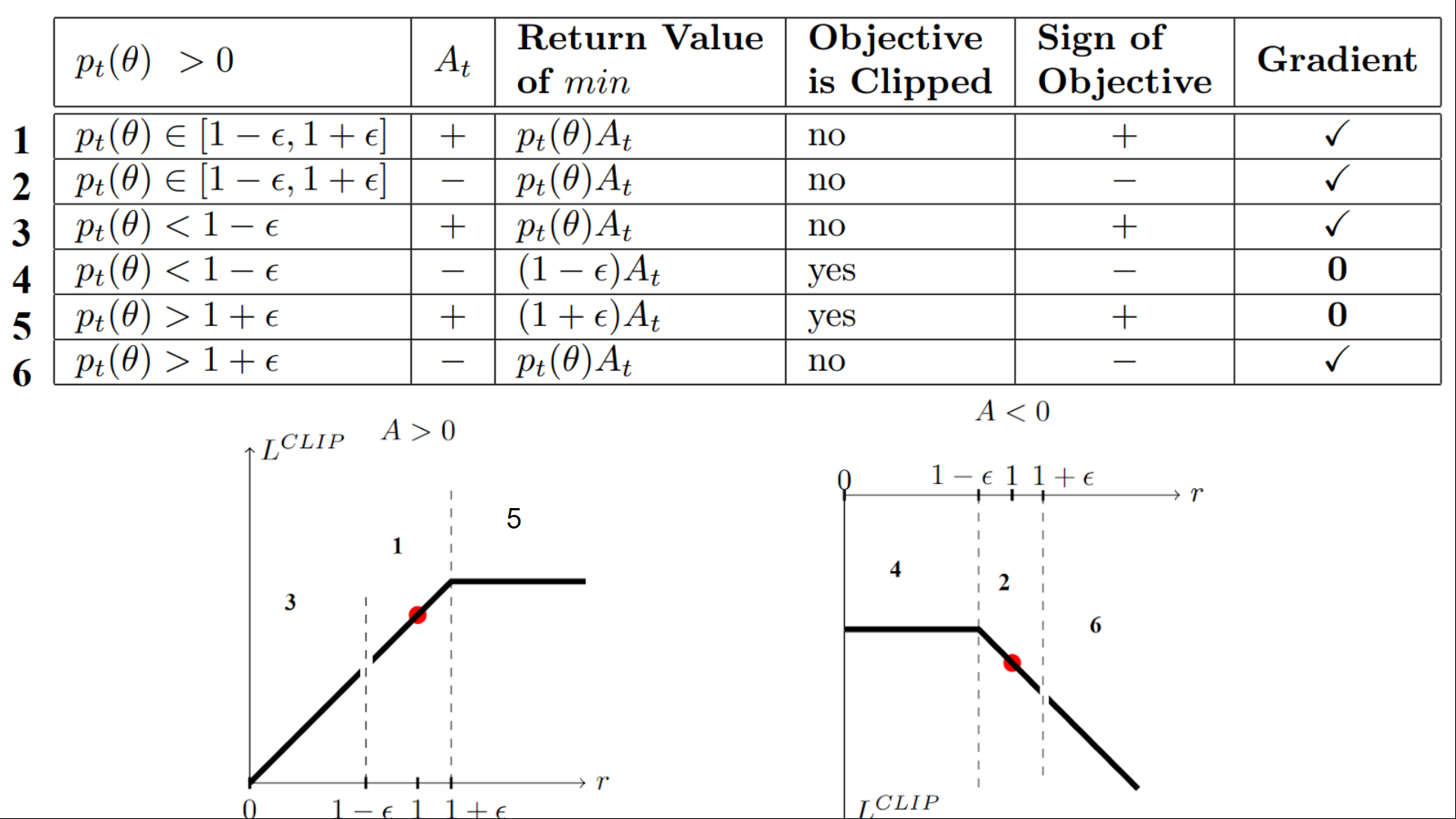
我們有六種不同的情況。首先記住,我們在裁剪和未裁剪的目標之間取最小值。
情況 1 和 2:比率在範圍內
在情況 1 和 2 中,裁剪不適用,因為比率在範圍 內。
在情況 1 中,我們有一個正的優勢值:該行動優於該狀態下所有行動的平均值。因此,我們應該鼓勵我們當前的策略增加在該狀態下采取該行動的機率。
由於比率在區間內,我們可以增加我們的策略在該狀態下采取該行動的機率。
在情況 2 中,我們有一個負的優勢值:該行動比該狀態下所有行動的平均值要差。因此,我們應該不鼓勵我們當前的策略在該狀態下采取該行動。
由於比率在區間內,我們可以降低我們的策略在該狀態下采取該行動的機率。
情況 3 和 4:比率低於範圍
如果機率比低於 ,那麼在該狀態下采取該行動的機率比舊策略要低得多。
如果像情況 3 那樣,優勢估計是正的 (A>0),那麼你希望增加在該狀態下采取該行動的機率。
但如果像情況 4 那樣,優勢估計是負的,我們不希望進一步降低在該狀態下采取該行動的機率。因此,梯度=0(因為我們在一條平線上),所以我們不更新權重。
情況 5 和 6:比率高於範圍
如果機率比高於 ,那麼當前策略在該狀態下采取該行動的機率遠高於舊策略。
如果像情況 5 那樣,優勢值為正,我們不希望變得太貪心。我們已經比舊策略有更高的機率在該狀態下采取該行動。因此,梯度=0(因為我們在一條平線上),所以我們不更新權重。
如果像情況 6 那樣,優勢值為負,我們希望降低在該狀態下采取該行動的機率。
總而言之,我們只用未裁剪的目標部分來更新策略。當最小值為裁剪的目標部分時,我們不更新策略權重,因為梯度將等於 0。
所以我們只在以下情況下更新策略:
- 我們的比率在範圍 內。
- 我們的比率超出了範圍,但優勢值導致其更接近範圍
- 比率低於範圍,但優勢值 > 0
- 比率高於範圍,但優勢值 < 0
你可能想知道為什麼當最小值為裁剪比率時,梯度為 0。 當比率被裁剪時,這種情況下的導數將不是 的導數,而是 或 的導數,這兩者都等於 0。
總而言之,由於這個裁剪替代目標,我們限制了當前策略可以偏離舊策略的範圍。因為我們消除了機率比移動到區間外的動機,因為裁剪會影響梯度。如果比率 > 或 < ,梯度將等於 0。
PPO Actor-Critic 風格的最終裁剪替代目標損失函式是這樣的,它是裁剪替代目標函式、價值損失函式和熵獎勵的組合
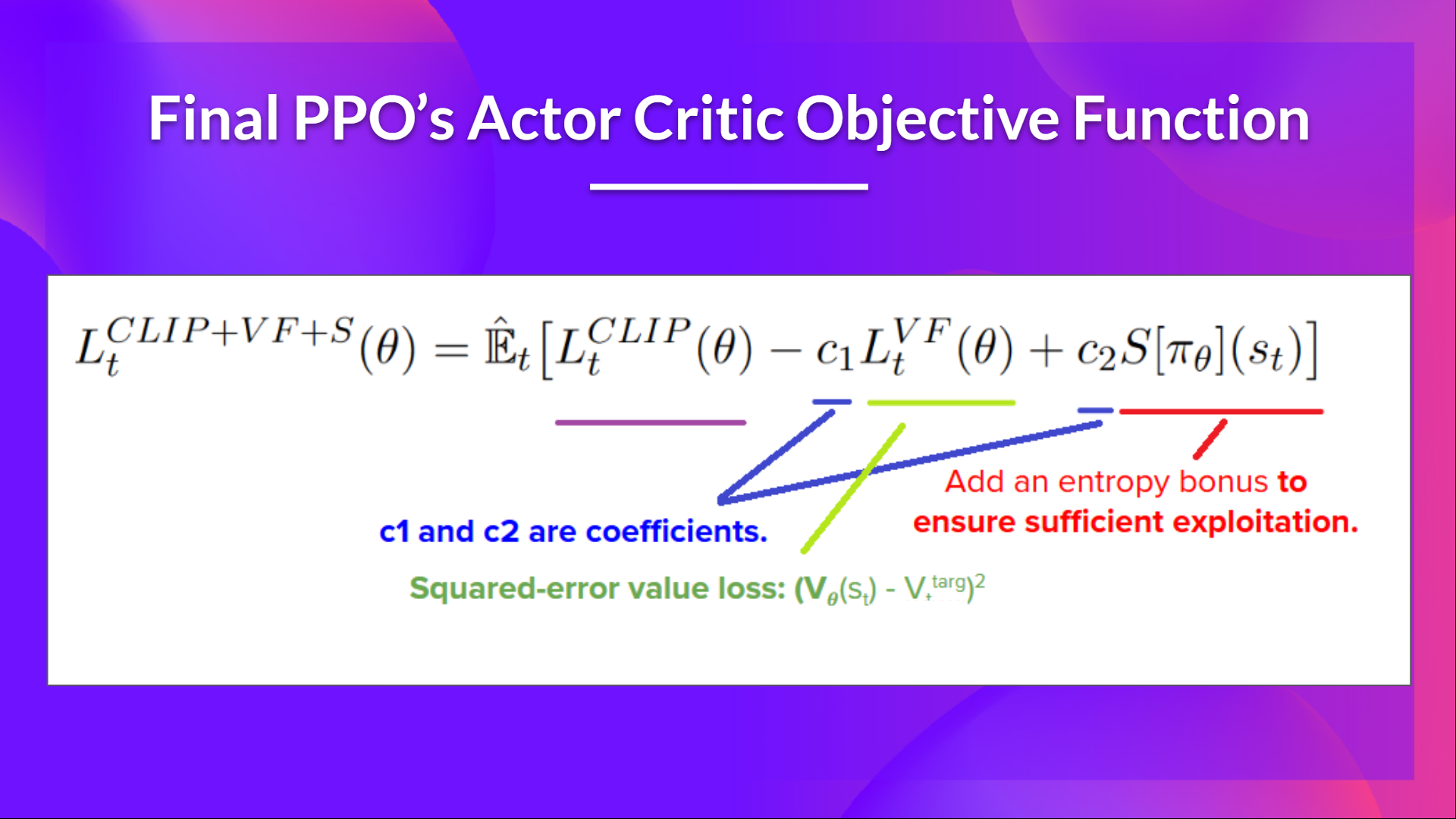
這部分相當複雜。花些時間透過查看錶格和圖表來理解這些情況。你必須理解為什麼這樣做是合理的。如果你想深入瞭解,最好的資源是 Daniel Bick 的文章 《邁向對近端策略最佳化的連貫自洽解釋》(Towards Delivering a Coherent Self-Contained Explanation of Proximal Policy Optimization),尤其是第 3.4 部分。
讓我們來編寫 PPO Agent
既然我們已經學習了 PPO 背後的理論,理解其工作原理的最佳方式就是從頭開始實現它。
從頭開始實現一個架構是理解它的最佳方式,也是一個好習慣。我們已經對基於價值的 Q-Learning 方法和基於策略的 Reinforce 方法這樣做過。
因此,為了能夠編寫它,我們將使用兩個資源
- 由 Costa Huang 製作的教程。Costa 是 CleanRL 的幕後開發者,這是一個深度強化學習庫,提供高質量的單檔案實現,並具有適合研究的特性。
- 除了教程,要更深入地瞭解,你可以閱讀 13 個核心實現細節:https://iclr-blog-track.github.io/2022/03/25/ppo-implementation-details/
然後,為了測試其魯棒性,我們將在 2 個不同的經典環境中訓練它
最後,我們會將訓練好的模型推送到 Hub,以評估和視覺化你的 Agent 玩遊戲的情況。
LunarLander-v2 是你開始本課程時使用的第一個環境。那時,你不知道它是如何工作的,而現在,你可以從頭開始編寫程式碼並訓練它。這有多麼不可思議 🤩。
從這裡開始教程 👉 https://github.com/huggingface/deep-rl-class/blob/main/unit8/unit8.ipynb
恭喜完成本章!這裡有很多資訊。也恭喜你完成了教程。🥳,這是本課程中最難的部分之一。
不要猶豫,在其他環境中訓練你的 Agent。最好的學習方式是自己動手嘗試!
我希望你思考一下自第一單元以來的進步。透過這八個單元,你已經在深度強化學習方面打下了堅實的基礎。恭喜你!
但這並不是結束,即使課程的基礎部分已經完成,這也不是旅程的終點。我們正在開發新的內容
- 增加新的環境和教程。
- 一個關於多智慧體(自對弈、合作、競爭)的部分。
- 另一個關於離線強化學習和決策 Transformer 的部分。
- 論文解讀文章。
- 以及更多內容即將到來。
保持聯絡的最佳方式是註冊課程,以便我們向你更新最新資訊 👉 http://eepurl.com/h1pElX
別忘了與想要學習的朋友分享 🤗!
最後,我們希望透過你的反饋迭代地改進和更新課程。如果你有任何建議,請填寫此表格 👉 https://forms.gle/3HgA7bEHwAmmLfwh9
下次見!







