少樣本學習實踐:GPT-Neo 和 🤗 加速推理 API







在許多機器學習應用程式中,可用標記資料的數量是生成高效能模型的障礙。NLP 的最新發展表明,您可以透過在推理時提供少量示例來克服此限制,這是一種稱為少樣本學習的技術,利用大型語言模型。在本部落格文章中,我們將解釋什麼是少樣本學習,並探討如何使用大型語言模型 GPT-Neo 和 🤗 加速推理 API 來生成您自己的預測。
什麼是少樣本學習?
少樣本學習是指透過極少量訓練資料(例如在推理時提供幾個示例)來指導機器學習模型的預測,這與需要相對大量訓練資料才能使預訓練模型準確適應所需任務的標準微調技術相反。
該技術主要用於計算機視覺領域,但隨著一些最新的語言模型,如 EleutherAI GPT-Neo 和 OpenAI GPT-3,我們現在可以在自然語言處理(NLP)中使用它。
在自然語言處理中,少樣本學習可以與大型語言模型一起使用,這些模型在大型文字資料集上進行預訓練時已經學會了隱式執行大量任務。這使得模型能夠透過少量示例來泛化,即理解相關但以前未見過的任務。
少樣本 NLP 示例由三個主要組成部分構成:
- 任務描述:模型應該做什麼的簡短描述,例如“將英語翻譯成法語”
- 示例:一些示例,展示模型預期會預測什麼,例如“sea otter => loutre de mer”
- 提示:新示例的開頭,模型應透過生成缺失文字來完成,例如“cheese => ”

圖片來源:《語言模型是少樣本學習器》
建立這些少樣本示例可能很棘手,因為您需要透過它們來闡明模型應該執行的“任務”。一個常見的問題是,模型,尤其是小型模型,對示例的編寫方式非常敏感。
在生產中最佳化少樣本學習的一種方法是學習任務的通用表示,然後在此表示之上訓練任務特定的分類器。
OpenAI 在 GPT-3 論文中表明,少樣本提示能力隨著語言模型引數的數量而提高。
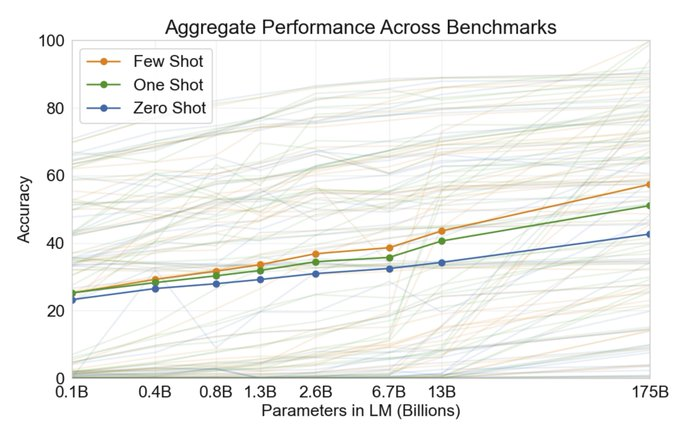
圖片來源:《語言模型是少樣本學習器》
現在,讓我們看看如何使用 GPT-Neo 和 🤗 Accelerated Inference API 來生成您自己的少樣本學習預測!
什麼是 GPT-Neo?
GPT-Neo 是 EleutherAI 開發的一系列基於 GPT 架構的轉換器語言模型。EleutherAI 的主要目標是訓練一個與 GPT-3 大小相當的模型,並以開放許可協議向公眾提供。
目前所有可用的 GPT-Neo 檢查點都使用 Pile 資料集進行訓練,Pile 資料集是一個大型文字語料庫,在(Gao et al., 2021)中有詳細記載。因此,它有望在與其訓練文字分佈相匹配的文字上表現更好;我們建議您在設計示例時牢記這一點。
🤗 加速推理 API
加速推理 API 是我們託管的服務,透過簡單的 API 呼叫,您可以在 🤗 模型中心上執行 10,000 多個公開可用的模型,或您自己的私有模型。與開箱即用的 Transformers 部署相比,該 API 在 CPU 和 GPU 上提供了加速,速度提升高達 100 倍。
要在您自己的應用程式中整合使用 GPT-Neo 進行少樣本學習預測,您可以使用下面的程式碼片段和 🤗 Accelerated Inference API。您可以在此處找到您的 API 令牌,如果您還沒有帳戶,可以從此處開始。
import json
import requests
API_TOKEN = ""
def query(payload='',parameters=None,options={'use_cache': False}):
API_URL = "https://api-inference.huggingface.co/models/EleutherAI/gpt-neo-2.7B"
headers = {"Authorization": f"Bearer {API_TOKEN}"}
body = {"inputs":payload,'parameters':parameters,'options':options}
response = requests.request("POST", API_URL, headers=headers, data= json.dumps(body))
try:
response.raise_for_status()
except requests.exceptions.HTTPError:
return "Error:"+" ".join(response.json()['error'])
else:
return response.json()[0]['generated_text']
parameters = {
'max_new_tokens':25, # number of generated tokens
'temperature': 0.5, # controlling the randomness of generations
'end_sequence': "###" # stopping sequence for generation
}
prompt="...." # few-shot prompt
data = query(prompt,parameters,options)
實用見解
以下是一些實用見解,可幫助您開始使用 GPT-Neo 和 🤗 加速推理 API。
由於 GPT-Neo (2.7B) 比 GPT-3 (175B) 小約 60 倍,因此它在零樣本問題上的泛化能力不如後者,需要 3-4 個示例才能獲得良好的結果。當您提供更多示例時,GPT-Neo 會理解任務並考慮 end_sequence,這使得我們能夠很好地控制生成的文字。
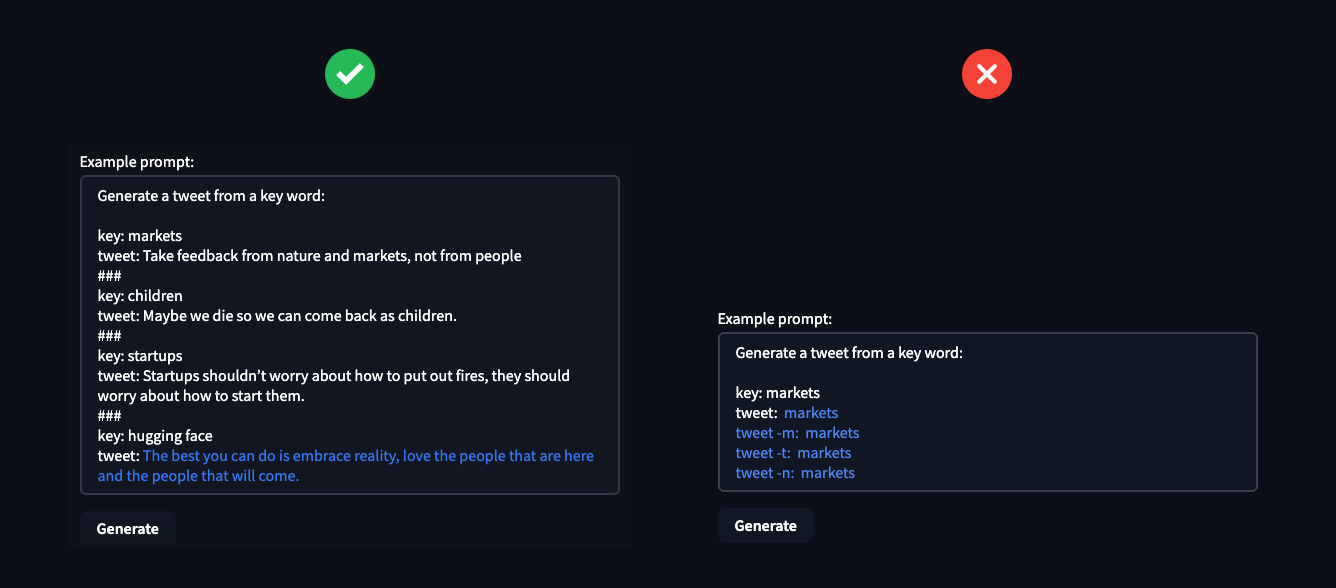
超引數 End Sequence、Token Length 和 Temperature 可用於控制模型的 text-generation,您可以利用它們來解決所需任務。Temperature 控制生成文字的隨機性,較低的溫度會導致較少的隨機生成,而較高的溫度會導致更多的隨機生成。
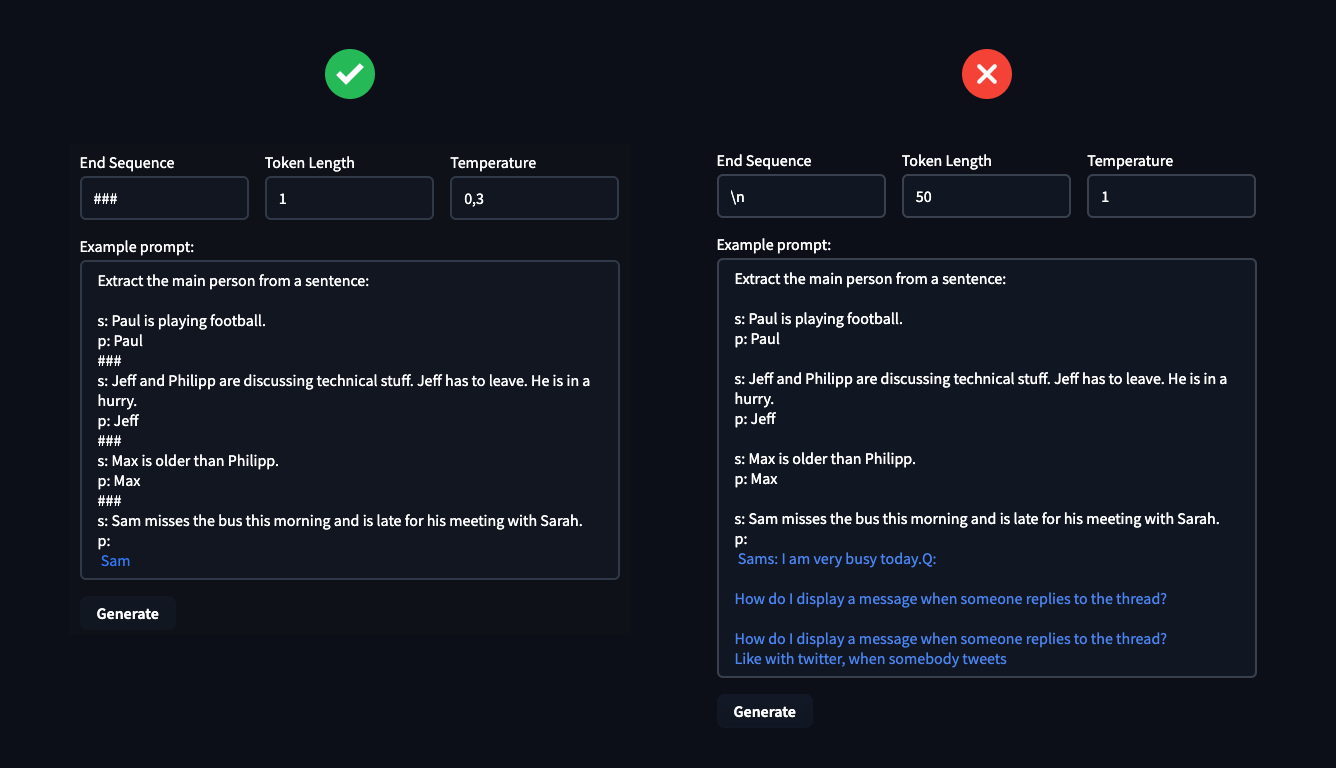
在示例中,您可以看到定義超引數的重要性。這些可以決定您是成功解決任務還是慘敗。
負責任的使用
少樣本學習是一種強大的技術,但也存在獨特的陷阱,在設計用例時需要加以考慮。為了說明這一點,讓我們考慮小部件中提供的預設 情感分析 設定。在看到三個情感分類示例後,模型在 temperature 設定為 0.1 時,在五次中預測了四次以下結果:
推文:“我是一個殘疾的快樂的人”
情緒:消極
這可能會出什麼問題?想象一下,您正在使用情感分析來彙總線上購物網站上的產品評論:一個可能的結果是,對殘疾人有用物品可能會自動降級——這是一種自動化歧視。有關此特定問題的更多資訊,我們推薦 ACL 2020 論文《NLP 模型中的社會偏見作為殘疾人的障礙》。由於少樣本學習更直接地依賴於從預訓練中獲取的資訊和關聯,因此它對此類故障更為敏感。
如何將傷害風險降至最低?以下是一些實用建議。
負責任使用的最佳實踐
- 確保人們瞭解其使用者體驗的哪些部分依賴於機器學習系統的輸出
- 如果可能,允許使用者選擇退出
- 提供一種機制,允許使用者對模型決策提供反饋,並覆蓋它
- 監控反饋,特別是模型故障,針對可能受到不成比例影響的使用者群體
最需要避免的是,在沒有人為干預或糾正輸出的機會下,使用模型自動為使用者或關於使用者做出決策。歐洲的GDPR 等法規要求向用戶提供對其做出的自動決策的解釋。
要在您自己的應用程式中使用 GPT-Neo 或任何 Hugging Face 模型,您可以開始免費試用 🤗 Accelerated Inference API。如果您需要幫助緩解模型和人工智慧系統中的偏差,或利用少樣本學習,🤗 專家加速計劃可以。
