更快的訓練和推理:Habana Gaudi®-2 對比 Nvidia A100 80GB



在本文中,您將學習如何使用 Habana® Gaudi®2 來加速模型訓練和推理,並使用 🤗 Optimum Habana 訓練更大的模型。然後,我們介紹了包括 BERT 預訓練、Stable Diffusion 推理和 T5-3B 微調在內的幾項基準測試,以評估第一代 Gaudi、Gaudi2 和 Nvidia A100 80GB 之間的效能差異。劇透警告——Gaudi2 在訓練和推理方面都比 Nvidia A100 80GB 快約兩倍!
Gaudi2 是 Habana Labs 設計的第二代 AI 硬體加速器。單個伺服器包含 8 個加速器裝置,每個裝置具有 96GB 記憶體(而第一代 Gaudi 為 32GB,A100 80GB 為 80GB)。Habana SDK SynapseAI 適用於第一代 Gaudi 和 Gaudi2。這意味著 🤗 Optimum Habana,它在 🤗 Transformers 和 🤗 Diffusers 庫與 SynapseAI 之間提供了非常使用者友好的介面,**在 Gaudi2 上的工作方式與在第一代 Gaudi 上完全相同!**因此,如果您已經有適用於第一代 Gaudi 的即用型訓練或推理工作流程,我們鼓勵您在 Gaudi2 上嘗試它們,因為它們無需任何更改即可工作。
如何訪問 Gaudi2?
英特爾和 Habana 提供 Gaudi2 的一種簡單、經濟高效的方式是在英特爾開發雲上。要開始在那裡使用 Gaudi2,您應該遵循以下步驟:
訪問 英特爾開發雲登入頁面,登入您的賬戶,如果沒有賬戶則註冊。
訪問 英特爾開發雲管理控制檯。
選擇“Habana Gaudi2 深度學習伺服器,包含八張 Gaudi2 HL-225H 夾層卡和最新的 Intel® Xeon® 處理器”,然後單擊右下角的“啟動例項”,如下圖所示。
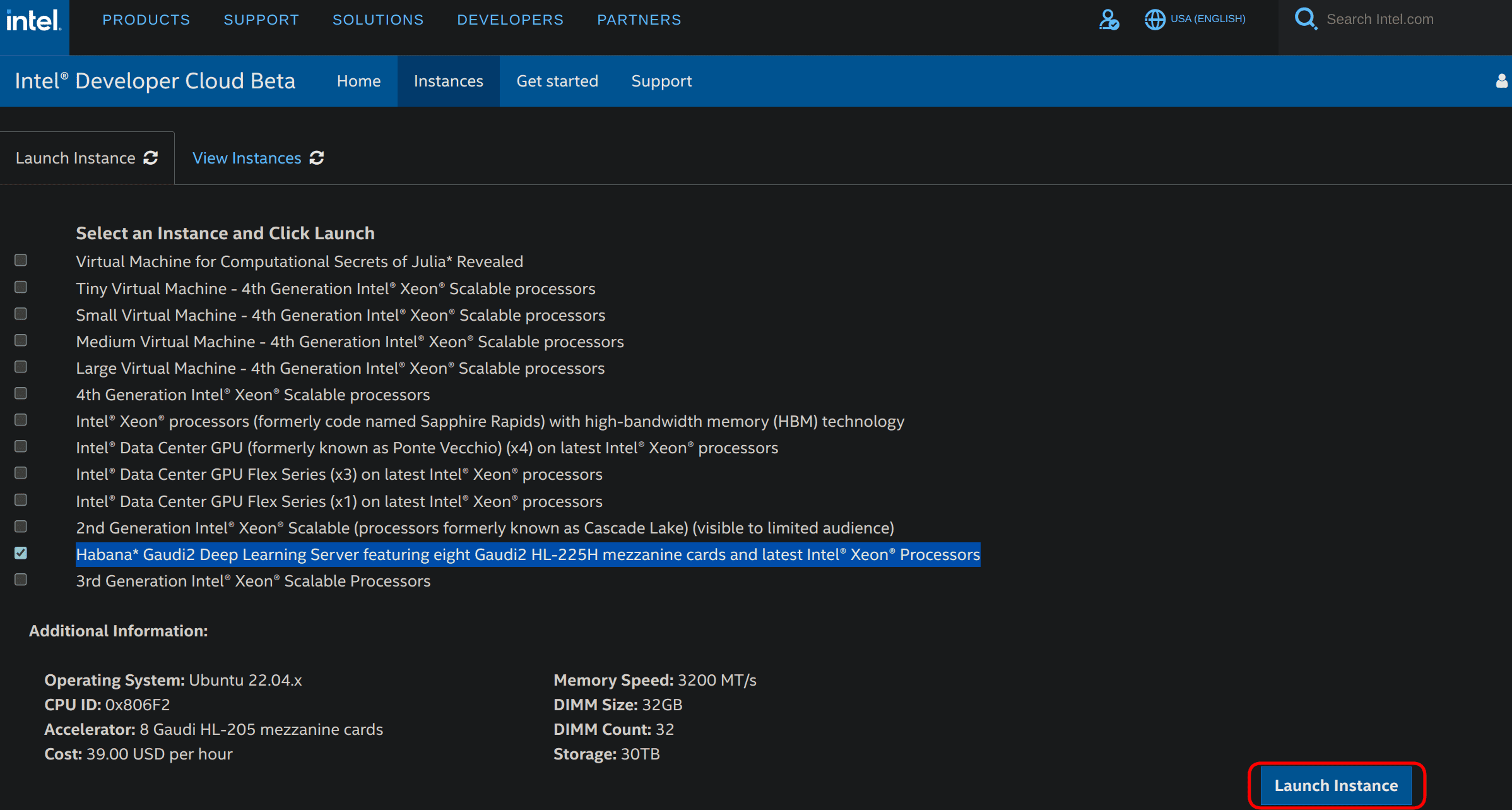
然後您可以請求一個例項
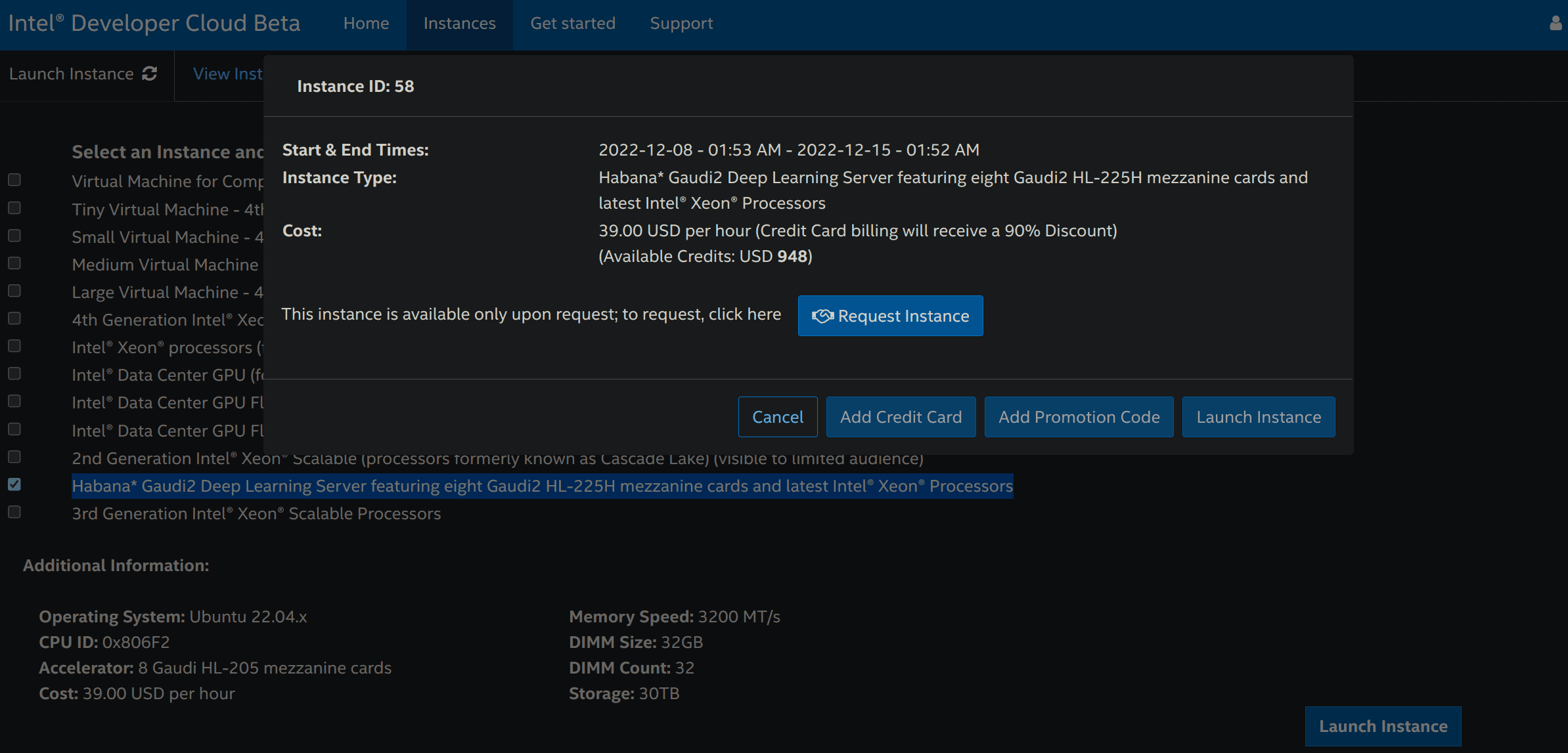
請求透過驗證後,重複步驟 3 並點選“新增 OpenSSH 公鑰”來新增支付方式(信用卡或促銷程式碼)和 SSH 公鑰,您可以使用
ssh-keygen -t rsa -b 4096 -f ~/.ssh/id_rsa生成 SSH 公鑰。每次新增支付方式或 SSH 公鑰時,您可能會被重定向到步驟 3。重新執行步驟 3,然後單擊“啟動例項”。您必須接受建議的通用條款才能實際啟動例項。
訪問 英特爾開發雲管理控制檯,然後單擊名為“檢視例項”的選項卡。
您可以複製 SSH 命令以遠端訪問您的 Gaudi2 例項!
如果您終止例項並希望再次使用 Gaudi2,則必須重新執行整個過程。
您可以在此處找到有關此過程的更多資訊。
基準測試
我們進行了一些基準測試,以評估第一代 Gaudi、Gaudi2 和 A100 80GB 在訓練和推理方面的能力,以及不同大小模型的表現。
BERT 預訓練
幾個月前,Hugging Face 的技術主管 Philipp Schmid 介紹了如何在 Gaudi 上使用 🤗 Optimum Habana 預訓練 BERT。共進行了 65k 訓練步驟,每個裝置批處理大小為 32 個樣本(總計 8*32=256),總訓練時間為 8 小時 53 分鐘(您可以在此處檢視此執行的 TensorBoard 日誌)。
我們在 Gaudi2 上以相同的超引數重新運行了相同的指令碼,總訓練時間為 2 小時 55 分鐘(檢視此處的日誌)。這意味著 Gaudi2 在不改變任何設定的情況下實現了 3.04 倍的加速。
由於 Gaudi2 的每個裝置記憶體容量大約是第一代 Gaudi 的 3 倍,因此可以利用更大的容量來處理更大的批次。這將使 HPU 有更多的工作要做,同時也能讓開發者嘗試一系列第一代 Gaudi 無法實現的超引數值。在每個裝置批處理大小為 64 個樣本(總計 512 個)的情況下,我們在 20k 步實現了與之前 65k 步執行相似的損失收斂。總訓練時間為 1 小時 33 分鐘(檢視此處的日誌)。在此配置下,吞吐量提高了 1.16 倍,同時新的批處理大小顯著加速了收斂。總的來說,與第一代 Gaudi 相比,Gaudi2 的總訓練時間縮短了 5.75 倍,吞吐量提高了 3.53 倍。
Gaudi2 也比 A100 更快:批處理大小為 32 時,Gaudi2 為 1580.2 樣本/秒,A100 為 981.6 樣本/秒;批處理大小為 64 時,Gaudi2 為 1835.8 樣本/秒,A100 為 1082.6 樣本/秒,這與 Habana 宣佈的 BERT 預訓練第一階段批處理大小為 64 時加速 1.8 倍的結果一致。
下表顯示了第一代 Gaudi、Gaudi2 和 Nvidia A100 80GB GPU 的吞吐量
| 第一代 Gaudi (BS=32) | Gaudi2 (BS=32) | Gaudi2 (BS=64) | A100 (BS=32) | A100 (BS=64) | |
|---|---|---|---|---|---|
| 吞吐量(樣本/秒) | 520.2 | 1580.2 | 1835.8 | 981.6 | 1082.6 |
| 加速比 | x1.0 | x3.04 | x3.53 | x1.89 | x2.08 |
BS 為每個裝置的批處理大小。Gaudi 執行在混合精度 (bf16/fp32) 下進行,A100 執行在 fp16 下進行。所有執行均為 分散式 執行,使用 8 個裝置。
使用 Stable Diffusion 從文字生成影像
🤗 Optimum Habana 1.3 版本的主要新功能之一是對 Stable Diffusion 的支援。現在在 Gaudi 上從文字生成影像變得非常容易。與在 GPU 上使用 🤗 Diffusers 不同,影像是批次生成的。由於模型編譯時間,前兩個批次會比後續迭代慢。在此基準測試中,這些前兩次迭代被丟棄,以計算第一代 Gaudi 和 Gaudi2 的吞吐量。
此指令碼以 8 個樣本的批處理大小執行。它使用 Habana/stable-diffusion Gaudi 配置。
我們得到的結果與 Habana 此處釋出的資料一致,如下表所示。Gaudi2 展示的延遲比第一代 Gaudi 快 3.51 倍(3.25 秒對比 0.925 秒),比 Nvidia A100 快 2.84 倍(2.63 秒對比 0.925 秒)。它還可以支援更大的批處理大小。
| 第一代 Gaudi (BS=8) | Gaudi2 (BS=8) | A100 (BS=1) | |
|---|---|---|---|
| 延遲(秒/圖) | 3.25 | 0.925 | 2.63 |
| 加速比 | x1.0 | x3.51 | x1.24 |
更新:以上資料已更新,因為 SynapseAI 1.10 和 Optimum Habana 1.6 在第一代 Gaudi 和 Gaudi2 上帶來了額外的加速。
BS 為批處理大小。Gaudi 執行在 bfloat16 精度下進行,A100 執行在 fp16 精度下(更多資訊請參閱此處)。所有執行均為 單裝置 執行。
微調 T5-3B
Gaudi2 每個裝置擁有 96 GB 記憶體,可以執行更大的模型。例如,我們成功地微調了 T5-3B(包含 30 億引數),其中唯一的記憶體最佳化是梯度檢查點。這在第一代 Gaudi 上是不可能的。這裡是此執行的日誌,模型使用此指令碼在 CNN DailyMail 資料集上進行文字摘要微調。
我們取得的結果如下表所示。Gaudi2 比 A100 80GB 快 2.44 倍。我們觀察到 Gaudi2 無法適應大於 1 的批處理大小。這是因為在執行的第一次迭代中,操作累積的圖所佔用的記憶體空間。Habana 正在努力最佳化未來 SynapseAI 版本中的記憶體佔用。我們期待使用新版本的 Habana SDK 和 DeepSpeed 來擴充套件此基準測試,看看趨勢是否保持不變。
| 第一代 Gaudi | Gaudi2 (BS=1) | A100 (BS=16) | |
|---|---|---|---|
| 吞吐量(樣本/秒) | 不適用 | 19.7 | 8.07 |
| 加速比 | / | x2.44 | x1.0 |
BS 為每個裝置的批處理大小。Gaudi2 和 A100 執行在 fp32 精度下,並啟用了梯度檢查點。所有執行均為 分散式 執行,使用 8 個裝置。
結論
在本文中,我們討論了我們對 Gaudi2 的首次體驗。由於 Habana 的 SDK SynapseAI 完全相容第一代 Gaudi 和 Gaudi2,因此從第一代 Gaudi 到 Gaudi2 的過渡完全無縫。這意味著未來版本提出的新最佳化將同時惠及它們。
您已經看到,Habana Gaudi2 顯著提高了第一代 Gaudi 的效能,並且在訓練和推理方面都提供了 Nvidia A100 80GB 大約兩倍的吞吐速度。
您現在也知道如何透過英特爾開發者專區設定 Gaudi2 例項。檢視您可以使用 🤗 Optimum Habana 輕鬆執行的示例。
如果您有興趣使用最新的 AI 硬體加速器和軟體庫來加速您的機器學習訓練和推理工作流程,請檢視我們的。要了解更多關於 Habana 解決方案的資訊,請在此處閱讀我們的合作關係並聯絡他們。要了解更多關於 Hugging Face 致力於使 AI 硬體加速器易於使用的努力,請檢視我們的硬體合作伙伴計劃。

