音訊課程文件
用於自動語音識別的預訓練模型
並獲得增強的文件體驗
開始使用
用於自動語音識別的預訓練模型
在本節中,我們將介紹如何使用 pipeline() 利用預訓練模型進行語音識別。在第二單元中,我們介紹了 pipeline() 是一種執行語音識別任務的簡單方法,它在內部處理所有預處理和後處理,並具有快速嘗試 Hugging Face Hub 上任何預訓練檢查點的靈活性。在本單元中,我們將深入探討語音識別模型的不同屬性,以及如何使用它們來處理一系列不同的任務。
如第三單元所述,語音識別模型大致分為兩類:
- 連線時序分類 (CTC):僅編碼器模型,頂部帶有線性分類 (CTC) 頭
- 序列到序列 (Seq2Seq):編碼器-解碼器模型,編碼器和解碼器之間具有交叉注意力機制
2022 年之前,CTC 是這兩種架構中更受歡迎的一種,Wav2Vec2、HuBERT 和 XLSR 等僅編碼器模型在語音的預訓練/微調正規化中取得了突破。Meta 和 Microsoft 等大型公司在大量未標記的音訊資料上預訓練編碼器多天或數週。然後,使用者可以獲取一個預訓練檢查點,並使用 CTC 頭在最少 10 分鐘的標記語音資料上對其進行微調,以在下游語音識別任務中獲得強大的效能。
然而,CTC 模型有其缺點。將一個簡單的線性層附加到編碼器會產生一個小型、快速的整體模型,但容易出現語音拼寫錯誤。我們將在下面為 Wav2Vec2 模型演示這一點。
探測 CTC 模型
讓我們載入 LibriSpeech ASR 資料集的一小部分,以演示 Wav2Vec2 的語音轉錄能力。
from datasets import load_dataset
dataset = load_dataset(
"hf-internal-testing/librispeech_asr_dummy", "clean", split="validation"
)
dataset輸出
Dataset({
features: ['file', 'audio', 'text', 'speaker_id', 'chapter_id', 'id'],
num_rows: 73
})我們可以選擇 73 個音訊樣本之一,並檢查音訊樣本和轉錄。
from IPython.display import Audio
sample = dataset[2]
print(sample["text"])
Audio(sample["audio"]["array"], rate=sample["audio"]["sampling_rate"])輸出
HE TELLS US THAT AT THIS FESTIVE SEASON OF THE YEAR WITH CHRISTMAS AND ROAST BEEF LOOMING BEFORE US SIMILES DRAWN FROM EATING AND ITS RESULTS OCCUR MOST READILY TO THE MIND好的!聖誕節和烤牛肉,聽起來很棒!🎄 選擇了一個數據樣本後,我們現在將一個微調檢查點載入到 pipeline() 中。為此,我們將使用在 100 小時 LibriSpeech 資料上微調的官方 Wav2Vec2 base 檢查點。
from transformers import pipeline
pipe = pipeline("automatic-speech-recognition", model="facebook/wav2vec2-base-100h")接下來,我們將從資料集中取一個示例,並將其原始資料傳遞給管道。由於 pipeline 會消耗我們傳遞給它的任何字典(這意味著它不能被重複使用),我們將傳遞資料的一個副本。這樣,我們就可以在以下示例中安全地重複使用相同的音訊樣本。
pipe(sample["audio"].copy())輸出
{"text": "HE TELLS US THAT AT THIS FESTIVE SEASON OF THE YEAR WITH CHRISTMAUS AND ROSE BEEF LOOMING BEFORE US SIMALYIS DRAWN FROM EATING AND ITS RESULTS OCCUR MOST READILY TO THE MIND"}我們可以看到 Wav2Vec2 模型在轉錄這個樣本方面做得相當好——乍一看,它總體上是正確的。讓我們將目標和預測並排放置,並突出顯示差異。
Target: HE TELLS US THAT AT THIS FESTIVE SEASON OF THE YEAR WITH CHRISTMAS AND ROAST BEEF LOOMING BEFORE US SIMILES DRAWN FROM EATING AND ITS RESULTS OCCUR MOST READILY TO THE MIND
Prediction: HE TELLS US THAT AT THIS FESTIVE SEASON OF THE YEAR WITH **CHRISTMAUS** AND **ROSE** BEEF LOOMING BEFORE US **SIMALYIS** DRAWN FROM EATING AND ITS RESULTS OCCUR MOST READILY TO THE MIND將目標文字與預測轉錄進行比較,我們可以看到所有單詞聽起來都正確,但有些拼寫不準確。例如
- CHRISTMAUS 對比 CHRISTMAS
- ROSE 對比 ROAST
- SIMALYIS 對比 SIMILES
這凸顯了 CTC 模型的缺點。CTC 模型本質上是一個“僅聲學”模型:它由一個編碼器組成,該編碼器從音訊輸入中形成隱藏狀態表示,以及一個將隱藏狀態對映到字元的線性層。
這意味著系統幾乎完全基於給定的聲學輸入(音訊的語音)進行預測,因此傾向於以語音方式轉錄音訊(例如,CHRISTMAUS)。它較少重視前後字母的語言建模上下文,因此容易出現語音拼寫錯誤。更智慧的模型會識別出 CHRISTMAUS 在英語詞彙中不是有效詞,並在預測時將其更正為 CHRISTMAS。我們的預測還缺少兩個重要特徵——大小寫和標點符號——這限制了模型轉錄對實際應用的有用性。
向 Seq2Seq 進階
歡迎 Seq2Seq 模型!正如第三單元中概述的那樣,Seq2Seq 模型由一個編碼器和一個透過交叉注意力機制連線的解碼器組成。編碼器扮演與之前相同的角色,計算音訊輸入的隱藏狀態表示,而解碼器扮演語言模型的角色。解碼器處理來自編碼器的隱藏狀態表示的整個序列,並生成相應的文字轉錄。透過對音訊輸入的全域性上下文,解碼器能夠在進行預測時使用語言建模上下文,即時糾正拼寫錯誤,從而避免語音預測問題。
Seq2Seq 模型有兩個缺點
- 它們的解碼速度天生較慢,因為解碼過程是分步進行的,而不是一次性完成
- 它們對資料需求更大,需要更多的訓練資料才能達到收斂
特別是,對大量訓練資料的需求一直是 Seq2Seq 語音架構發展中的一個瓶頸。帶標籤的語音資料很難獲得,當時最大的帶註釋資料集只有 10,000 小時。這一切在 2022 年 Whisper 釋出後發生了改變。Whisper 是 OpenAI 的 Alec Radford 等作者於 2022 年 9 月釋出的用於語音識別的預訓練模型。與完全在未標記音訊資料上預訓練的 CTC 前身不同,Whisper 在大量標記的音訊轉錄資料上進行了預訓練,精確地說,有 680,000 小時。
這比用於訓練 Wav2Vec 2.0 的未標記音訊資料(60,000 小時)多一個數量級。更重要的是,這 680,000 小時預訓練資料中有 117,000 小時是多語言(或“非英語”)資料。這導致了可以應用於 96 種以上語言的檢查點,其中許多被認為是低資源語言,這意味著該語言缺乏適合訓練的大量語料庫。
當擴充套件到 680,000 小時標記預訓練資料時,Whisper 模型表現出對許多資料集和領域的強大泛化能力。預訓練檢查點取得了與最先進的管道系統相媲美的結果,在 LibriSpeech 管道的 test-clean 子集上達到了近 3% 的詞錯誤率 (WER),並在 TED-LIUM 上創造了 4.7% WER 的新 SOTA(參見 Whisper 論文表 8)。
特別重要的是 Whisper 處理長音訊樣本的能力、對輸入噪聲的魯棒性以及預測帶大小寫和標點符號轉錄的能力。這使其成為真實世界語音識別系統的可行候選者。
本節的其餘部分將向您展示如何使用 🤗 Transformers 將預訓練的 Whisper 模型用於語音識別。在許多情況下,預訓練的 Whisper 檢查點效能極佳並能給出很好的結果,因此我們鼓勵您首先嚐試使用預訓練檢查點來解決任何語音識別問題。透過微調,預訓練檢查點可以針對特定資料集和語言進行調整,以進一步改進這些結果。我們將在即將到來的微調小節中演示如何做到這一點。
Whisper 檢查點有五種不同模型大小的配置。最小的四種僅在英語或多語言資料上進行訓練。最大的檢查點僅支援多語言。所有九個預訓練檢查點都可以在 Hugging Face Hub 上找到。下表總結了這些檢查點,並提供了 Hub 上模型的連結。“VRAM”表示以最小批處理大小 1 執行模型所需的 GPU 記憶體。“相對速度”是檢查點與最大模型相比的相對速度。根據這些資訊,您可以選擇最適合您硬體的檢查點。
| 大小 | 引數量 | 視訊記憶體 / GB | 相對速度 | 僅限英語 | 多語言 |
|---|---|---|---|---|---|
| 微型 | 39 M | 1.4 | 32 | ✓ | ✓ |
| 基礎 | 74 M | 1.5 | 16 | ✓ | ✓ |
| 小型 | 244 M | 2.3 | 6 | ✓ | ✓ |
| 中型 | 769 M | 4.2 | 2 | ✓ | ✓ |
| 大型 | 1550 M | 7.5 | 1 | X | ✓ |
讓我們載入 Whisper Base 檢查點,它的大小與我們之前使用的 Wav2Vec2 檢查點相當。為了預見我們將轉向多語言語音識別,我們將載入基礎檢查點的多語言變體。如果可用,我們還將把模型載入到 GPU 上,否則載入到 CPU 上。pipeline() 隨後將負責根據需要將所有輸入/輸出從 CPU 移動到 GPU。
import torch
from transformers import pipeline
device = "cuda:0" if torch.cuda.is_available() else "cpu"
pipe = pipeline(
"automatic-speech-recognition", model="openai/whisper-base", device=device
)太好了!現在像以前一樣轉錄音訊。我們所做的唯一更改是傳遞一個額外的引數 max_new_tokens,它告訴模型在進行預測時要生成的最大 token 數量。
pipe(sample["audio"], max_new_tokens=256)輸出
{'text': ' He tells us that at this festive season of the year, with Christmas and roast beef looming before us, similarly is drawn from eating and its results occur most readily to the mind.'}夠簡單吧!你會注意到的第一件事是大小寫和標點符號的存在。這使得轉錄比 Wav2Vec2 的無大小寫和無標點符號的轉錄更容易閱讀。讓我們將轉錄與目標並排放置。
Target: HE TELLS US THAT AT THIS FESTIVE SEASON OF THE YEAR WITH CHRISTMAS AND ROAST BEEF LOOMING BEFORE US SIMILES DRAWN FROM EATING AND ITS RESULTS OCCUR MOST READILY TO THE MIND
Prediction: He tells us that at this festive season of the year, with **Christmas** and **roast** beef looming before us, **similarly** is drawn from eating and its results occur most readily to the mind.Whisper 在糾正我們從 Wav2Vec2 看到的發音錯誤方面做得非常出色——Christmas 和 roast 都拼寫正確。我們看到模型仍然在 SIMILES 上掙扎,被錯誤地轉錄為 similarly,但這次預測是英語詞彙中的有效詞。使用更大的 Whisper 檢查點可以進一步減少轉錄錯誤,代價是需要更多的計算和更長的轉錄時間。
我們已經承諾了一個能夠處理 96 種語言的模型,所以現在讓我們暫時離開英語語音識別,走向全球🌎!多語言 LibriSpeech (MLS) 資料集是 LibriSpeech 資料集的相應多語言版本,包含六種語言的帶標籤音訊資料。我們將從 MLS 資料集的西班牙語部分載入一個樣本,使用流式模式,這樣我們就無需下載整個資料集。
dataset = load_dataset(
"facebook/multilingual_librispeech", "spanish", split="validation", streaming=True
)
sample = next(iter(dataset))再次,我們將檢查文字轉錄並聽取音訊片段。
print(sample["text"])
Audio(sample["audio"]["array"], rate=sample["audio"]["sampling_rate"])輸出
entonces te delelitarás en jehová y yo te haré subir sobre las alturas de la tierra y te daré á comer la heredad de jacob tu padre porque la boca de jehová lo ha hablado這就是我們希望透過 Whisper 轉錄實現的目標文字。儘管我們現在知道我們可能會做得更好,因為我們的模型還將預測標點符號和大小寫,而這些在參考中都不存在。讓我們將音訊樣本轉發給管道以獲取我們的文字預測。需要注意的一點是,管道會消耗我們輸入的音訊輸入字典,這意味著該字典無法重複使用。為了避免這種情況,我們將傳遞音訊樣本的副本,這樣我們就可以在後續的程式碼示例中重複使用相同的音訊樣本。
pipe(sample["audio"].copy(), max_new_tokens=256, generate_kwargs={"task": "transcribe"})輸出
{'text': ' Entonces te deleitarás en Jehová y yo te haré subir sobre las alturas de la tierra y te daré a comer la heredad de Jacob tu padre porque la boca de Jehová lo ha hablado.'}太棒了——這看起來與我們的參考文字非常相似(可以說更好,因為它有標點符號和大小寫!)。你會注意到我們將 "task" 作為生成關鍵字引數 (generate kwarg) 轉發。將 "task" 設定為 "transcribe" 會強制 Whisper 執行語音識別任務,其中音訊會以語音所用的相同語言進行轉錄。Whisper 也能夠執行密切相關的語音翻譯任務,其中西班牙語音訊可以翻譯成英語文字。為了實現這一點,我們將 "task" 設定為 "translate"。
pipe(sample["audio"], max_new_tokens=256, generate_kwargs={"task": "translate"})輸出
{'text': ' So you will choose in Jehovah and I will raise you on the heights of the earth and I will give you the honor of Jacob to your father because the voice of Jehovah has spoken to you.'}既然我們知道可以在語音識別和語音翻譯之間切換,我們就可以根據自己的需求選擇任務。我們可以將語言 X 中的音訊識別為相同語言 X 的文字(例如,西班牙語音訊到西班牙語文字),或者將任何語言 X 的音訊翻譯為英語文字(例如,西班牙語音訊到英語文字)。
要了解有關如何使用 "task" 引數控制生成文字屬性的更多資訊,請參閱 Whisper 基礎模型的模型卡。
長篇轉錄和時間戳
到目前為止,我們一直專注於轉錄少於 30 秒的短音訊樣本。我們提到 Whisper 的一個吸引力在於其處理長音訊樣本的能力。我們將在本節中處理此任務!
讓我們透過連線 MLS 資料集中的順序樣本來建立一個長音訊檔案。由於 MLS 資料集是透過將長有聲讀物錄音分成較短的片段來整理的,因此連線樣本是重建較長有聲讀物片段的一種方法。因此,生成的音訊在整個樣本中應該是一致的。
我們將目標音訊長度設定為 5 分鐘,並在達到此值後停止連線樣本。
import numpy as np
target_length_in_m = 5
# convert from minutes to seconds (* 60) to num samples (* sampling rate)
sampling_rate = pipe.feature_extractor.sampling_rate
target_length_in_samples = target_length_in_m * 60 * sampling_rate
# iterate over our streaming dataset, concatenating samples until we hit our target
long_audio = []
for sample in dataset:
long_audio.extend(sample["audio"]["array"])
if len(long_audio) > target_length_in_samples:
break
long_audio = np.asarray(long_audio)
# how did we do?
seconds = len(long_audio) / 16000
minutes, seconds = divmod(seconds, 60)
print(f"Length of audio sample is {minutes} minutes {seconds:.2f} seconds")輸出
Length of audio sample is 5.0 minutes 17.22 seconds好的!5 分 17 秒的音訊需要轉錄。將這個長音訊樣本直接轉發給模型存在兩個問題:
- Whisper 本身就是為處理 30 秒的樣本而設計的:任何短於 30 秒的都會用靜音填充到 30 秒,任何長於 30 秒的都會透過截斷多餘的音訊來截斷到 30 秒,所以如果我們將音訊直接傳入,我們將只得到前 30 秒的轉錄。
- Transformer 網路中的記憶體隨序列長度的平方而縮放:輸入長度加倍,記憶體需求就翻兩番,因此傳入超長音訊檔案必然會導致記憶體不足 (OOM) 錯誤。
🤗 Transformers 中長篇轉錄的工作方式是分塊將輸入音訊分割成更小、更易於管理的片段。每個片段與前一個片段有少量重疊。這使得我們能夠準確地在邊界處將片段重新拼接在一起,因為我們可以找到片段之間的重疊並相應地合併轉錄。
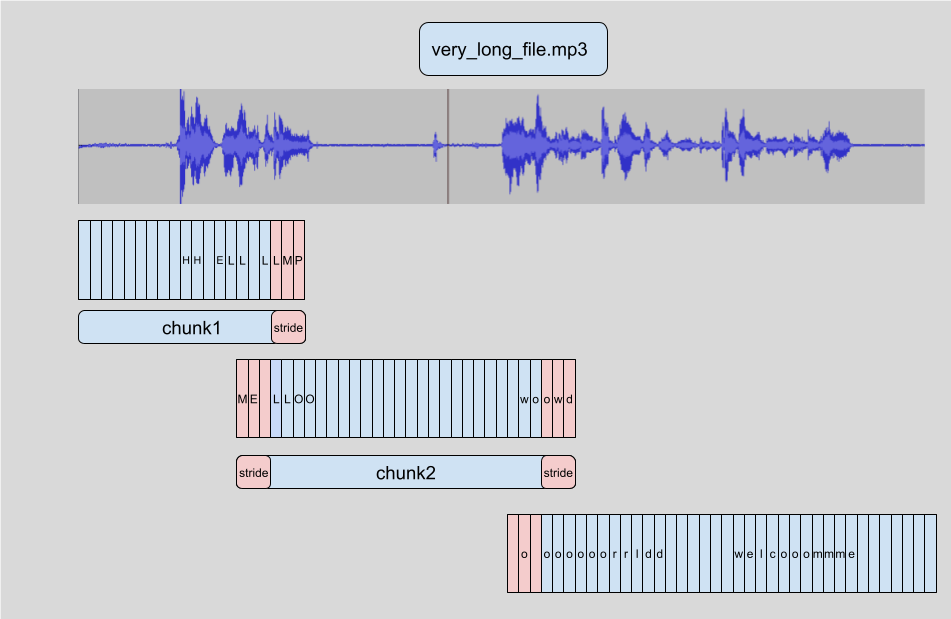
分塊樣本的優點是我們不需要塊的結果來轉錄後續塊。拼接是在我們轉錄完所有塊的塊邊界處完成的,所以我們以何種順序轉錄塊並不重要。演算法完全是無狀態的,所以我們甚至可以同時進行塊和塊!這使我們能夠批次處理這些塊,並並行地將它們透過模型,與順序轉錄相比,大大提高了計算速度。要了解有關 🤗 Transformers 中分塊的更多資訊,您可以參考這篇部落格文章。
要啟用長篇轉錄,我們在呼叫管道時必須新增一個額外的引數。這個引數 chunk_length_s 控制分塊片段的長度(秒)。對於 Whisper,30 秒的塊是最佳的,因為這與 Whisper 預期的輸入長度相匹配。
要啟用批處理,我們需要向管道傳遞引數 batch_size。綜合起來,我們可以使用分塊和批處理來轉錄長音訊樣本,如下所示:
pipe(
long_audio,
max_new_tokens=256,
generate_kwargs={"task": "transcribe"},
chunk_length_s=30,
batch_size=8,
)輸出
{'text': ' Entonces te deleitarás en Jehová, y yo te haré subir sobre las alturas de la tierra, y te daré a comer la
heredad de Jacob tu padre, porque la boca de Jehová lo ha hablado. nosotros curados. Todos nosotros nos descarriamos
como bejas, cada cual se apartó por su camino, mas Jehová cargó en él el pecado de todos nosotros...我們不會在這裡列印整個輸出,因為它太長了(總共 312 個單詞)!在 16GB V100 GPU 上,您可以預期上述程式碼行大約需要 3.45 秒才能執行,對於 317 秒的音訊樣本來說,這已經相當不錯了。在 CPU 上,預計接近 30 秒。
Whisper 也能夠預測音訊資料的分段時間戳。這些時間戳指示一小段音訊的開始和結束時間,對於將轉錄與輸入音訊對齊特別有用。假設我們要為影片提供字幕——我們需要這些時間戳來知道轉錄的哪一部分對應影片的特定片段,以便在該時間顯示正確的轉錄。
啟用時間戳預測很簡單,我們只需要將引數 return_timestamps=True 設定為 true。時間戳與我們之前使用的分塊和批處理方法都相容,因此我們可以簡單地將時間戳引數附加到我們之前的呼叫中。
pipe(
long_audio,
max_new_tokens=256,
generate_kwargs={"task": "transcribe"},
chunk_length_s=30,
batch_size=8,
return_timestamps=True,
)["chunks"]輸出
[{'timestamp': (0.0, 26.4),
'text': ' Entonces te deleitarás en Jehová, y yo te haré subir sobre las alturas de la tierra, y te daré a comer la heredad de Jacob tu padre, porque la boca de Jehová lo ha hablado. nosotros curados. Todos nosotros nos descarriamos como bejas, cada cual se apartó por su camino,'},
{'timestamp': (26.4, 32.48),
'text': ' mas Jehová cargó en él el pecado de todos nosotros. No es que partas tu pan con el'},
{'timestamp': (32.48, 38.4),
'text': ' hambriento y a los hombres herrantes metas en casa, que cuando vieres al desnudo lo cubras y no'},
...瞧!我們得到了預測的文字以及相應的時間戳。
總結
Whisper 是一款強大的預訓練語音識別和翻譯模型。與 Wav2Vec2 相比,它具有更高的轉錄準確性,輸出包含標點符號和大小寫。它可用於轉錄英語以及其他 96 種語言的語音,無論是短音訊片段還是透過分塊處理的長音訊片段。這些特性使其成為許多語音識別和翻譯任務的可行模型,無需進行微調。pipeline() 方法提供了一種簡單的方式,透過一行 API 呼叫進行推理,並可控制生成的預測。
儘管 Whisper 模型在許多高資源語言上表現出色,但它在低資源語言(即那些訓練資料較少可用的語言)上的轉錄和翻譯準確性較低。在某些語言的不同口音和方言之間也存在不同的效能,包括對不同性別、種族、年齡或其他人口統計學標準的說話者的準確性較低(參見 Whisper 論文)。
為了提升在低資源語言、口音或方言上的效能,我們可以使用預訓練的 Whisper 模型,並在一個小規模的、適當選擇的資料集上對其進行訓練,這個過程稱為微調。我們將展示,僅用少至十小時的額外資料,我們就可以將 Whisper 模型在低資源語言上的效能提高 100% 以上。在下一節中,我們將介紹選擇用於微調的資料集的過程。
< > 在 GitHub 上更新