英特爾與Hugging Face合作,推動機器學習硬體加速普及化


Hugging Face的使命是普及優秀的機器學習技術,並最大限度地發揮其在各行各業和社會中的積極影響。我們不僅致力於推動Transformer模型的發展,還在努力簡化其應用。
今天,我們很高興地宣佈,英特爾已正式加入我們的硬體合作伙伴計劃。得益於Optimum開源庫,英特爾和Hugging Face將合作構建最先進的硬體加速技術,用於Transformer模型的訓練、微調和預測。
Transformer模型日益龐大和複雜,這可能給對延遲敏感的應用程式(如搜尋或聊天機器人)帶來生產挑戰。不幸的是,延遲最佳化長期以來一直是機器學習(ML)從業者面臨的難題。即使對底層框架和硬體平臺有深入瞭解,也需要大量的試錯才能找出要利用的“旋鈕”和功能。
英特爾透過Intel Xeon Scalable CPU平臺和各種硬體最佳化的AI軟體工具、框架和庫,為加速AI提供了完整的解決方案。因此,Hugging Face和英特爾攜手合作,共同構建強大的模型最佳化工具,使使用者在英特爾平臺上實現最佳效能、規模和生產力,這是水到渠成的事情。
“*我們很高興與Hugging Face合作,透過開源整合和整合的開發者體驗,將英特爾至強硬體和英特爾AI軟體的最新創新帶給Transformer社群。*” 英特爾副總裁兼AI與分析總經理魏立表示。
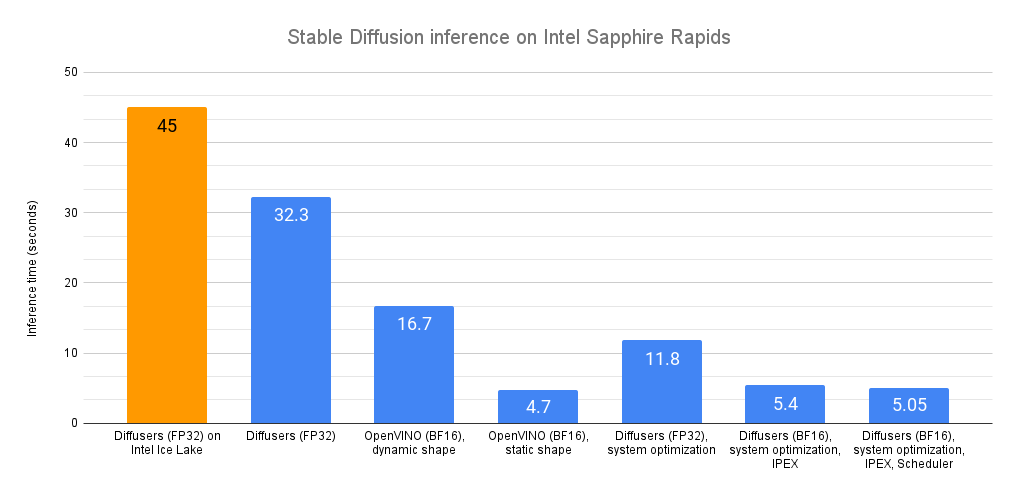
近幾個月來,英特爾和Hugging Face在擴充套件Transformer工作負載方面進行了合作。我們釋出了關於推理(第1部分,第2部分)的詳細調優指南和基準測試,並在最新的英特爾至強冰湖CPU上實現了DistilBERT的個位數毫秒級延遲。在訓練方面,我們增加了對Habana Gaudi加速器的支援,其價效比比GPU高出40%。
下一步自然是擴充套件這項工作並與機器學習社群分享。請看Optimum Intel開源庫!讓我們深入瞭解一下。
使用Optimum Intel實現Transformers效能巔峰
Optimum是由Hugging Face建立的一個開源庫,旨在簡化Transformer在不斷增長的訓練和推理裝置上的加速。憑藉內建的最佳化技術,您可以使用現成的指令碼,或對現有程式碼進行少量修改,在幾分鐘內開始加速您的工作負載。初學者可以開箱即用Optimum並獲得出色的結果。專家可以繼續調整以獲得最大效能。
Optimum Intel是Optimum的一部分,並基於Intel Neural Compressor(INC)構建。INC是一個開源庫,為流行的網路壓縮技術(如量化、剪枝和知識蒸餾)在多個深度學習框架上提供統一介面。該工具支援自動的精度驅動調優策略,幫助使用者快速構建最佳量化模型。
藉助Optimum Intel,您可以以最小的努力將最先進的最佳化技術應用於您的Transformer。讓我們看一個完整的例子。
案例研究:使用Optimum Intel量化DistilBERT
在這個例子中,我們將對一個經過微調用於分類的DistilBERT模型進行訓練後量化。量化是透過減少模型引數的位寬來縮小記憶體和計算需求的過程。例如,您通常可以用8位整數替換32位浮點引數,但會犧牲預測精度的一小部分。
我們已經微調了原始模型,根據星級(1到5星)對鞋子產品評論進行分類。您可以在Hugging Face Hub上檢視此模型及其量化版本。您還可以在此Space中測試原始模型。
讓我們開始吧!所有程式碼都可以在此筆記本中找到。
像往常一樣,第一步是安裝所有必需的庫。值得一提的是,我們需要使用PyTorch的僅CPU版本才能使量化過程正常工作。
pip -q uninstall torch -y
pip -q install torch==1.11.0+cpu --extra-index-url https://download.pytorch.org/whl/cpu
pip -q install transformers datasets optimum[neural-compressor] evaluate --upgrade
然後,我們準備一個評估資料集,以在量化過程中評估模型效能。從我們用於微調原始模型的資料集開始,我們只保留幾千條評論及其標籤,並將它們儲存到本地儲存。
接下來,我們從Hugging Face Hub載入原始模型、其tokenizer和評估資料集。
from datasets import load_dataset
from transformers import AutoModelForSequenceClassification, AutoTokenizer
model_name = "juliensimon/distilbert-amazon-shoe-reviews"
model = AutoModelForSequenceClassification.from_pretrained(model_name, num_labels=5)
tokenizer = AutoTokenizer.from_pretrained(model_name)
eval_dataset = load_dataset("prashantgrao/amazon-shoe-reviews", split="test").select(range(300))
接下來,我們定義一個評估函式,用於計算評估資料集上的模型指標。這使得Optimum Intel庫能夠在量化前後比較這些指標。為此,Hugging Face的evaluate庫非常方便!
import evaluate
def eval_func(model):
task_evaluator = evaluate.evaluator("text-classification")
results = task_evaluator.compute(
model_or_pipeline=model,
tokenizer=tokenizer,
data=eval_dataset,
metric=evaluate.load("accuracy"),
label_column="labels",
label_mapping=model.config.label2id,
)
return results["accuracy"]
然後,我們使用[配置]設定量化任務。您可以在Neural Compressor的文件中找到此配置的詳細資訊。這裡,我們選擇訓練後動態量化,可接受的精度下降為5%。如果精度下降超過允許的5%,則模型的不同部分將被量化,直到精度下降達到可接受範圍,或者達到最大嘗試次數(此處設定為10)。
from neural_compressor.config import AccuracyCriterion, PostTrainingQuantConfig, TuningCriterion
tuning_criterion = TuningCriterion(max_trials=10)
accuracy_criterion = AccuracyCriterion(tolerable_loss=0.05)
# Load the quantization configuration detailing the quantization we wish to apply
quantization_config = PostTrainingQuantConfig(
approach="dynamic",
accuracy_criterion=accuracy_criterion,
tuning_criterion=tuning_criterion,
)
現在我們可以啟動量化任務,並將生成的模型及其配置檔案儲存到本地儲存。
from neural_compressor.config import PostTrainingQuantConfig
from optimum.intel.neural_compressor import INCQuantizer
# The directory where the quantized model will be saved
save_dir = "./model_inc"
quantizer = INCQuantizer.from_pretrained(model=model, eval_fn=eval_func)
quantizer.quantize(quantization_config=quantization_config, save_directory=save_dir)
日誌告訴我們,Optimum Intel已經量化了38個`Linear`和2個`Embedding`運算子。
[INFO] |******Mixed Precision Statistics*****|
[INFO] +----------------+----------+---------+
[INFO] | Op Type | Total | INT8 |
[INFO] +----------------+----------+---------+
[INFO] | Embedding | 2 | 2 |
[INFO] | Linear | 38 | 38 |
[INFO] +----------------+----------+---------+
比較原始模型的第一層(`model.distilbert.transformer.layer[0]`)及其量化版本(`inc_model.distilbert.transformer.layer[0]`),我們看到`Linear`確實已被其量化等效物`DynamicQuantizedLinear`取代。
# Original model
TransformerBlock(
(attention): MultiHeadSelfAttention(
(dropout): Dropout(p=0.1, inplace=False)
(q_lin): Linear(in_features=768, out_features=768, bias=True)
(k_lin): Linear(in_features=768, out_features=768, bias=True)
(v_lin): Linear(in_features=768, out_features=768, bias=True)
(out_lin): Linear(in_features=768, out_features=768, bias=True)
)
(sa_layer_norm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(ffn): FFN(
(dropout): Dropout(p=0.1, inplace=False)
(lin1): Linear(in_features=768, out_features=3072, bias=True)
(lin2): Linear(in_features=3072, out_features=768, bias=True)
)
(output_layer_norm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
)
# Quantized model
TransformerBlock(
(attention): MultiHeadSelfAttention(
(dropout): Dropout(p=0.1, inplace=False)
(q_lin): DynamicQuantizedLinear(in_features=768, out_features=768, dtype=torch.qint8, qscheme=torch.per_channel_affine)
(k_lin): DynamicQuantizedLinear(in_features=768, out_features=768, dtype=torch.qint8, qscheme=torch.per_channel_affine)
(v_lin): DynamicQuantizedLinear(in_features=768, out_features=768, dtype=torch.qint8, qscheme=torch.per_channel_affine)
(out_lin): DynamicQuantizedLinear(in_features=768, out_features=768, dtype=torch.qint8, qscheme=torch.per_channel_affine)
)
(sa_layer_norm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(ffn): FFN(
(dropout): Dropout(p=0.1, inplace=False)
(lin1): DynamicQuantizedLinear(in_features=768, out_features=3072, dtype=torch.qint8, qscheme=torch.per_channel_affine)
(lin2): DynamicQuantizedLinear(in_features=3072, out_features=768, dtype=torch.qint8, qscheme=torch.per_channel_affine)
)
(output_layer_norm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
)
很好,但這如何影響準確性和預測時間呢?
在每個量化步驟之前和之後,Optimum Intel都會對當前模型執行評估函式。量化模型的精度現在略低於原始模型(`0.546` vs. `0.574`)。我們還看到量化模型的評估步驟比原始模型快1.34倍。對於幾行程式碼來說,這已經很不錯了!
[INFO] |**********************Tune Result Statistics**********************|
[INFO] +--------------------+----------+---------------+------------------+
[INFO] | Info Type | Baseline | Tune 1 result | Best tune result |
[INFO] +--------------------+----------+---------------+------------------+
[INFO] | Accuracy | 0.5740 | 0.5460 | 0.5460 |
[INFO] | Duration (seconds) | 13.1534 | 9.7695 | 9.7695 |
[INFO] +--------------------+----------+---------------+------------------+
您可以在Hugging Face Hub上找到生成的模型。要載入託管在本地或🤗 Hub上的量化模型,您可以這樣做:
from optimum.intel.neural_compressor import INCModelForSequenceClassification
inc_model = INCModelForSequenceClassification.from_pretrained(save_dir)
我們才剛剛開始
在這個例子中,我們向您展示瞭如何使用Optimum Intel輕鬆地對模型進行訓練後量化,這僅僅是個開始。該庫還支援其他型別的量化以及剪枝,這是一種將對預測結果影響很小或沒有影響的模型引數置零或移除的技術。
我們很高興能與英特爾合作,為Hugging Face使用者帶來最新英特爾至強CPU和英特爾AI庫的最高效率。請給Optimum Intel點贊以獲取更新,並敬請期待更多即將推出的功能!
非常感謝Ella Charlaix在這篇文章中提供的幫助。