Hugging Face 的夏天 😎

夏天正式結束了,Hugging Face 的這幾個月相當忙碌。從 Hub 的新功能到研究和開源開發,我們的團隊一直努力透過開放和協作的技術賦能社群。
在這篇部落格文章中,您將瞭解 Hugging Face 在 6 月、7 月和 8 月發生的所有事情!

這篇帖子涵蓋了我們團隊正在努力的廣泛領域,所以不要猶豫,直接跳到您最感興趣的部分 🤗
新功能
在過去的幾個月裡,Hub 上的公共模型倉庫從 10,000 個增加到 16,000 多個模型!感謝我們的社群與世界分享了這麼多令人驚歎的模型。除了數量,我們還有大量酷炫的新功能與您分享!
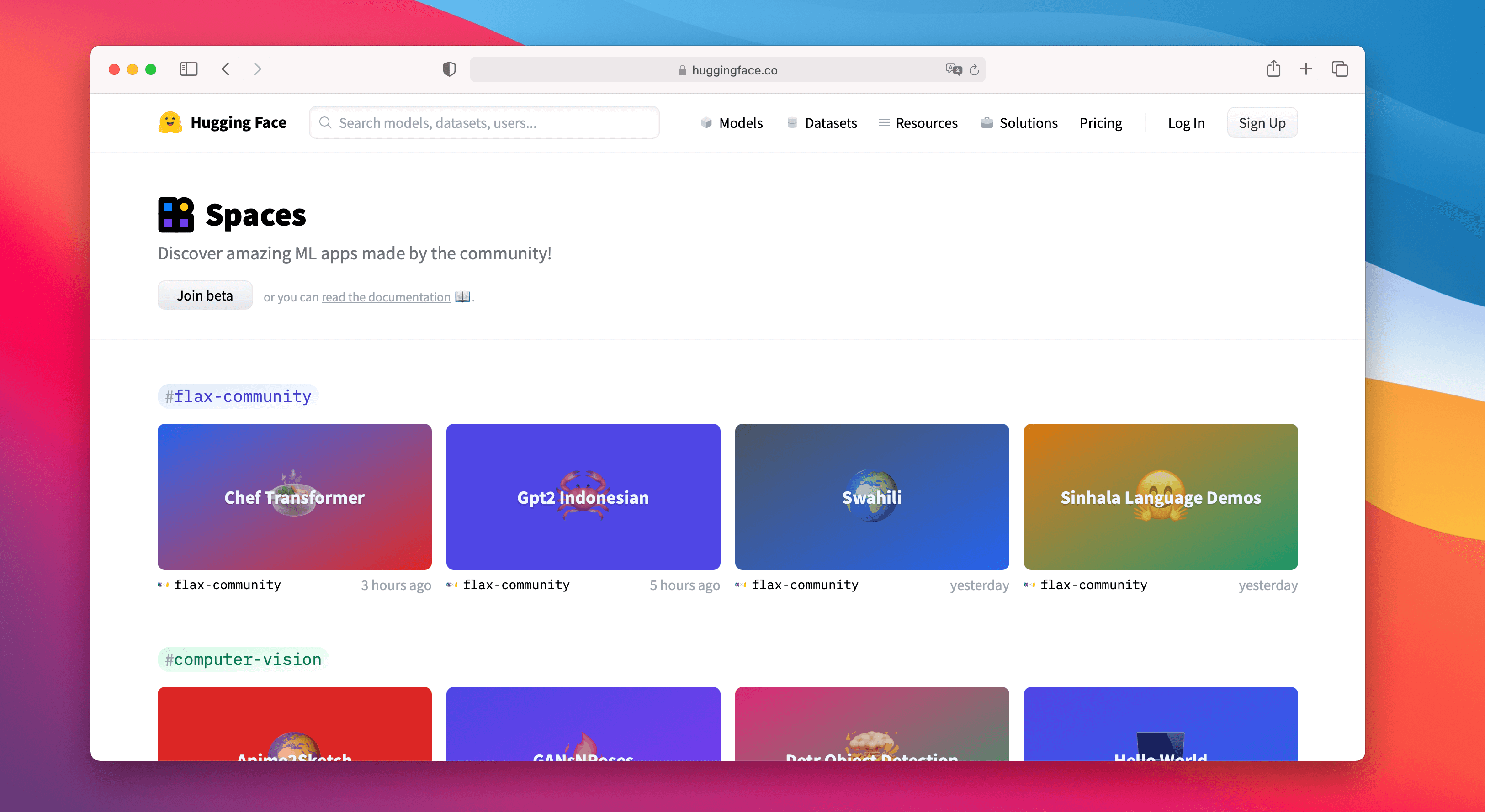
Spaces Beta ()
Spaces 是一種簡單免費的解決方案,可以直接在您的使用者個人資料或組織 hf.co 個人資料上託管機器學習演示應用程式。我們支援兩個很棒的 SDK,讓您可以使用 Python 輕鬆構建酷炫的應用程式:Gradio 和 Streamlit。您可以在幾分鐘內部署一個應用程式並與社群分享!🚀
Spaces 允許您設定機密,允許自定義要求,甚至可以直接從 GitHub 倉庫進行管理。您可以在 註冊 Beta 版。以下是我們最喜歡的一些!
- 在 Chef Transformer 的幫助下建立食譜
- 使用 HuBERT 將語音轉錄為文字
- 使用 DINO 模型在影片中進行分割
- 使用 Paint Transformer 根據給定的圖片創作繪畫
- 或者您可以探索任何一個現有 !
分享愛意
您現在可以在 https://huggingface.co 上點贊任何模型、資料集或 Space,這意味著您可以與社群分享愛意 ❤️。您還可以透過點選點贊框👀來關注誰喜歡什麼。去點贊您自己的倉庫吧,我們不會評判 😉。

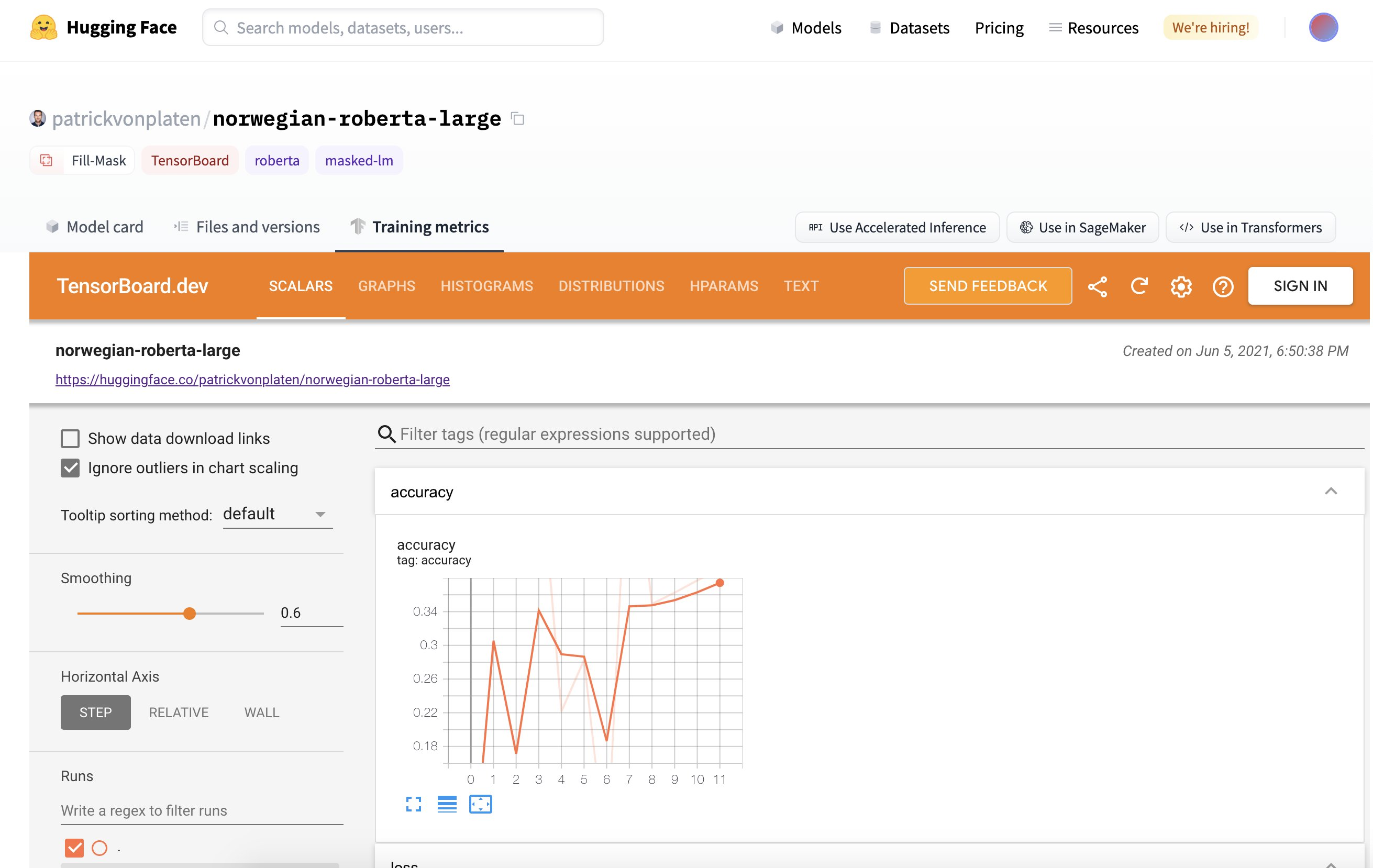
TensorBoard 整合
6 月下旬,我們為所有模型推出了 TensorBoard 整合。如果倉庫中有 TensorBoard 跟蹤,就會自動為您啟動一個免費的 TensorBoard 例項。這適用於公共和私有倉庫以及任何具有 TensorBoard 跟蹤的庫!
指標
7 月,我們增加了在模型倉庫中列出評估指標的功能,只需將它們新增到模型卡中即可📈。如果您在模型卡的 model-index 部分新增評估指標,它們將自豪地顯示在您的模型倉庫中。
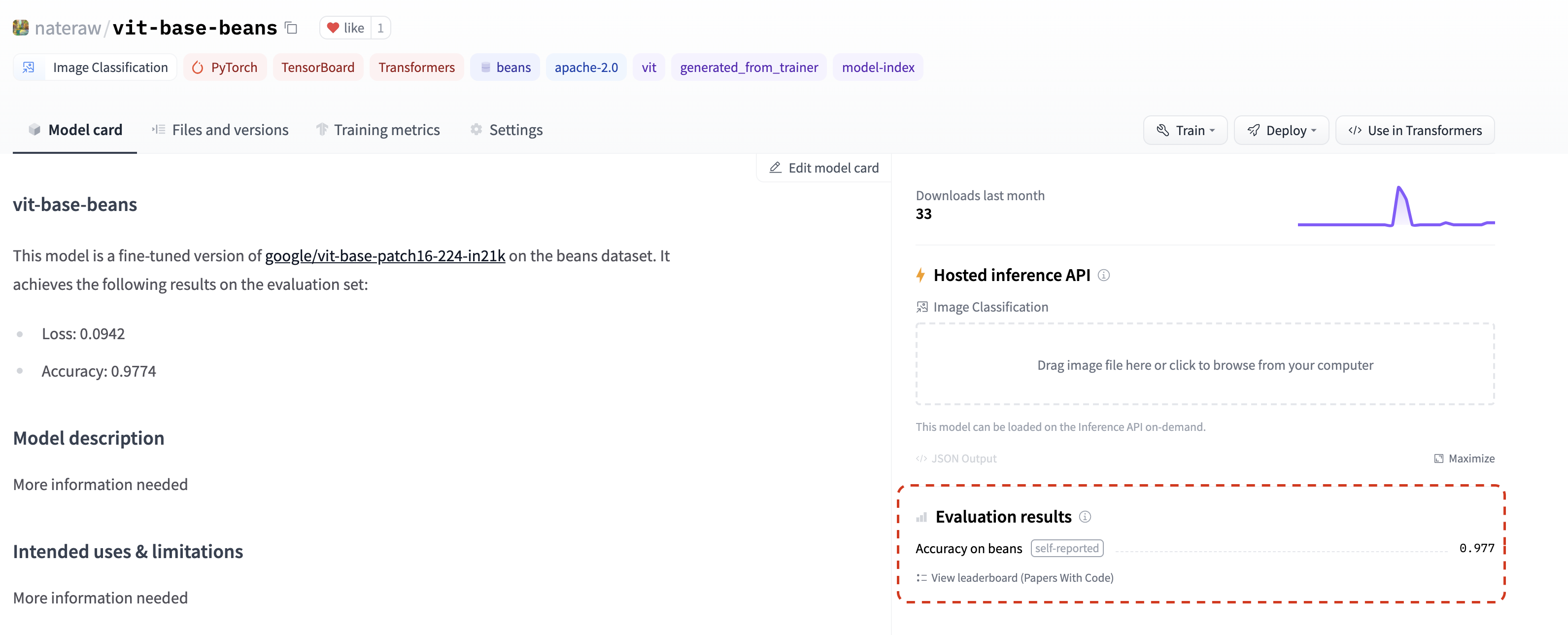
如果這還不夠,這些指標將自動連結到相應的 Papers With Code 排行榜。這意味著您一旦在 Hub 上分享您的模型,就可以與社群中的其他人並排比較您的結果。💪
檢視 這個倉庫 作為示例,密切關注其 模型卡 的 model-index 部分,瞭解如何自行操作並 自動 在 Papers with Code 中找到指標。
新部件
Hub 有 18 個小部件,允許使用者直接在瀏覽器中試用模型。
隨著我們最新與 Sentence Transformers 的整合,我們還引入了兩個新部件:特徵提取和句子相似度。
最新的音訊分類小部件實現了許多酷炫的用例:語言識別、街道聲音檢測 🚨、命令識別、說話人識別等等!您今天就可以使用 transformers 和 speechbrain 模型來嘗試!🔊 (請注意,當您嘗試某些模型時,您可能需要大聲吠叫)
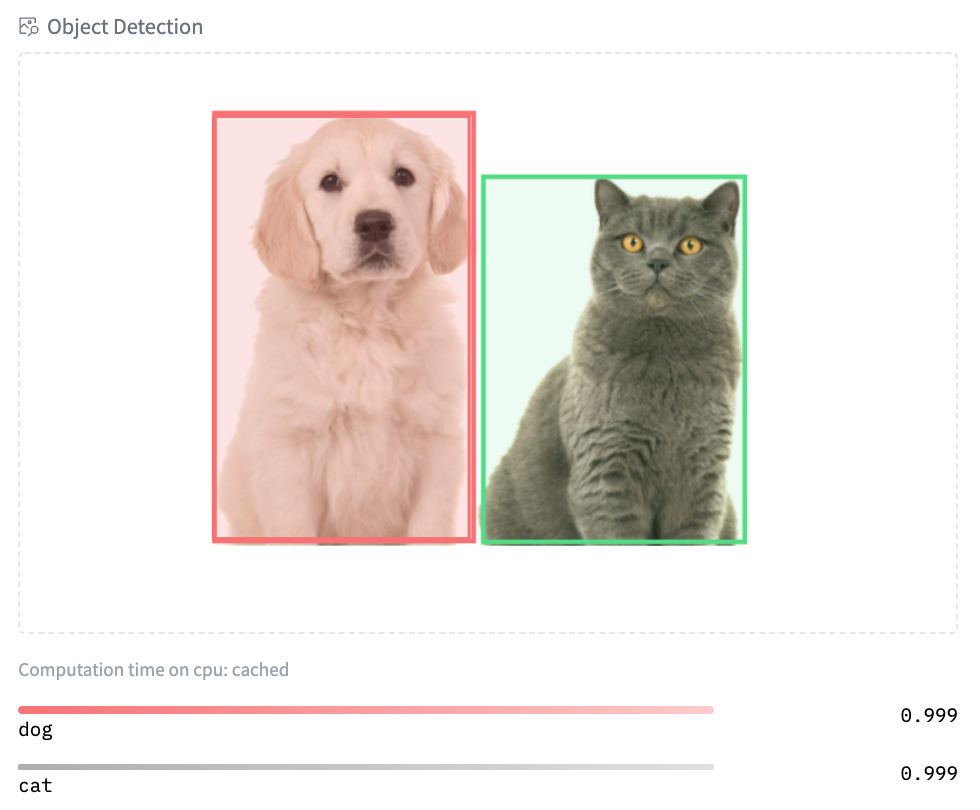
您可以試用我們使用 Scikit-learn 的 結構化資料分類 的早期演示。最後,我們還為影像相關模型引入了新部件:文字到影像、影像分類和物件檢測。在這裡 嘗試 Google 的 ViT 模型的影像分類,在這裡 嘗試 Facebook AI 的 DETR 模型的物件檢測!
更多功能
這並非 Hub 發生的全部。我們已經引入了新的、改進的 Hub 文件。我們還引入了兩個廣泛請求的功能:使用者現在可以轉移/重新命名倉庫,並直接將新檔案上傳到 Hub。
社群
Hugging Face 課程
6 月,我們推出了 免費線上課程 的第一部分!本課程教授您有關 🤗 生態系統的所有知識:Transformers、Tokenizers、Datasets、Accelerate 和 Hub。您還可以在我們庫的官方文件中找到課程連結。所有章節的直播課程都可以在我們的 YouTube 頻道 上找到。敬請期待我們將在今年晚些時候推出的課程的下一部分!
JAX/FLAX 衝刺
7 月,我們舉辦了有史以來規模最大的 社群活動,近 800 人參加!本次活動由 JAX/Flax 和 Google Cloud 團隊共同組織,透過提供免費的 TPUv3,使計算密集型 NLP、計算機視覺和語音專案能夠被更廣泛的工程師和研究人員訪問。參與者建立了超過 170 個模型、22 個數據集和 38 個 Spaces 演示 🤯。您可以在 這裡 探索所有令人驚歎的演示和專案。
活動中圍繞 JAX/Flax、Transformers、大規模語言建模等主題進行了演講!您可以在 這裡 找到所有錄音。
我們非常高興能分享 3 個獲勝團隊的工作!
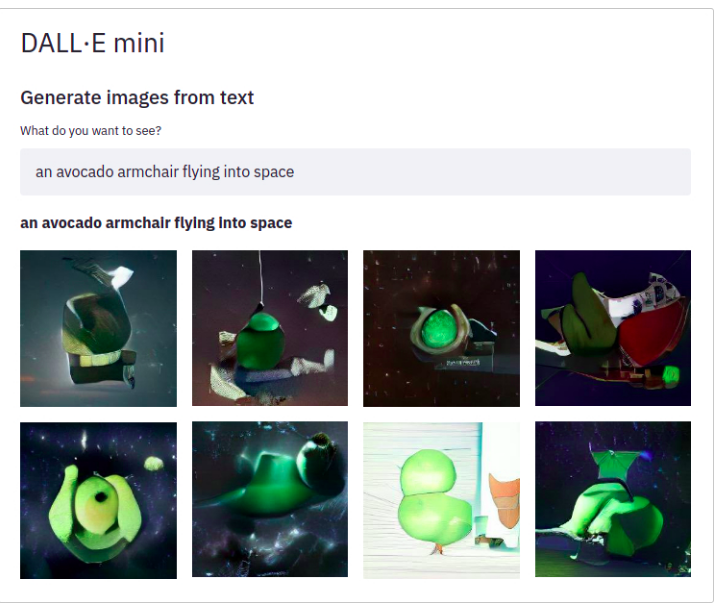
Dall-e mini。DALL·E mini 是一個可以根據您提供的任何提示生成影像的模型!DALL·E mini 比原始 DALL·E 小 27 倍,但仍具有令人印象深刻的結果。
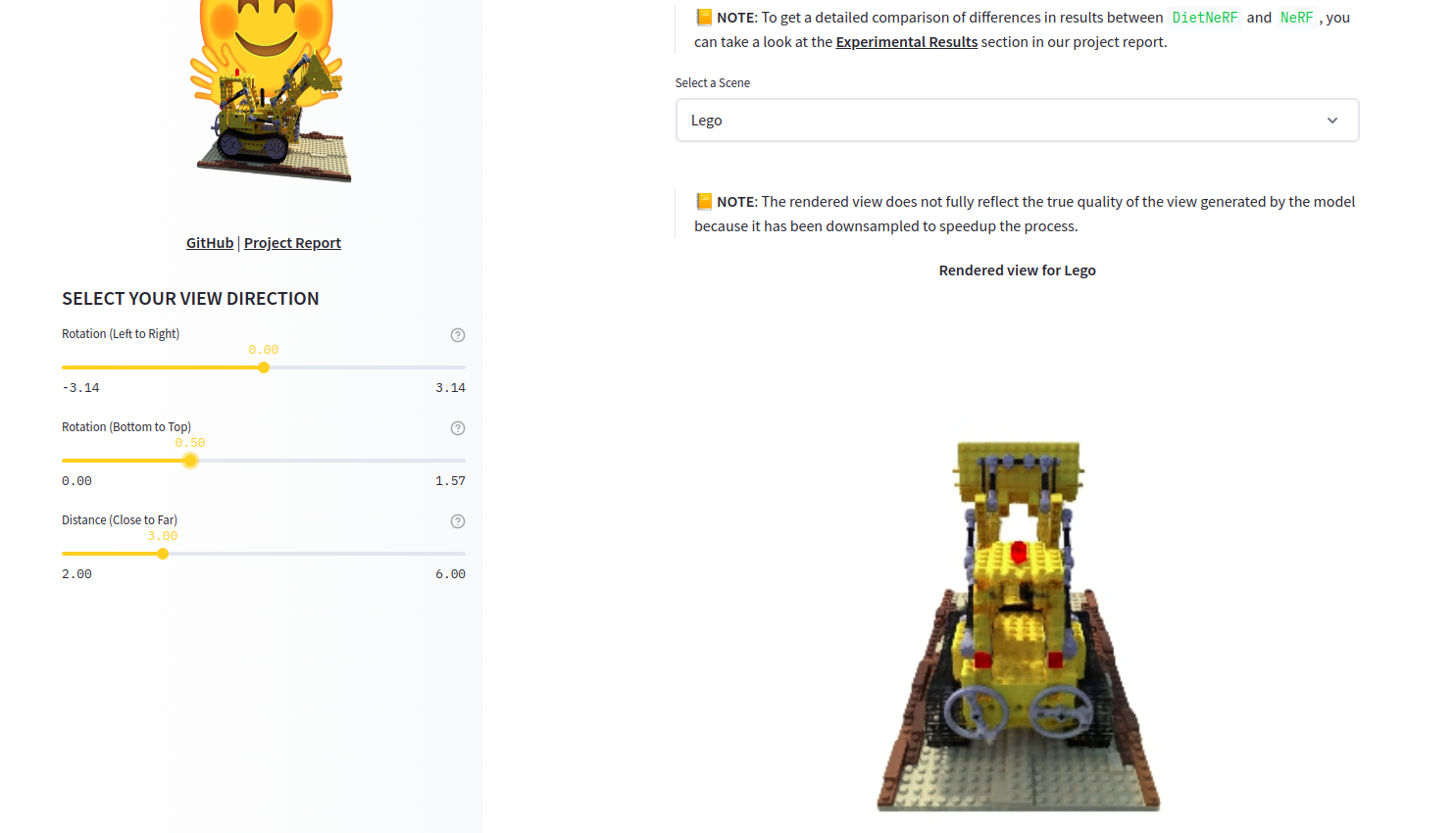
DietNerf。DietNerf 是一種 3D 神經檢視合成模型,旨在透過少量 2D 檢視進行 3D 場景重建的少樣本學習。這是“Putting Nerf on a Diet”論文的第一個開源實現。
CLIP RSIC。CLIP RSIC 是一種在遙感影像資料上微調的 CLIP 模型,可實現零樣本衛星影像分類和字幕生成。該專案展示了微調後的 CLIP 模型在專業領域中的有效性。
除了這些非常酷的專案,我們還很高興看到這些社群活動如何實現對多種語言的大型多模態模型進行訓練。例如,我們看到了有史以來第一個針對斯瓦希里語 (Swahili)、波蘭語 (Polish) 和馬拉地語 (Marathi) 等資源匱乏語言的開源大型語言模型。
附贈
除了我們剛剛分享的所有內容,我們的團隊還在做很多其他事情。以下只是其中的一部分
- 📖 這個 3 部分的 影片系列 展示瞭如何訓練最先進的句子嵌入模型的理論。
- 我們在 PyTorch 社群之聲上進行了演示,並參與了問答環節 (影片)。
- Hugging Face 與 NLP in Spanish 和 SpainAI 合作開設了一個西班牙語 課程,透過用例教授概念、最先進的架構及其應用。
- 我們在 MLOps World Demo Days 上進行了演示。
開源
Transformers 新增內容
夏天對於 🤗 Transformers 來說是一個激動人心的時刻!該庫達到了 50,000 顆星,總下載量達到 3000 萬次,貢獻者接近 1000 人!🤩
那麼,有什麼新內容呢?JAX/Flax 現在是第三個受支援的框架,Hub 中有超過 5000 個模型!您可以找到用於不同任務(例如文字分類)的積極維護的 示例。我們還在努力改進對 TensorFlow 的支援:我們所有的 示例 都經過了重寫,使其更加健壯、更符合 TensorFlow 習慣,並且更清晰。這包括摘要、翻譯和命名實體識別等示例。
您現在可以輕鬆地將模型釋出到 Hub,包括自動生成的模型卡、評估指標和 TensorBoard 例項。透過新的 transformers.onnx 模組,對將模型匯出到 ONNX 的支援也增加了。
python -m transformers.onnx --model=bert-base-cased onnx/bert-base-cased/
最近 4 個版本引入了許多新的酷炫模型!
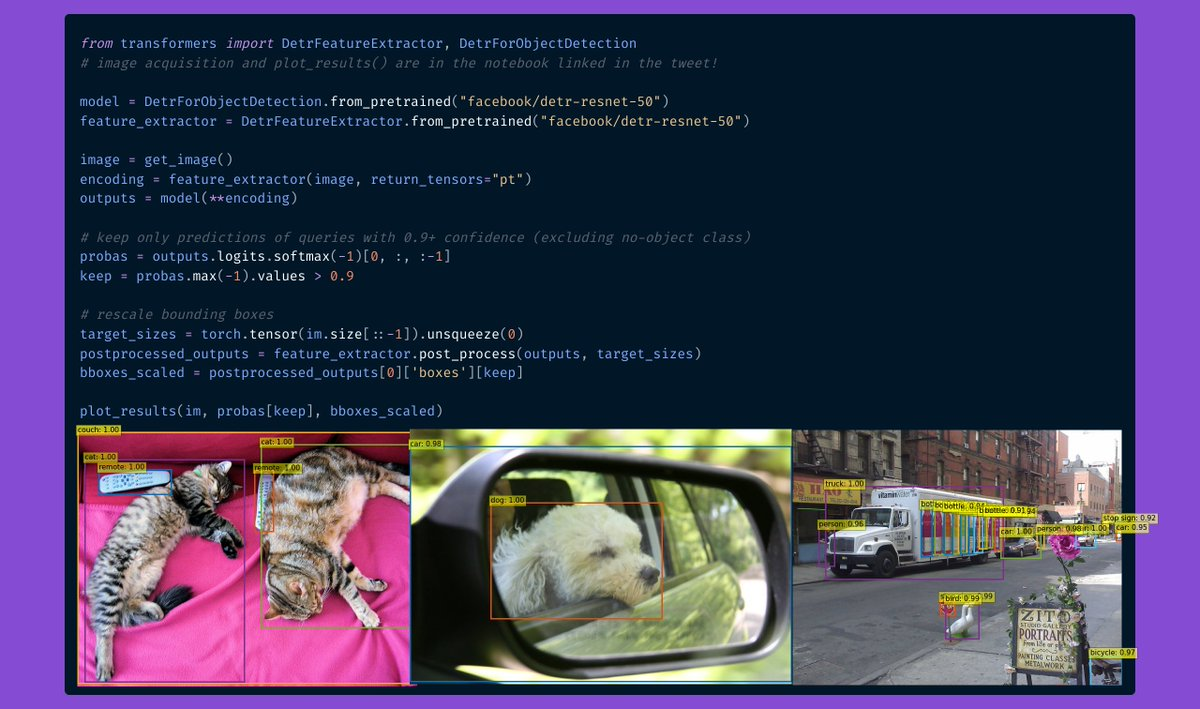
- ByT5 是 Hub 中第一個無需分詞器的模型!您可以在這裡找到所有可用的檢查點。
- CANINE 是 Google AI 釋出的另一個無需分詞器的僅編碼器模型,直接在字元級別操作。您可以在這裡找到所有(多語言)檢查點。
- HuBERT 在下游音訊任務中展現出令人興奮的結果,例如命令分類和情感識別。在此處檢視模型。
- LayoutLMv2 和 LayoutXLM 是兩個令人難以置信的模型,它們能夠透過結合文字、佈局和視覺資訊來解析文件影像(如 PDF)。我們構建了一個 Space 演示,您可以直接嘗試!演示筆記本可以在 這裡 找到。

- 微軟研究院的 BEiT 透過受 BERT 啟發的巧妙預訓練目標,使自監督 Vision Transformer 的效能超越了有監督的 Vision Transformer。
- RemBERT,一個大型多語言 Transformer,在零樣本遷移方面優於 XLM-R(以及引數數量相似的 mT5)。
- Splinter 可用於少樣本問答。僅給定 128 個示例,Splinter 就能在 SQuAD 上達到約 73% 的 F1 分數,比基於 MLM 的模型高出 24 個點!
Hub 現在已整合到 `transformers` 中,能夠直接從 Python 執行時向 Hub 推送配置、模型和分詞器檔案!`Trainer` 現在可以在每次儲存檢查點時直接推送到 Hub。
Datasets 新增內容
多虧了我們社群所有貢獻者的出色工作,您可以在 https://huggingface.co/datasets 中找到 1400 個公共資料集。💯
對 datasets 的支援持續增長:它可以在 JAX 中使用,處理 parquet 檔案,使用遠端檔案,並對其他領域(如自動語音識別和影像分類)有更廣泛的支援。
使用者還可以透過將資料檔案上傳到 Dataset Hub 上的倉庫,直接託管並與社群共享他們的資料集。
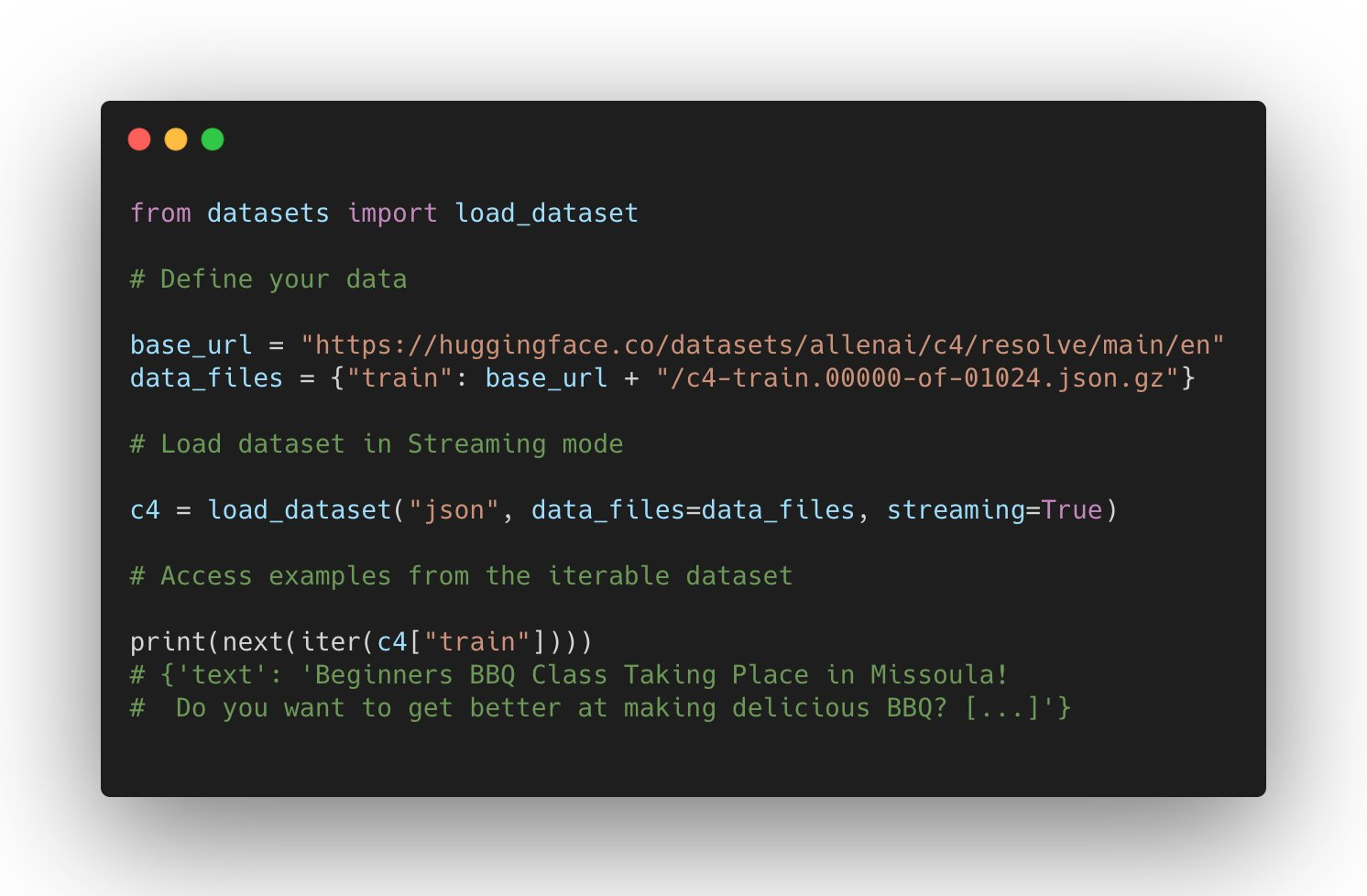
新的資料集亮點是什麼?Microsoft CodeXGlue 資料集 用於多項編碼任務(程式碼補全、生成、搜尋等),以及 C4 和 MC4 等大型資料集,還有更多,例如 RussianSuperGLUE 和 DISFL-QA。
歡迎新庫加入 Hub
除了與基於 transformers 的模型深度整合外,Hub 還與開源機器學習庫建立了良好的合作關係,以提供免費的模型託管和版本控制。我們透過 huggingface_hub 開源庫以及新的 Hub 文件 實現了這一目標。
所有 spaCy 規範管道現在都可以在官方的 spaCy 組織中找到,任何使用者都可以透過一條命令 python -m spacy huggingface-hub 共享他們的管道。要了解更多資訊,請訪問 https://huggingface.co/blog/spacy。您可以在演示 Space 中直接在 Hub 中試用所有規範的 spaCy 模型!
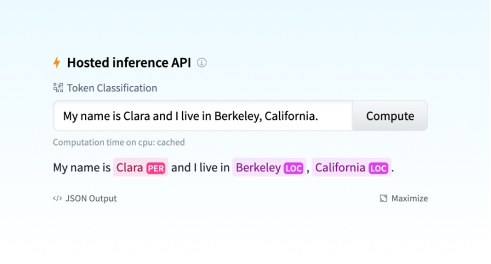
另一個令人興奮的整合是 Sentence Transformers。您可以在 部落格公告 中閱讀更多內容:您可以在 Hub 中找到超過 200 個模型,輕鬆與社群的其他成員共享您的模型並重用社群中的模型。
但這還不是全部!您現在可以在 Hub 中找到超過 100 個 Adapter Transformers,並直接在瀏覽器中使用 Speechbrain 模型和部件進行不同任務,例如音訊分類。如果您對我們與新 ML 庫整合到 Hub 的合作感興趣,您可以在 此處 閱讀更多資訊。

解決方案
即將推出:Infinity
Transformers 延遲降至 1 毫秒?🤯🤯🤯
我們一直在研究一個非常巧妙的解決方案,旨在為最先進的 Transformer 模型實現無與倫比的效率,供公司在其自己的基礎設施中部署。
- Infinity 作為一個單一容器提供,可以在任何生產環境中部署。
- 它可以在 GPU 上實現 BERT 類模型 1 毫秒的延遲,在 CPU 上實現 4-10 毫秒的延遲 🤯🤯🤯
- Infinity 符合最高的安全要求,可以整合到您的系統中,無需網際網路訪問。您可以控制所有傳入和傳出流量。
⚠️ 歡迎在 9 月 28 日的現場釋出和演示 中與我們一同見證 Infinity 首次公開亮相!
新增:硬體加速
Hugging Face 正在與領先的 AI 硬體加速器(如 Intel、Qualcomm 和 GraphCore)合作,旨在使最先進的生產效能觸手可及,並擴充套件 SOTA 硬體上的訓練能力。作為這一旅程的第一步,我們推出了一款新的開源庫:🤗 Optimum——用於生產效能的 ML 最佳化工具包 🏎。在此部落格文章中瞭解更多資訊。
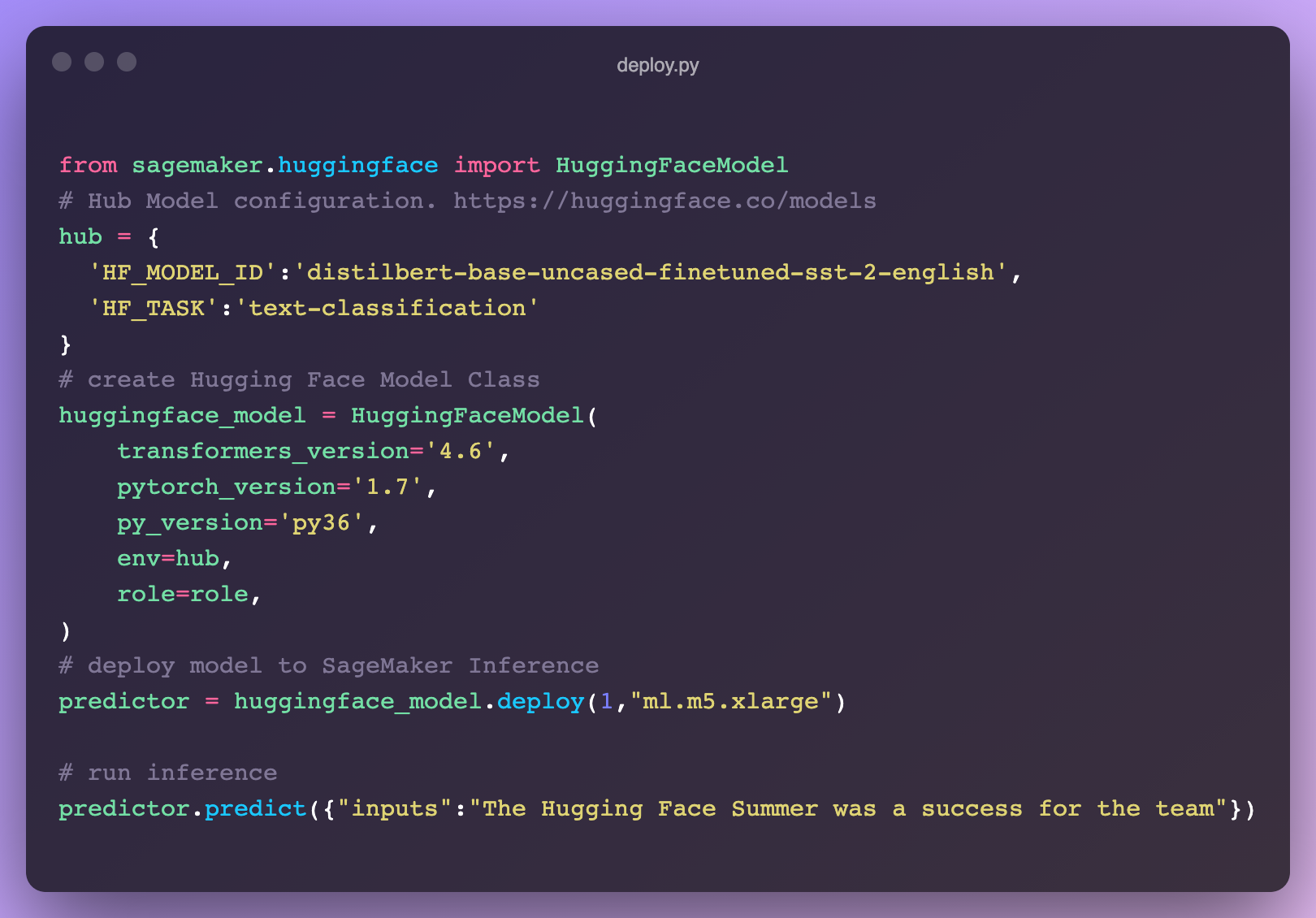
新增:SageMaker 上的推理
我們與 AWS 推出了一項新整合,讓在 SageMaker 中部署 🤗 Transformers 比以往任何時候都容易 🔥。直接從 🤗 Hub 模型頁面獲取程式碼片段!在我們的文件中瞭解如何在 SageMaker 中利用 Transformers,或者檢視這些影片教程。
如有疑問,請在論壇上聯絡我們:https://discuss.huggingface.co/c/sagemaker/17
新增:瀏覽器中的 AutoNLP
我們釋出了全新的 AutoNLP 體驗:一個可以直接從瀏覽器訓練模型的網頁介面!現在,只需點選幾下即可在您自己的資料上訓練、評估和部署 🤗 Transformers 模型。無需程式碼,立即嘗試!

推理 API
網路研討會:
我們舉辦了一場線上研討會,展示瞭如何用幾行程式碼新增機器學習功能。我們還構建了一個 VSCode 擴充套件,它利用 Hugging Face 推理 API 生成描述 Python 程式碼的註釋。
Hugging Face + Zapier 演示
20,000 多個機器學習模型連線到 3,000 多個應用程式?🤯 透過利用 推理 API,您現在可以輕鬆地將模型直接連線到 Gmail、Slack、Twitter 等應用程式。在這個演示影片中,我們建立了一個使用此 程式碼片段 來分析您的 Twitter 提及並在 Slack 上提醒您負面提及的 zap。
Hugging Face + Google 表格演示
藉助 推理 API,您可以輕鬆地將零樣本分類直接應用到 Google 表格中的電子表格中。只需在 工具 -> 指令碼編輯器中新增此指令碼
少樣本學習實踐
我們寫了一篇部落格文章,介紹了什麼是少樣本學習,並探討了如何使用 GPT-Neo 和 🤗 加速推理 API 來生成自己的預測。
專家加速計劃
檢視 專家加速計劃的全新主頁;您現在可以從我們的機器學習專家那裡獲得直接、優質的支援,更快地構建更好的機器學習解決方案。
研究
在 BigScience,我們於 7 月舉辦了第一次現場活動(自啟動以來)BigScience Episode #1。我們的第二次活動 BigScience Episode #2 於 2021 年 9 月 20 日舉行,包括 BigScience 工作組的技術講座和更新,以及 Jade Abbott (Masakhane)、Percy Liang (Stanford CRFM)、Stella Biderman (EleutherAI) 等受邀講座。我們已經完成了 Jean Zay 上的第一次大規模訓練,一個 13B 僅限英語的解碼器模型(您可以在這裡找到詳細資訊),我們目前正在決定第二個模型的架構。組織工作組已經提交了第二筆計算預算的申請:Jean Zay V100:2,500,000 GPU 小時。🚀
6 月,我們分享了與 Yandex 研究團隊合作的成果:DeDLOC,這是一種協作訓練大型神經網路的方法,即無需使用 HPC 叢集,而是利用各種可訪問的資源,如 Google Colaboratory 或 Kaggle 筆記本、個人電腦或搶佔式虛擬機器。透過這種方法,我們成功地與 40 名志願者一起訓練了孟加拉語模型 sahajBERT!我們的模型與最先進的模型競爭,甚至在 Soham 新聞文章分類資料集上下游分類任務中表現最佳。您可以在這篇部落格文章中閱讀更多內容。這是一條引人入勝的研究方向,因為它將使模型預訓練在財務上更具可及性!
6 月,我們的論文《How Many Data Points is a Prompt Worth?》在 NAACL 獲得了最佳論文獎!在論文中,我們協調並比較了傳統的和基於提示的方法來適應預訓練模型,發現人工編寫的提示在新的任務上相當於數千個有監督的資料點。您也可以閱讀其部落格文章。
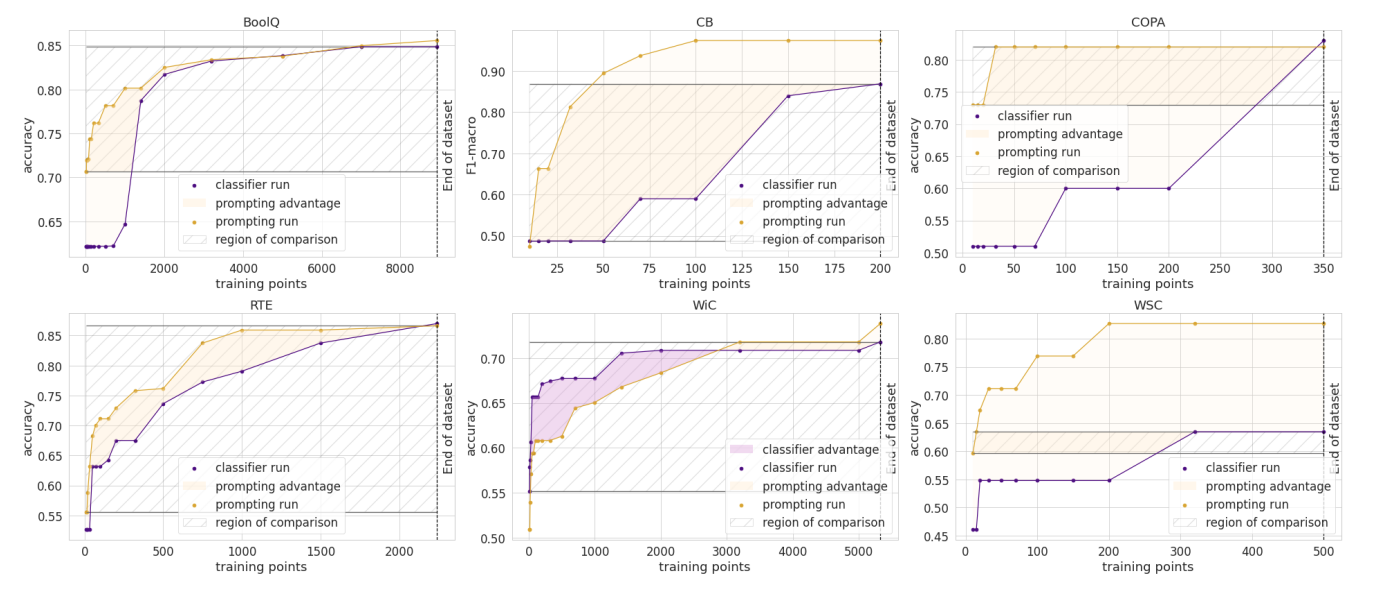
我們期待今年的 EMNLP,屆時我們有四篇論文被錄用!
- 我們的論文“Datasets: A Community Library for Natural Language Processing”記錄了 Hugging Face Datasets 專案,該專案擁有 300 多名貢獻者。這個社群專案為研究人員提供了數百個資料集的便捷訪問。它促進了跨資料集 NLP 的新用例,並具有索引和流式傳輸大型資料集等高階功能。
- 我們與達姆施塔特工業大學研究人員的合作促成了另一篇會議論文的發表 (“避免少樣本提示微調中的推理啟發式”)。在這篇論文中,我們展示了基於提示微調的語言模型(在少樣本設定中表現出色)仍然存在學習表面啟發式(有時稱為資料集偏差)的問題,而零樣本模型則沒有。
- 我們提交的論文《用於更快 Transformer 的塊剪枝》也被接收為長論文。在這篇論文中,我們展示瞭如何使用塊稀疏性來獲得又快又小的 Transformer 模型。我們的實驗結果表明,在 SQuAD 上,模型比 BERT 快 2.4 倍,小 74%。
結語
😎 🔥 夏天真有趣!發生了好多事情!我們希望您喜歡閱讀這篇部落格文章,並期待分享我們正在開發的新專案。冬天再見!❄️

