Diffusers 文件
OmniGen
並獲得增強的文件體驗
開始使用
OmniGen
OmniGen 是一個影像生成模型。與現有文字到影像模型不同,OmniGen 是一個單一模型,旨在處理各種任務(例如,文字到影像、影像編輯、可控生成)。它具有以下特點:
- 極簡模型架構,僅包含 VAE 和 Transformer 模組,用於文字和影像的聯合建模。
- 支援多模態輸入。它可以處理任何文字-影像混合資料作為影像生成的指令,而不是僅僅依賴於文字。
欲瞭解更多資訊,請參閱論文。本指南將引導您使用 OmniGen 完成各種任務和用例。
載入模型檢查點
模型權重可以儲存在 Hub 上或本地的單獨子資料夾中,在這種情況下,您應該使用 from_pretrained() 方法。
import torch
from diffusers import OmniGenPipeline
pipe = OmniGenPipeline.from_pretrained("Shitao/OmniGen-v1-diffusers", torch_dtype=torch.bfloat16)文字到影像
對於文字到影像,傳遞一個文字提示。預設情況下,OmniGen 生成 1024x1024 影像。您可以嘗試設定 height 和 width 引數來生成不同尺寸的影像。
import torch
from diffusers import OmniGenPipeline
pipe = OmniGenPipeline.from_pretrained(
"Shitao/OmniGen-v1-diffusers",
torch_dtype=torch.bfloat16
)
pipe.to("cuda")
prompt = "Realistic photo. A young woman sits on a sofa, holding a book and facing the camera. She wears delicate silver hoop earrings adorned with tiny, sparkling diamonds that catch the light, with her long chestnut hair cascading over her shoulders. Her eyes are focused and gentle, framed by long, dark lashes. She is dressed in a cozy cream sweater, which complements her warm, inviting smile. Behind her, there is a table with a cup of water in a sleek, minimalist blue mug. The background is a serene indoor setting with soft natural light filtering through a window, adorned with tasteful art and flowers, creating a cozy and peaceful ambiance. 4K, HD."
image = pipe(
prompt=prompt,
height=1024,
width=1024,
guidance_scale=3,
generator=torch.Generator(device="cpu").manual_seed(111),
).images[0]
image.save("output.png")
影像編輯
OmniGen 支援多模態輸入。當輸入包含影像時,您需要在文字提示中新增佔位符 <img><|image_1|></img> 來表示影像。建議啟用 use_input_image_size_as_output 以使編輯後的影像與原始影像大小相同。
import torch
from diffusers import OmniGenPipeline
from diffusers.utils import load_image
pipe = OmniGenPipeline.from_pretrained(
"Shitao/OmniGen-v1-diffusers",
torch_dtype=torch.bfloat16
)
pipe.to("cuda")
prompt="<img><|image_1|></img> Remove the woman's earrings. Replace the mug with a clear glass filled with sparkling iced cola."
input_images=[load_image("https://raw.githubusercontent.com/VectorSpaceLab/OmniGen/main/imgs/docs_img/t2i_woman_with_book.png")]
image = pipe(
prompt=prompt,
input_images=input_images,
guidance_scale=2,
img_guidance_scale=1.6,
use_input_image_size_as_output=True,
generator=torch.Generator(device="cpu").manual_seed(222)
).images[0]
image.save("output.png") 
OmniGen 具有一些有趣的特性,例如視覺推理,如下例所示。
prompt="If the woman is thirsty, what should she take? Find it in the image and highlight it in blue. <img><|image_1|></img>"
input_images=[load_image("https://raw.githubusercontent.com/VectorSpaceLab/OmniGen/main/imgs/docs_img/edit.png")]
image = pipe(
prompt=prompt,
input_images=input_images,
guidance_scale=2,
img_guidance_scale=1.6,
use_input_image_size_as_output=True,
generator=torch.Generator(device="cpu").manual_seed(0)
).images[0]
image.save("output.png")
可控生成
OmniGen 可以處理多項經典計算機視覺任務。如下圖所示,OmniGen 可以檢測輸入影像中的人體骨架,這些骨架可以作為控制條件來生成新的影像。
import torch
from diffusers import OmniGenPipeline
from diffusers.utils import load_image
pipe = OmniGenPipeline.from_pretrained(
"Shitao/OmniGen-v1-diffusers",
torch_dtype=torch.bfloat16
)
pipe.to("cuda")
prompt="Detect the skeleton of human in this image: <img><|image_1|></img>"
input_images=[load_image("https://raw.githubusercontent.com/VectorSpaceLab/OmniGen/main/imgs/docs_img/edit.png")]
image1 = pipe(
prompt=prompt,
input_images=input_images,
guidance_scale=2,
img_guidance_scale=1.6,
use_input_image_size_as_output=True,
generator=torch.Generator(device="cpu").manual_seed(333)
).images[0]
image1.save("image1.png")
prompt="Generate a new photo using the following picture and text as conditions: <img><|image_1|></img>\n A young boy is sitting on a sofa in the library, holding a book. His hair is neatly combed, and a faint smile plays on his lips, with a few freckles scattered across his cheeks. The library is quiet, with rows of shelves filled with books stretching out behind him."
input_images=[load_image("https://raw.githubusercontent.com/VectorSpaceLab/OmniGen/main/imgs/docs_img/skeletal.png")]
image2 = pipe(
prompt=prompt,
input_images=input_images,
guidance_scale=2,
img_guidance_scale=1.6,
use_input_image_size_as_output=True,
generator=torch.Generator(device="cpu").manual_seed(333)
).images[0]
image2.save("image2.png") 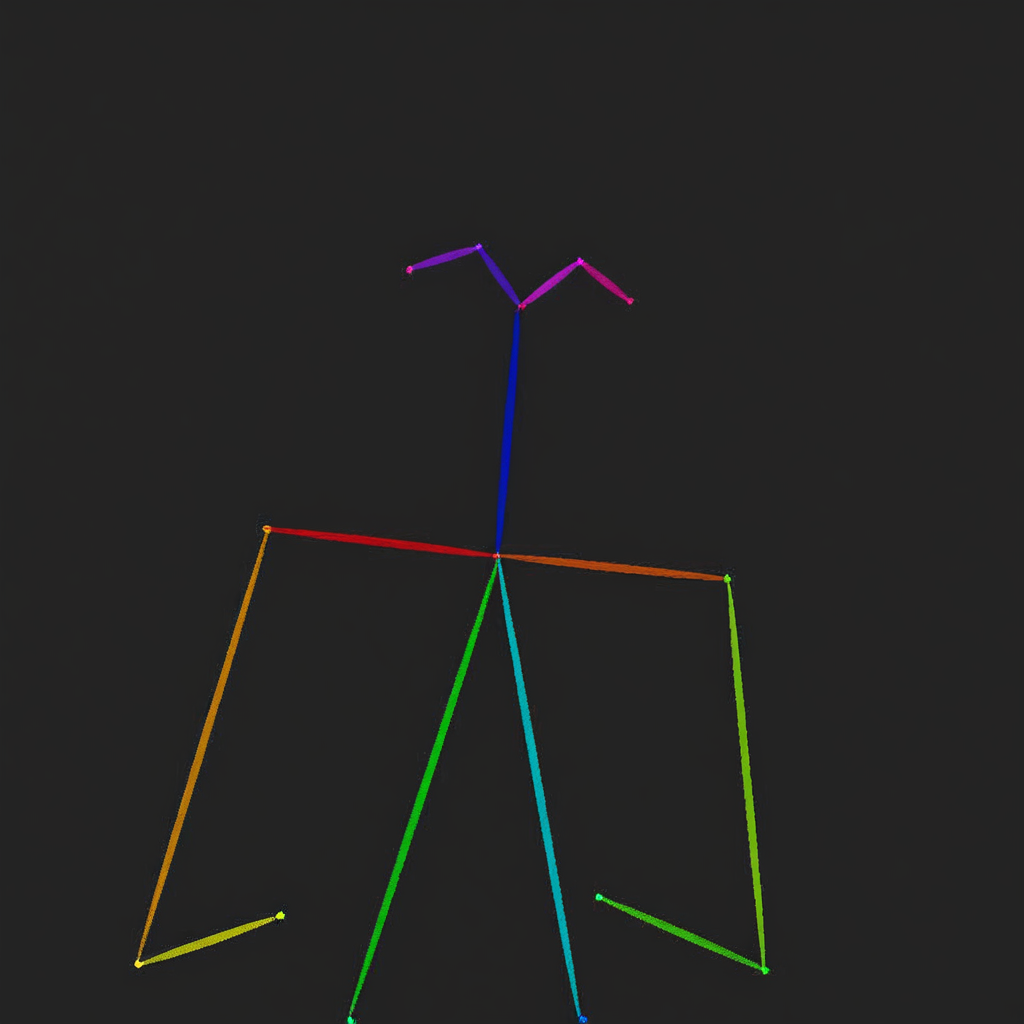

OmniGen 還可以直接使用輸入影像中的相關資訊來生成新的影像。
import torch
from diffusers import OmniGenPipeline
from diffusers.utils import load_image
pipe = OmniGenPipeline.from_pretrained(
"Shitao/OmniGen-v1-diffusers",
torch_dtype=torch.bfloat16
)
pipe.to("cuda")
prompt="Following the pose of this image <img><|image_1|></img>, generate a new photo: A young boy is sitting on a sofa in the library, holding a book. His hair is neatly combed, and a faint smile plays on his lips, with a few freckles scattered across his cheeks. The library is quiet, with rows of shelves filled with books stretching out behind him."
input_images=[load_image("https://raw.githubusercontent.com/VectorSpaceLab/OmniGen/main/imgs/docs_img/edit.png")]
image = pipe(
prompt=prompt,
input_images=input_images,
guidance_scale=2,
img_guidance_scale=1.6,
use_input_image_size_as_output=True,
generator=torch.Generator(device="cpu").manual_seed(0)
).images[0]
image.save("output.png")
ID 和物件保留
OmniGen 可以根據輸入影像中的人物和物件生成多張影像,並支援同時輸入多張影像。此外,OmniGen 可以根據指令從包含多個物件的影像中提取所需物件。
import torch
from diffusers import OmniGenPipeline
from diffusers.utils import load_image
pipe = OmniGenPipeline.from_pretrained(
"Shitao/OmniGen-v1-diffusers",
torch_dtype=torch.bfloat16
)
pipe.to("cuda")
prompt="A man and a woman are sitting at a classroom desk. The man is the man with yellow hair in <img><|image_1|></img>. The woman is the woman on the left of <img><|image_2|></img>"
input_image_1 = load_image("https://raw.githubusercontent.com/VectorSpaceLab/OmniGen/main/imgs/docs_img/3.png")
input_image_2 = load_image("https://raw.githubusercontent.com/VectorSpaceLab/OmniGen/main/imgs/docs_img/4.png")
input_images=[input_image_1, input_image_2]
image = pipe(
prompt=prompt,
input_images=input_images,
height=1024,
width=1024,
guidance_scale=2.5,
img_guidance_scale=1.6,
generator=torch.Generator(device="cpu").manual_seed(666)
).images[0]
image.save("output.png")


import torch
from diffusers import OmniGenPipeline
from diffusers.utils import load_image
pipe = OmniGenPipeline.from_pretrained(
"Shitao/OmniGen-v1-diffusers",
torch_dtype=torch.bfloat16
)
pipe.to("cuda")
prompt="A woman is walking down the street, wearing a white long-sleeve blouse with lace details on the sleeves, paired with a blue pleated skirt. The woman is <img><|image_1|></img>. The long-sleeve blouse and a pleated skirt are <img><|image_2|></img>."
input_image_1 = load_image("https://raw.githubusercontent.com/VectorSpaceLab/OmniGen/main/imgs/docs_img/emma.jpeg")
input_image_2 = load_image("https://raw.githubusercontent.com/VectorSpaceLab/OmniGen/main/imgs/docs_img/dress.jpg")
input_images=[input_image_1, input_image_2]
image = pipe(
prompt=prompt,
input_images=input_images,
height=1024,
width=1024,
guidance_scale=2.5,
img_guidance_scale=1.6,
generator=torch.Generator(device="cpu").manual_seed(666)
).images[0]
image.save("output.png")


使用多張影像時的最佳化
對於文字到影像任務,OmniGen 需要極少的記憶體和時間成本(在 A800 GPU 上生成 1024x1024 影像需要 9GB 記憶體和 31 秒)。但是,當使用輸入影像時,計算成本會增加。
以下是一些在使用多張影像時幫助您降低計算成本的指南。實驗在 A800 GPU 上進行,使用兩張輸入影像。
與其他管道一樣,您可以透過解除安裝模型來減少記憶體使用:pipe.enable_model_cpu_offload() 或 pipe.enable_sequential_cpu_offload() 。在 OmniGen 中,您還可以透過減少 max_input_image_size 來降低計算開銷。不同影像尺寸的記憶體消耗如下表所示:
| 方法 | 記憶體使用 |
|---|---|
| max_input_image_size=1024 | 40GB |
| max_input_image_size=512 | 17GB |
| max_input_image_size=256 | 14GB |