擴散模型課程文件
第 4 單元:深入瞭解擴散模型
並獲得增強的文件體驗
開始使用
第 4 單元:深入瞭解擴散模型
歡迎來到 Hugging Face 擴散模型課程的第 4 單元!在本單元中,我們將探討最新研究中出現的對擴散模型的諸多改進和擴充套件。與之前的單元相比,本單元的程式碼量會少一些,旨在為您提供進一步研究的起點。
開始本單元 :rocket:
以下是本單元的步驟:
- 請確保您已經註冊本課程,以便在課程增加新單元時收到通知。
- 請通讀以下材料,瞭解本單元涵蓋的不同主題的概覽。
- 透過連結的影片和資源,深入研究任何特定的主題。
- 探索演示筆記本,然後閱讀“下一步”部分,瞭解一些專案建議。
:loudspeaker: 別忘了加入 Discord,您可以在 #diffusion-models-class 頻道中討論課程材料並分享您的創作。
目錄
透過蒸餾加速取樣
漸進式蒸餾是一種技術,它利用現有的擴散模型來訓練一個新版本的模型,這個新模型在推理時需要更少的步驟。“學生”模型的權重從“教師”模型的權重初始化。在訓練過程中,教師模型執行兩個取樣步驟,學生模型則嘗試在一個步驟內匹配最終的預測結果。這個過程可以重複多次,前一次迭代的學生模型成為下一階段的教師模型。最終得到的模型可以在比原始教師模型少得多的步驟(通常是 4 或 8 步)內生成質量不錯的樣本。其核心機制在提出該想法的論文中的這張圖中有所說明。
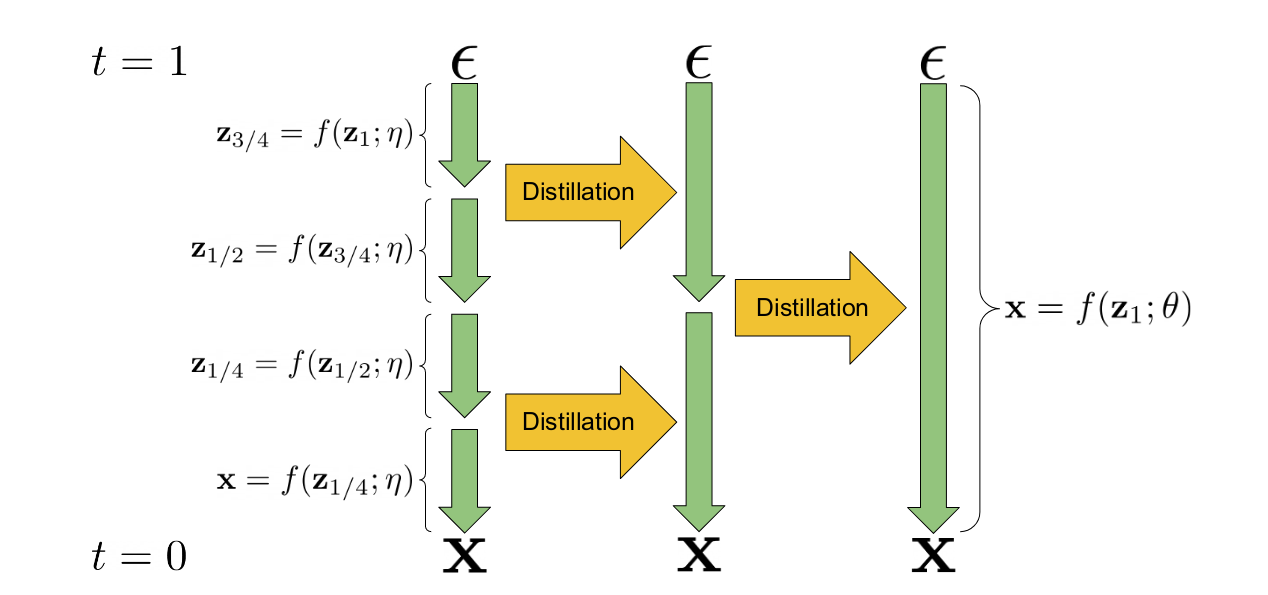
漸進式蒸餾圖解(來自論文)
利用現有模型來“教導”新模型的想法可以擴充套件到建立引導模型,其中教師模型使用無分類器引導技術,而學生模型必須學會在一個步驟內,根據指定目標引導尺度的額外輸入,產生等效的輸出。這進一步減少了生成高質量樣本所需的模型評估次數。這段影片概述了這種方法。
注意:Stable Diffusion 的蒸餾版本可以在這裡使用。
關鍵參考文獻
- 用於快速取樣擴散模型的漸進式蒸餾(Progressive Distillation For Fast Sampling Of Diffusion Models)
- 關於引導擴散模型的蒸餾(On Distillation Of Guided Diffusion Models)
訓練改進
為了改進擴散模型的訓練,已經開發了一些額外的技巧。在本節中,我們試圖捕捉近期論文中的核心思想。不斷有研究湧現出更多的改進,所以如果您看到一篇您認為應該加在這裡的論文,請告訴我們!
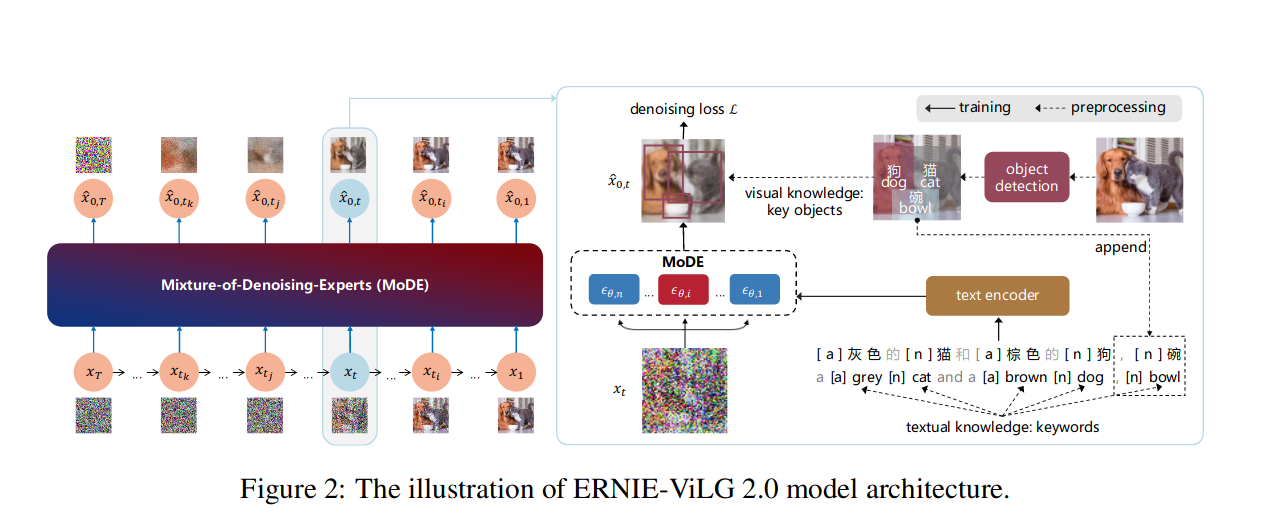 圖 2 來自 ERNIE-ViLG 2.0 論文
圖 2 來自 ERNIE-ViLG 2.0 論文
關鍵訓練改進
- 調整噪聲排程、損失權重和取樣軌跡以實現更高效的訓練。Karras 等人撰寫的《闡明基於擴散的生成模型的設計空間》(Elucidating the Design Space of Diffusion-Based Generative Models)是一篇探討這些設計選擇的優秀論文。
- 在多種寬高比上進行訓練,如課程釋出會上的這段影片所述。
- 級聯擴散模型,即先訓練一個低解析度模型,然後再訓練一個或多個超解析度模型。這種方法被用於 DALLE-2、Imagen 等模型中以生成高解析度影像。
- 更好的條件設定,整合豐富的文字嵌入(Imagen 使用了一個名為 T5 的大型語言模型)或多種型別的條件(eDiffi)。
- “知識增強”——在訓練過程中整合預訓練的影像字幕和物體檢測模型,以建立資訊更豐富的字幕併產生更好的效能(ERNIE-ViLG 2.0)。
- “去噪專家混合”(MoDE)——為不同的噪聲水平訓練模型的不同變體(“專家”),如上圖 ERNIE-ViLG 2.0 論文中的插圖所示。
關鍵參考文獻
- 闡明基於擴散的生成模型的設計空間(Elucidating the Design Space of Diffusion-Based Generative Models)
- eDiffi: 具有專家去噪器整合的文字到影像擴散模型(eDiffi: Text-to-Image Diffusion Models with an Ensemble of Expert Denoisers)
- ERNIE-ViLG 2.0: 利用知識增強的去噪專家混合改進文字到影像擴散模型(ERNIE-ViLG 2.0: Improving Text-to-Image Diffusion Model with Knowledge-Enhanced Mixture-of-Denoising-Experts)
- Imagen - 具有深度語言理解的逼真文字到影像擴散模型(演示網站)
對生成和編輯的更多控制
除了訓練方面的改進,取樣和推理階段也出現了幾項創新,其中許多方法可以為現有的擴散模型增加新功能。
 由“詞語作畫”(paint-with-words)生成的樣本(eDiffi)
由“詞語作畫”(paint-with-words)生成的樣本(eDiffi)
影片“使用擴散模型編輯影像”概述了使用擴散模型編輯現有影像的不同方法。可用的技術可以分為四個主要類別:
1) 新增噪聲,然後用新的提示進行去噪。這是 img2img 工作流背後的思想,該思想在各種論文中得到了修改和擴充套件。
- SDEdit 和 MagicMix 建立在這一思想之上。
- DDIM 反演(TODO 連結教程)使用模型來“反轉”取樣軌跡,而不是新增隨機噪聲,從而實現更好的控制。
- 空文字反演透過在每一步最佳化用於無分類器引導的無條件文字嵌入,極大地提升了這類方法的效能,實現了極高質量的基於文字的影像編輯。 2) 擴充套件(1)中的思想,但使用蒙版來控制效果的應用位置。
- 混合擴散(Blended Diffusion)介紹了這個基本思想。
- 這個演示使用現有的分割模型(CLIPSeg)根據文字描述建立蒙版。
- DiffEdit 是一篇優秀的論文,展示瞭如何使用擴散模型本身來生成適當的蒙版,以根據文字編輯影像。
- SmartBrush:文字和形狀引導的物體修復與擴散模型(SmartBrush: Text and Shape Guided Object Inpainting with Diffusion Model)對擴散模型進行了微調,以實現更準確的蒙版引導修復。 3) 交叉注意力控制:利用擴散模型中的交叉注意力機制來控制編輯的空間位置,以實現更精細的控制。
- 使用交叉注意力控制進行提示到提示的影像編輯(Prompt-to-Prompt Image Editing with Cross Attention Control)是介紹這一思想的關鍵論文,該技術後來被應用於 Stable Diffusion。
- 這個思想也用於“詞語作畫”(eDiffi,如上圖所示)。 4) 在單個影像上進行微調(“過擬合”),然後使用微調後的模型進行生成。以下論文幾乎同時發表了該思想的變體:
- Imagic:基於文字的真實影像編輯與擴散模型.
- UniTune:透過在單個影像上微調影像生成模型實現文字驅動的影像編輯.
論文InstructPix2Pix: 學習遵循影像編輯指令值得注意,因為它使用了一些上述影像編輯技術來構建一個包含影像對和影像編輯指令(由 GPT3.5 生成)的合成數據集,以訓練一個能夠根據自然語言指令編輯影像的新模型。
影片
 來自 Imagen Video 生成的示例影片的靜止幀
來自 Imagen Video 生成的示例影片的靜止幀
影片可以表示為影像序列,擴散模型的核心思想可以應用於這些序列。最近的研究集中在尋找合適的架構(例如作用於整個序列的“3D UNet”)以及高效處理影片資料。由於高幀率影片比靜態影像涉及更多的資料,目前的方法傾向於首先生成低解析度和低幀率的影片,然後應用空間和時間上的超解析度來產生最終的高質量影片輸出。
關鍵參考文獻
- 影片擴散模型(Video Diffusion Models)
- IMAGEN VIDEO: 使用擴散模型進行高畫質影片生成(IMAGEN VIDEO: HIGH DEFINITION VIDEO GENERATION WITH DIFFUSION MODELS)
音訊
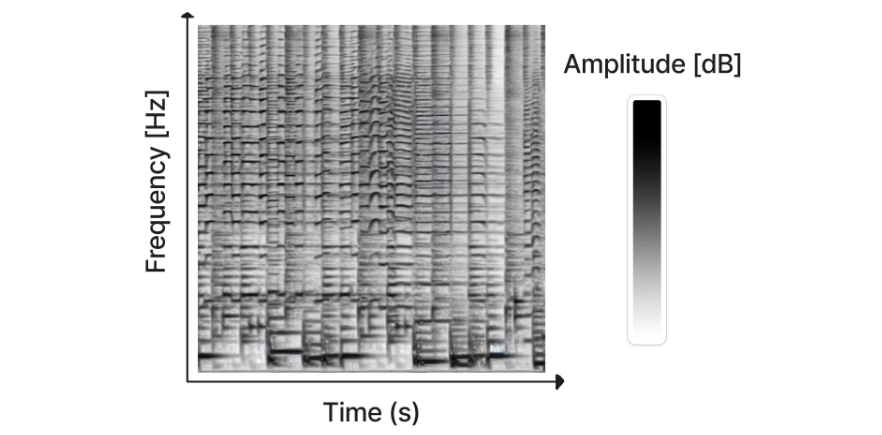
Riffusion 生成的頻譜圖(圖片來源)
雖然已經有一些工作直接使用擴散模型生成音訊(例如 DiffWave),但迄今為止最成功的方法是將音訊訊號轉換成一種叫做頻譜圖的東西,它有效地將音訊“編碼”成一個二維“影像”,然後可以用來訓練我們習慣於用於影像生成的那種擴散模型。生成的頻譜圖隨後可以使用現有方法轉換回音訊。最近釋出的 Riffusion 就是基於這種方法,它對 Stable Diffusion 進行了微調,以根據文字生成頻譜圖 - 點選這裡試用。
音訊生成領域發展極其迅速。在過去的一週裡(在撰寫本文時),至少有 5 項新進展被宣佈,這些進展在下面的列表中用星號標記。
關鍵參考文獻
- DiffWave: 一個用於音訊合成的多功能擴散模型
- “Riffusion”(以及程式碼)
- *谷歌的 MusicLM 可以根據文字生成連貫的音訊,並且可以用哼唱或吹口哨的旋律作為條件。
- *RAVE2 - 一種新版本的變分自編碼器,可用於音訊任務的潛在擴散。這在即將釋出的 *AudioLDM 模型中被使用。
- *Noise2Music - 一個經過訓練的擴散模型,可根據文字描述生成高質量的 30 秒音訊片段。
- *Make-An-Audio: 基於提示增強擴散模型的文字到音訊生成 - 一個經過訓練的擴散模型,可根據文字生成多樣的聲音。
- *Moûsai: 基於長上下文潛在擴散的文字到音樂生成
新的架構和方法 - 邁向“迭代最佳化”

冷擴散(Cold Diffusion)論文中的圖 1
我們正在逐漸超越“擴散”模型最初的狹隘定義,邁向一類更通用的模型,這些模型執行迭代最佳化,即透過逐步逆轉某種形式的損壞(如前向擴散過程中的高斯噪聲新增)來生成樣本。“冷擴散”論文證明,許多其他型別的損壞也可以被迭代地“撤銷”以生成影像(如上圖所示),而最近基於 Transformer 的方法已經證明了令牌替換或掩碼作為加噪策略的有效性。
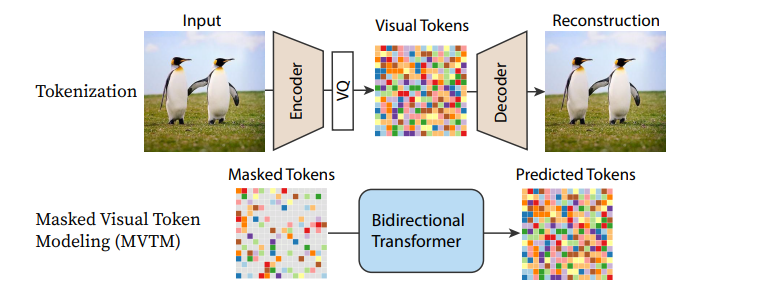
MaskGIT 的流程圖
作為許多現有擴散模型核心的 UNet 架構也正在被不同的替代方案所取代,其中最引人注目的是各種基於 Transformer 的架構。在使用 Transformer 的可擴充套件擴散模型(DiT)中,一個 Transformer 被用來替代 UNet,用於一個相當標準的擴散模型方法,並取得了優異的結果。迴圈介面網路(Recurrent Interface Networks)應用了一種新穎的基於 Transformer 的架構和訓練策略,以追求更高的效率。MaskGIT 和 MUSE 使用 Transformer 模型來處理影像的標記化表示,儘管 Paella 模型證明 UNet 也可以成功地應用於這些基於標記的正規化中。
隨著每一篇新論文的發表,更高效的方法正在被開發出來,可能還需要一段時間我們才能看到這類迭代最佳化任務的效能巔峰。還有很多東西有待探索!
關鍵參考文獻
- 冷擴散:無噪聲地反轉任意影像變換
- 使用 Transformer 的可擴充套件擴散模型 (DiT)
- MaskGIT: 掩碼生成式影像 Transformer
- Muse: 透過掩碼生成式 Transformer 實現文字到影像生成
- 在向量量化潛在空間上的快速文字條件離散去噪 (Paella)
- 迴圈介面網路 - 一種有前途的新架構,在不依賴潛在擴散或超解析度的情況下,能很好地生成高解析度影像。另見 簡單擴散:端到端的用於高解析度影像的擴散模型,該文強調了噪聲排程對於在更高解析度下訓練的重要性。
動手實踐筆記本
| 章節 | Colab | Kaggle | Gradient | Studio Lab |
|---|---|---|---|---|
| DDIM 反演 |  |  | ||
| 音訊擴散 | | |
在本單元中,我們已經涵蓋了非常多的不同思想,其中許多都值得在未來開設更詳細的後續課程。目前,您可以透過我們準備的動手實踐筆記本選擇兩個主題進行學習。
- DDIM 反演展示瞭如何使用一種稱為反演的技術來編輯使用現有擴散模型的影像。
- 音訊擴散介紹了頻譜圖的概念,並展示了一個在特定音樂流派上微調音訊擴散模型的最小示例。
下一步?
這是本課程目前的最後一個單元,這意味著接下來要學什麼取決於您!請記住,您可以隨時在 Hugging Face 的 Discord 上提問和討論您的專案。我們期待看到您的創作 🤗。
< > 在 GitHub 上更新