AutoTrain 文件
影像分類與迴歸
並獲得增強的文件體驗
開始使用
影像分類與迴歸
影像分類是一種監督學習形式,模型被訓練來識別和分類影像中的物件。AutoTrain 簡化了這一過程,使您只需上傳帶標籤的示例影像即可訓練出最先進的影像分類模型。
影像迴歸/評分是一種監督學習形式,模型被訓練來預測影像的分數或值。AutoTrain 簡化了這一過程,使您只需上傳帶標籤的示例影像即可訓練出最先進的影像評分模型。
準備您的資料
為確保您的影像分類模型能夠有效訓練,請遵循以下指南準備您的資料
為影像分類整理圖片
準備一個包含您已分類影像的 zip 檔案。每個類別都應有其自己的子資料夾,並以其代表的類別命名。例如,要區分“貓”和“狗”,您的 zip 檔案結構應如下所示
cats_and_dogs.zip
├── cats
│ ├── cat.1.jpg
│ ├── cat.2.jpg
│ ├── cat.3.jpg
│ └── ...
└── dogs
├── dog.1.jpg
├── dog.2.jpg
├── dog.3.jpg
└── ...您也可以使用 Hugging Face Hub 上的資料集。Hugging Face Hub 上的示例資料集:truepositive/hotdog_nothotdog。
為影像迴歸/評分整理圖片
準備一個包含您的圖片和 metadata.jsonl 的 zip 檔案。
Archive.zip
├── 0001.png
├── 0002.png
├── 0003.png
├── .
├── .
├── .
└── metadata.jsonlmetadata.jsonl 示例
{"file_name": "0001.png", "target": 0.5}
{"file_name": "0002.png", "target": 0.7}
{"file_name": "0003.png", "target": 0.3}請注意,metadata.jsonl 應包含每張圖片的 `file_name` 和 `target` 值。
您也可以使用 Hugging Face Hub 上的資料集。Hugging Face Hub 上的示例資料集:abhishek/img-quality-full。
圖片要求
格式:確保所有圖片均為 JPEG、JPG 或 PNG 格式。
數量:每個類別至少包含 5 張圖片,以便為模型提供足夠的學習示例。
專一性:zip 檔案應只包含以類別命名的資料夾,且這些資料夾中只應包含相關圖片。不應包含任何其他檔案或巢狀資料夾。
額外提示
統一性:雖然不是必需的,但擁有相似大小和解析度的圖片有助於提高模型效能。
多樣性:為每個類別包含多種多樣的圖片,以涵蓋模型在真實世界場景中可能遇到的各種外觀和情境。
需要記住的一些要點
- zip 檔案應包含多個資料夾(類別),每個資料夾應包含單一類別的圖片。
- 資料夾的名稱應為類別名稱。
- 圖片必須是 jpeg、jpg 或 png 格式。
- 每個類別至少應有 5 張圖片。
- zip 檔案中不得有任何其他檔案。
- zip 資料夾內不得有任何其他資料夾。
解壓 train.zip 時,會建立兩個資料夾:cats 和 dogs。這兩個是用於分類的類別。兩個類別的圖片分別在各自的資料夾中。您可以根據需要設定任意多個類別。
列對映
對於影像分類,如果您使用 `zip` 資料集格式,列對映應為預設設定且不應更改。
data:
.
.
.
column_mapping:
image_column: image
target_column: label對於影像迴歸,列對映必須如下所示
data:
.
.
.
column_mapping:
image_column: image
target_column: target對於影像迴歸,`metadata.jsonl` 應包含每張圖片的 `file_name` 和 `target` 值。
如果您使用 Hugging Face Hub 上的資料集,應根據資料集設定適當的列對映。
訓練
本地訓練
要在本地訓練模型,請建立一個包含以下內容的配置檔案(config.yaml)
task: image_classification
base_model: google/vit-base-patch16-224
project_name: autotrain-cats-vs-dogs-finetuned
log: tensorboard
backend: local
data:
path: cats_vs_dogs
train_split: train
valid_split: null
column_mapping:
image_column: image
target_column: label
params:
epochs: 2
batch_size: 4
lr: 2e-5
optimizer: adamw_torch
scheduler: linear
gradient_accumulation: 1
mixed_precision: fp16
hub:
username: ${HF_USERNAME}
token: ${HF_TOKEN}
push_to_hub: true在這裡,我們使用來自 Hugging Face Hub 的 `cats_and_dogs` 資料集。模型訓練 2 個 epoch,批次大小為 4,學習率為 `2e-5`。我們使用 `adamw_torch` 最佳化器和 `linear` 排程器。我們還使用混合精度訓練,梯度累積為 1。
為了使用本地資料集,您可以將 `data` 部分更改為
data:
path: data/
train_split: train # this folder inside data/ will be used for training, it contains the images in subfolders.
valid_split: valid # this folder inside data/ will be used for validation, it contains the images in subfolders. can also be null.
column_mapping:
image_column: image
target_column: label同樣,對於影像迴歸,您可以使用以下配置檔案
task: image_regression
base_model: microsoft/resnet-50
project_name: autotrain-img-quality-resnet50
log: tensorboard
backend: local
data:
path: abhishek/img-quality-full
train_split: train
valid_split: null
column_mapping:
image_column: image
target_column: target
params:
epochs: 10
batch_size: 8
lr: 2e-3
optimizer: adamw_torch
scheduler: cosine
gradient_accumulation: 1
mixed_precision: fp16
hub:
username: ${HF_USERNAME}
token: ${HF_TOKEN}
push_to_hub: true要訓練模型,請執行以下命令
$ autotrain --config config.yaml
這將開始訓練過程,並在訓練完成後將模型儲存到 Hugging Face Hub。如果您不想將模型儲存到 Hub,可以在配置檔案中將 `push_to_hub` 設定為 `false`。
在 Hugging Face Spaces 上訓練
要在 Hugging Face Spaces 上訓練模型,請按照 `Quickstart` 部分中的說明建立一個訓練空間。
下面顯示了在 Hugging Face Spaces 上訓練影像評分模型的示例 UI
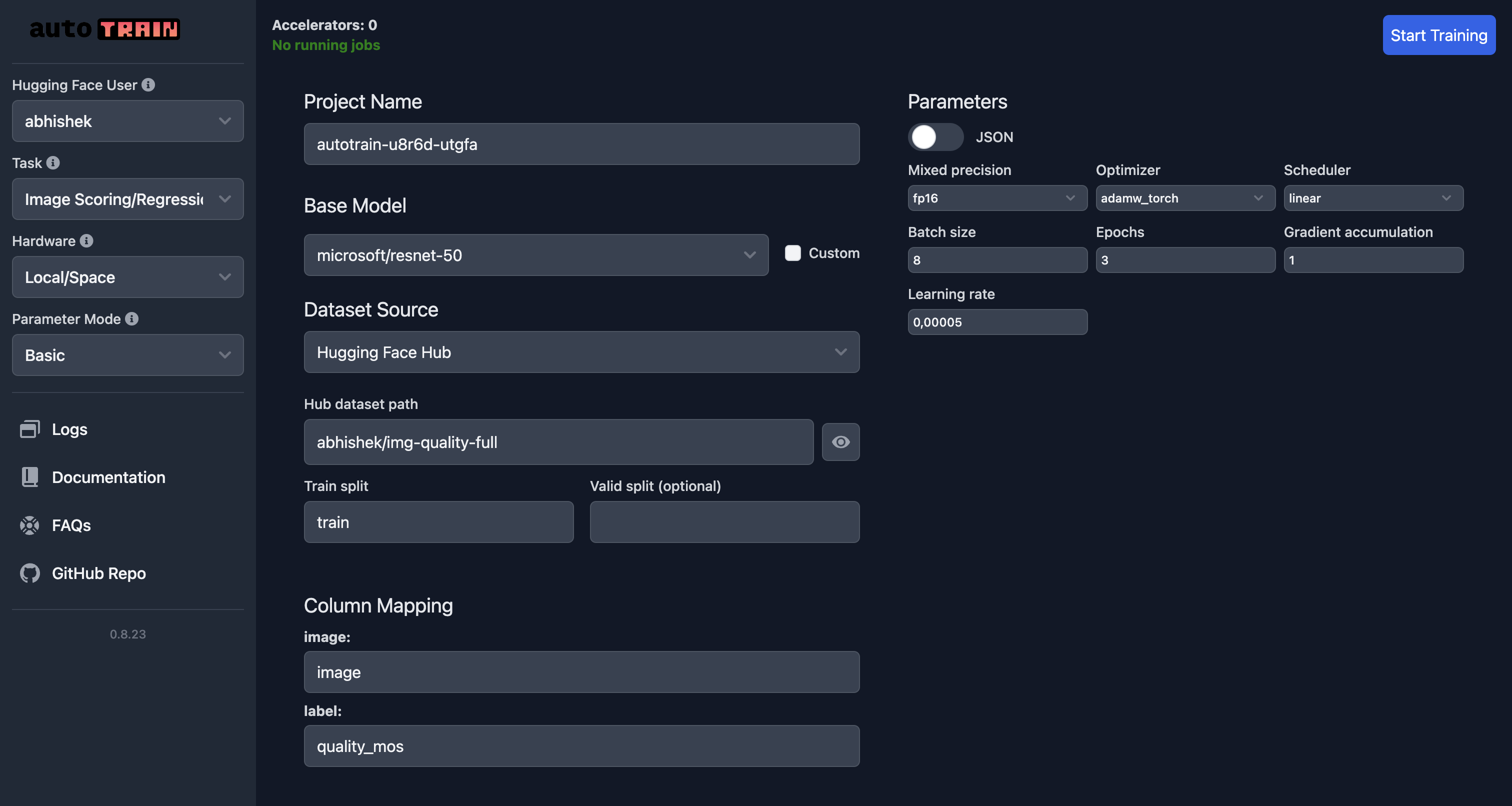
在此示例中,我們使用 `microsoft/resnet-50` 模型在 `abhishek/img-quality-full` 資料集上訓練影像評分模型。我們訓練模型 3 個 epoch,批次大小為 8,學習率為 `5e-5`。我們使用 `adamw_torch` 最佳化器和 `linear` 排程器。我們還使用混合精度訓練,梯度累積為 1。
請注意,列對映現已更改,`target` 指向資料集中的 `quality_mos` 列。
要訓練模型,請單擊 `Start Training` 按鈕。這將開始訓練過程,並在訓練完成後將模型儲存到 Hugging Face Hub。
引數
影像分類引數
class autotrain.trainers.image_classification.params.ImageClassificationParams
< 來源 >( data_path: str = None model: str = 'google/vit-base-patch16-224' username: typing.Optional[str] = None lr: float = 5e-05 epochs: int = 3 batch_size: int = 8 warmup_ratio: float = 0.1 gradient_accumulation: int = 1 optimizer: str = 'adamw_torch' scheduler: str = 'linear' weight_decay: float = 0.0 max_grad_norm: float = 1.0 seed: int = 42 train_split: str = 'train' valid_split: typing.Optional[str] = None logging_steps: int = -1 project_name: str = 'project-name' auto_find_batch_size: bool = False mixed_precision: typing.Optional[str] = None save_total_limit: int = 1 token: typing.Optional[str] = None push_to_hub: bool = False eval_strategy: str = 'epoch' image_column: str = 'image' target_column: str = 'target' log: str = 'none' early_stopping_patience: int = 5 early_stopping_threshold: float = 0.01 )
引數
- data_path (str) — 資料集的路徑。
- model (str) — 預訓練模型的名稱或路徑。預設為 “google/vit-base-patch16-224”。
- username (Optional[str]) — Hugging Face 賬戶使用者名稱。
- lr (float) — 最佳化器的學習率。預設為 5e-5。
- epochs (int) — 訓練的輪數。預設為 3。
- batch_size (int) — 訓練的批次大小。預設為 8。
- warmup_ratio (float) — 學習率排程器的預熱比例。預設為 0.1。
- gradient_accumulation (int) — 梯度累積的步數。預設為 1。
- optimizer (str) — 最佳化器型別。預設為 “adamw_torch”。
- scheduler (str) — 學習率排程器型別。預設為 “linear”。
- weight_decay (float) — 最佳化器的權重衰減。預設為 0.0。
- max_grad_norm (float) — 梯度裁剪的最大範數。預設為 1.0。
- seed (int) — 用於可復現性的隨機種子。預設為 42。
- train_split (str) — 訓練資料拆分的名稱。預設為 “train”。
- valid_split (Optional[str]) — 驗證資料拆分的名稱。
- logging_steps (int) — 記錄日誌的步數間隔。預設為 -1。
- project_name (str) — 輸出目錄的專案名稱。預設為 “project-name”。
- auto_find_batch_size (bool) — 自動尋找最佳批次大小。預設為 False。
- mixed_precision (Optional[str]) — 混合精度訓練模式(fp16、bf16 或 None)。
- save_total_limit (int) — 要保留的最大檢查點數量。預設為 1。
- token (Optional[str]) — 用於身份驗證的 Hugging Face Hub 令牌。
- push_to_hub (bool) — 是否將模型推送到 Hugging Face Hub。預設為 False。
- eval_strategy (str) — 訓練期間的評估策略。預設為 “epoch”。
- image_column (str) — 資料集中影像的列名。預設為 “image”。
- target_column (str) — 資料集中目標標籤的列名。預設為 “target”。
- log (str) — 用於實驗跟蹤的日誌記錄方法。預設為 “none”。
- early_stopping_patience (int) — 早停前無改進的輪數。預設為 5。
- early_stopping_threshold (float) — 早停的閾值。預設為 0.01。
ImageClassificationParams 是一個用於影像分類訓練引數的配置類。
影像迴歸引數
class autotrain.trainers.image_regression.params.ImageRegressionParams
< 來源 >( data_path: str = None model: str = 'google/vit-base-patch16-224' username: typing.Optional[str] = None lr: float = 5e-05 epochs: int = 3 batch_size: int = 8 warmup_ratio: float = 0.1 gradient_accumulation: int = 1 optimizer: str = 'adamw_torch' scheduler: str = 'linear' weight_decay: float = 0.0 max_grad_norm: float = 1.0 seed: int = 42 train_split: str = 'train' valid_split: typing.Optional[str] = None logging_steps: int = -1 project_name: str = 'project-name' auto_find_batch_size: bool = False mixed_precision: typing.Optional[str] = None save_total_limit: int = 1 token: typing.Optional[str] = None push_to_hub: bool = False eval_strategy: str = 'epoch' image_column: str = 'image' target_column: str = 'target' log: str = 'none' early_stopping_patience: int = 5 early_stopping_threshold: float = 0.01 )
引數
- data_path (str) — 資料集的路徑。
- model (str) — 要使用的模型名稱。預設為 “google/vit-base-patch16-224”。
- username (Optional[str]) — Hugging Face 使用者名稱。
- lr (float) — 學習率。預設為 5e-5。
- epochs (int) — 訓練輪數。預設為 3。
- batch_size (int) — 訓練批次大小。預設為 8。
- warmup_ratio (float) — 預熱比例。預設為 0.1。
- gradient_accumulation (int) — 梯度累積步數。預設為 1。
- optimizer (str) — 要使用的最佳化器。預設為 “adamw_torch”。
- scheduler (str) — 要使用的排程器。預設為 “linear”。
- weight_decay (float) — 權重衰減。預設為 0.0。
- max_grad_norm (float) — 最大梯度範數。預設為 1.0。
- seed (int) — 隨機種子。預設為 42。
- train_split (str) — 訓練集拆分名稱。預設為 “train”。
- valid_split (Optional[str]) — 驗證集拆分名稱。
- logging_steps (int) — 日誌記錄步數。預設為 -1。
- project_name (str) — 輸出目錄名稱。預設為 “project-name”。
- auto_find_batch_size (bool) — 是否自動查詢批處理大小。預設為 False。
- mixed_precision (Optional[str]) — 混合精度型別(fp16、bf16 或 None)。
- save_total_limit (int) — 儲存總數限制。預設為 1。
- token (Optional[str]) — Hub 令牌。
- push_to_hub (bool) — 是否推送到 Hub。預設為 False。
- eval_strategy (str) — 評估策略。預設為 “epoch”。
- image_column (str) — 影像列名稱。預設為 “image”。
- target_column (str) — 目標列名稱。預設為 “target”。
- log (str) — 使用實驗跟蹤進行日誌記錄。預設為 “none”。
- early_stopping_patience (int) — 提前停止的耐心值。預設為 5。
- early_stopping_threshold (float) — 提前停止的閾值。預設為 0.01。
ImageRegressionParams 是用於影像迴歸訓練引數的配置類。