推理端點(專用)文件
關於推理端點
並獲得增強的文件體驗
開始使用
關於推理端點
推理端點是一項託管服務,用於將您的 AI 模型部署到生產環境。基礎設施經過管理和配置,以便您可以專注於構建您的 AI 應用程式。
要將 AI 模型投入生產,您需要三個關鍵元件:
模型權重和工件:這些是定義 AI 模型的經過訓練的引數和檔案,儲存並在 Hugging Face Hub 上進行版本控制。
推理引擎:這是載入和執行模型以生成預測的軟體。流行的引擎包括 vLLM、TGI 等,每個引擎都針對不同的用例和效能需求進行了最佳化。
生產基礎設施:這就是推理端點。一個可擴充套件、安全且可靠的環境,您的模型在此環境中執行——處理請求、根據需求進行擴充套件並確保正常執行時間。
推理端點將所有這些元件整合到一項託管服務中。您從 Hub 中選擇模型,選擇推理引擎,然後推理端點負責其餘部分——調配基礎設施、部署模型,並透過簡單的 API 使其可訪問。這使您能夠專注於構建應用程式,而我們負責處理生產 AI 部署的複雜性。
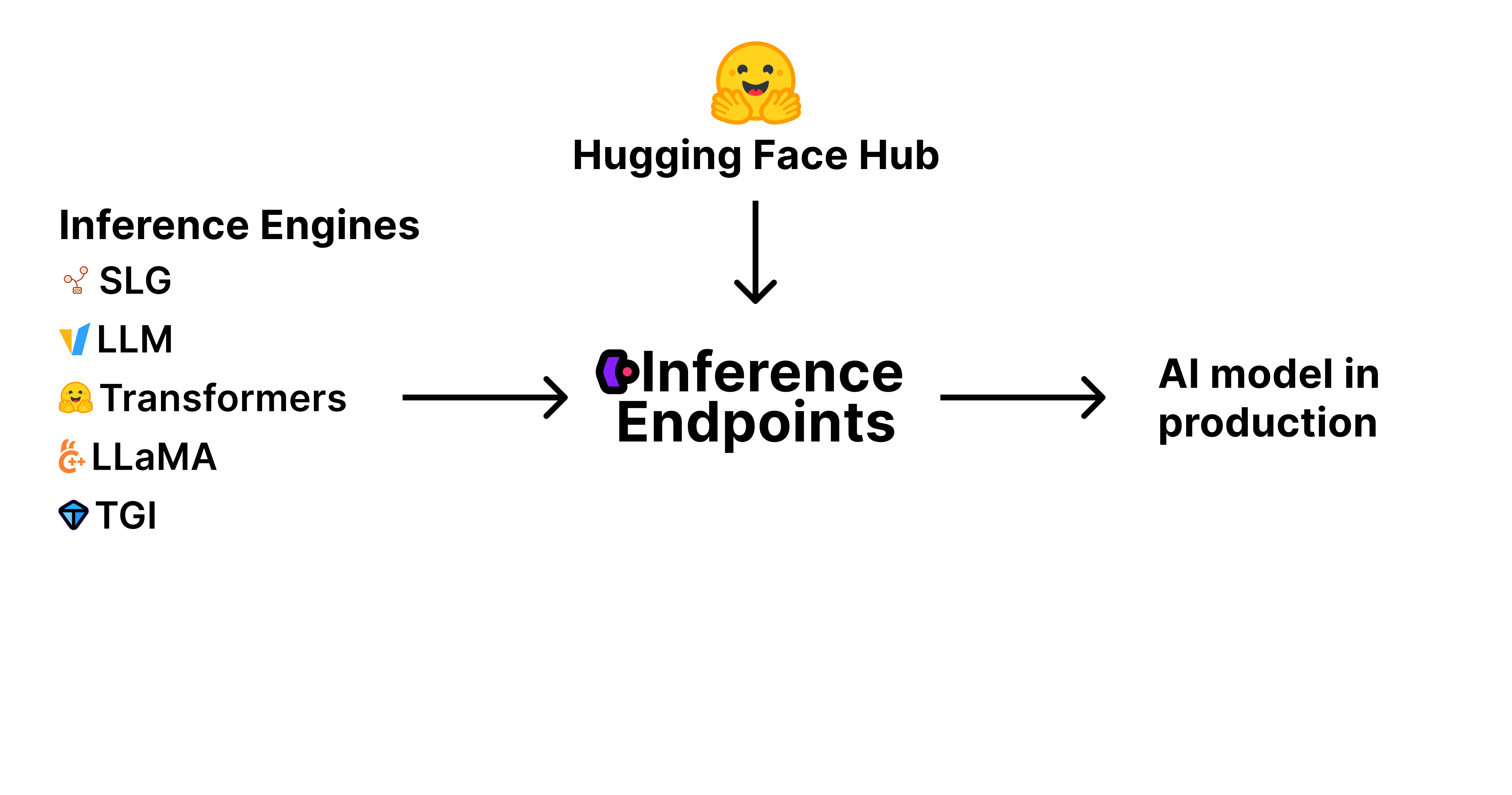
推理引擎
為此,我們已將推理端點打造成部署高效能開源推理引擎的中心位置。
目前,我們原生支援:
- vLLM
- 文字生成推理 (TGI)
- SGLang
- llama.cpp
- 以及文字嵌入推理 (TEI)
對於原生支援的引擎,我們嘗試設定合理的預設值,公開最相關的配置設定,並與維護推理引擎的團隊密切合作,以確保它們針對生產效能進行最佳化。
如果您在此處找不到您喜歡的引擎,請透過 api-enterprise@huggingface.co 與我們聯絡。
幕後
當您部署推理端點時,在幕後,您選擇的推理引擎(如 vLLM、TGI、SGLang 等)被打包並作為預構建的 Docker 容器啟動。此容器包含推理引擎軟體、您選擇的模型權重和工件(直接從 Hugging Face Hub 下載),以及您指定的任何配置或環境變數。
我們管理這些容器的完整生命週期:啟動、停止、擴充套件(包括自動擴充套件和縮放到零),以及監控它們的健康狀況和效能。這種編排由我們完全為您管理,因此您無需擔心容器化、網路或雲資源管理的複雜性。
企業或團隊訂閱
如需更多功能,請考慮訂閱 團隊版或企業版。
它讓您的組織對訪問控制、專屬支援等擁有更多控制權。功能包括:
- 更高效能 GPU 的更高配額
- 單點登入 (SSO)
- 訪問審計日誌
- 使用資源組管理團隊和專案訪問控制
- 您的儲存庫的私有儲存
- 停用建立公共儲存庫的功能(或預設將儲存庫設定為私有)
- 您可以請求基於合同的發票報價,該報價提供更多付款選項 + 預付積分
- 以及更多!