推理端點(專用)文件
分析和指標
並獲得增強的文件體驗
開始使用
分析和指標
“分析”頁面就像是您已部署模型的控制中心。它會即時顯示執行情況、呼叫模型的使用者數量、硬體使用情況、延遲等資訊。本文件將深入探討每個指標的含義以及如何分析圖表。
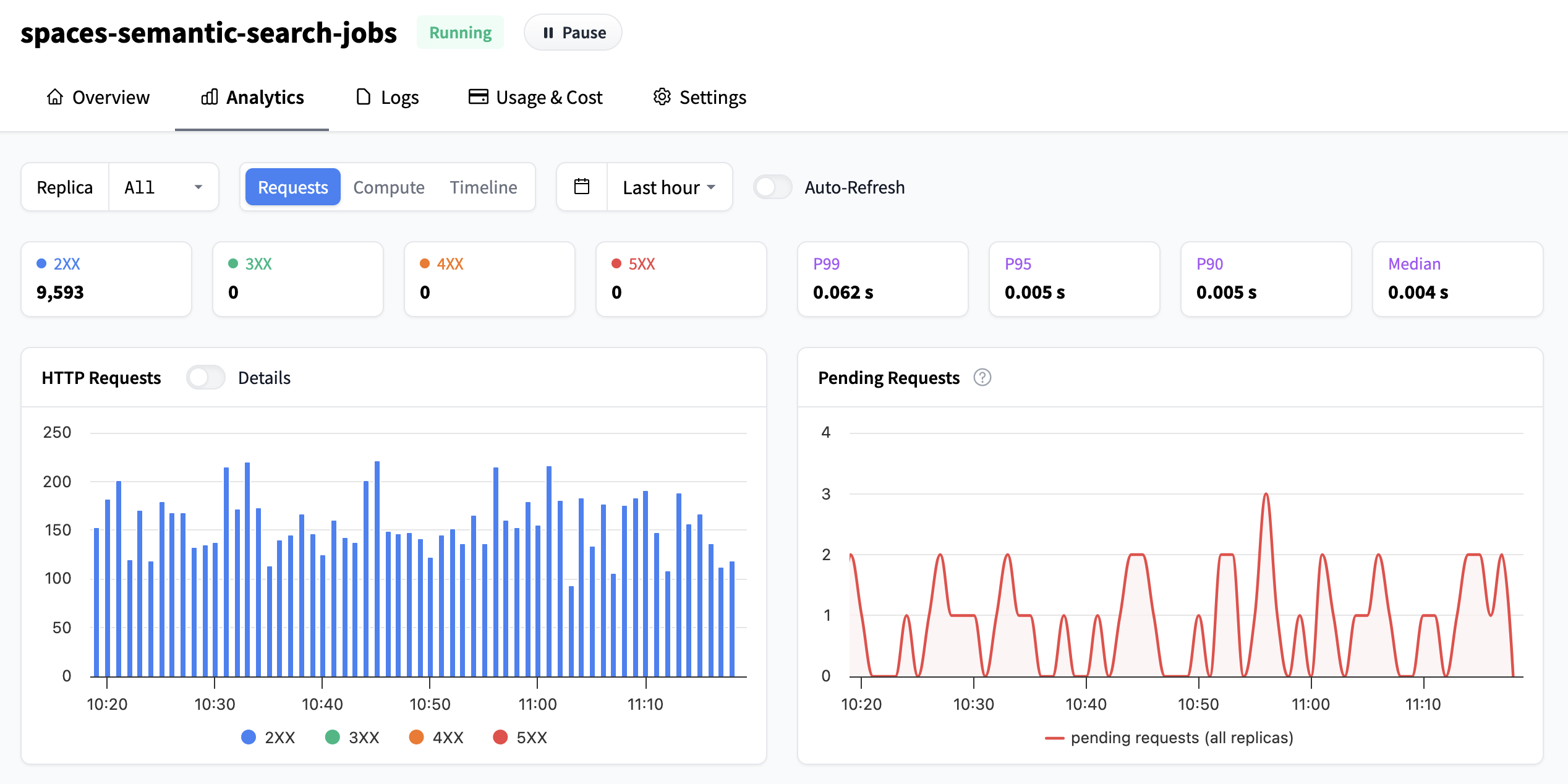
在頂部欄中,您可以配置檢視指標的時間範圍,此設定會影響頁面上的所有圖表。您可以從下拉列表中選擇任何現有設定,或在任何圖表上點選並拖動以設定自定義時間範圍。您還可以啟用/停用自動重新整理,或按副本或全部檢視指標。

理解圖表
請求數量
左上角的第一個圖表顯示您的推理端點收到的請求數量。預設情況下,它們按 HTTP 響應類別分組,但透過切換開關,您可以按單獨的狀態檢視它們。溫馨提示,HTTP 響應類別有:
- 資訊性響應 (100-199):伺服器已收到您的請求並正在處理。例如,
102 Processing表示伺服器仍在處理您的請求。 - 成功響應 (200-299):您的請求已成功接收並完成。例如,
200 OK表示一切正常。 - 重定向訊息 (300-399):伺服器告訴您的客戶端在其他地方查詢資訊或採取其他操作。例如,
301 Moved Permanently表示資源已有了新地址。 - 客戶端錯誤響應 (400-499):您的客戶端傳送的請求有問題(例如 URL 中的拼寫錯誤或缺少資料)。例如,
404 Not Found表示伺服器找不到您請求的內容。 - 伺服器錯誤響應 (500-599):伺服器在嘗試處理您的請求時遇到問題。例如,
502 Bad Gateway表示伺服器從它嘗試聯絡的另一個伺服器收到了無效響應。
我們建議查閱 MDN web docs 以獲取有關單個狀態碼的更多資訊。
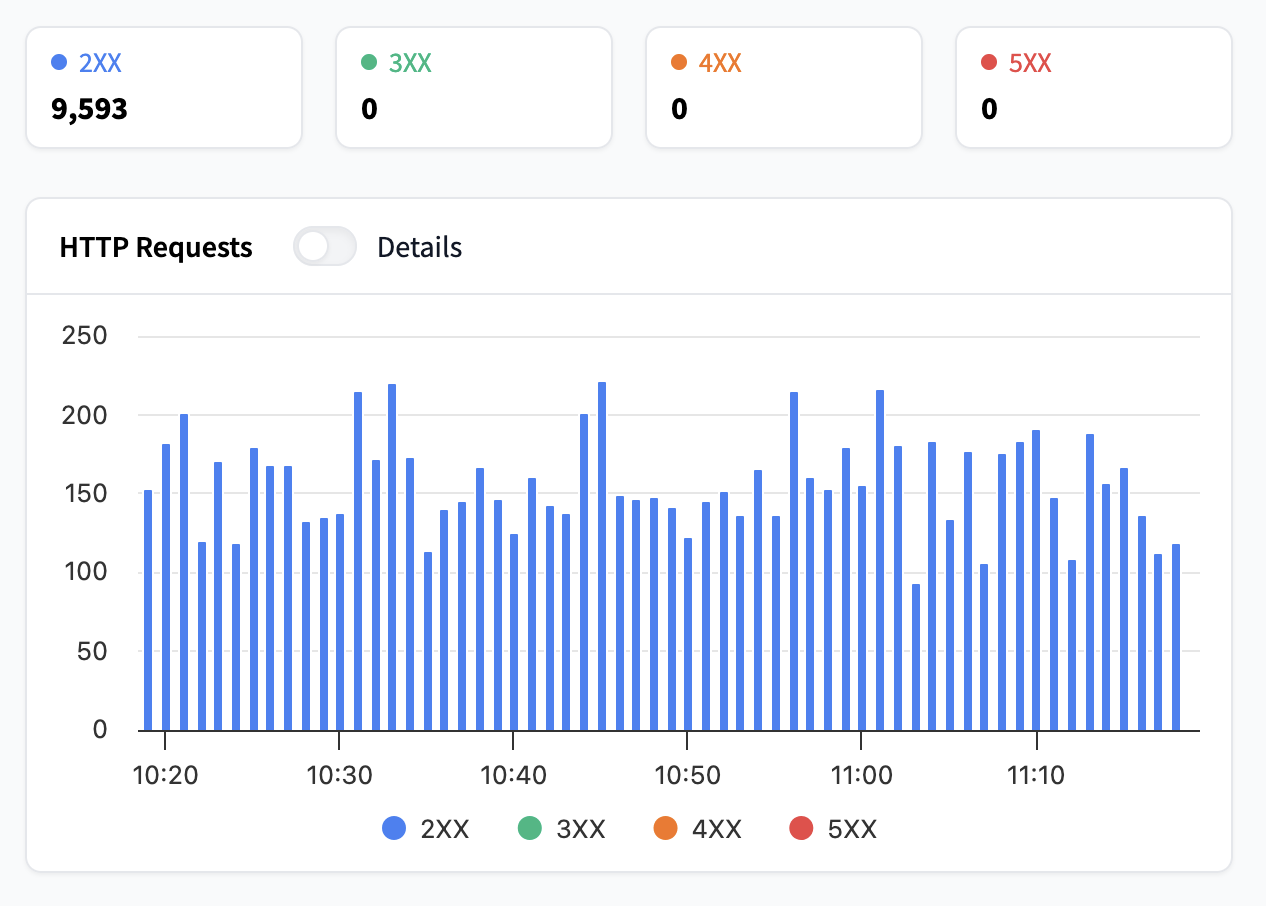
待處理請求
待處理請求是指尚未收到 HTTP 狀態的請求,這意味著它們包括正在進行中的請求和當前正在處理的請求。如果此指標增加過多,則表示您的請求正在排隊,並且您的使用者必須等待請求完成。在這種情況下,您應該考慮增加副本數量或使用自動擴縮,您可以在自動擴縮指南中閱讀更多相關資訊
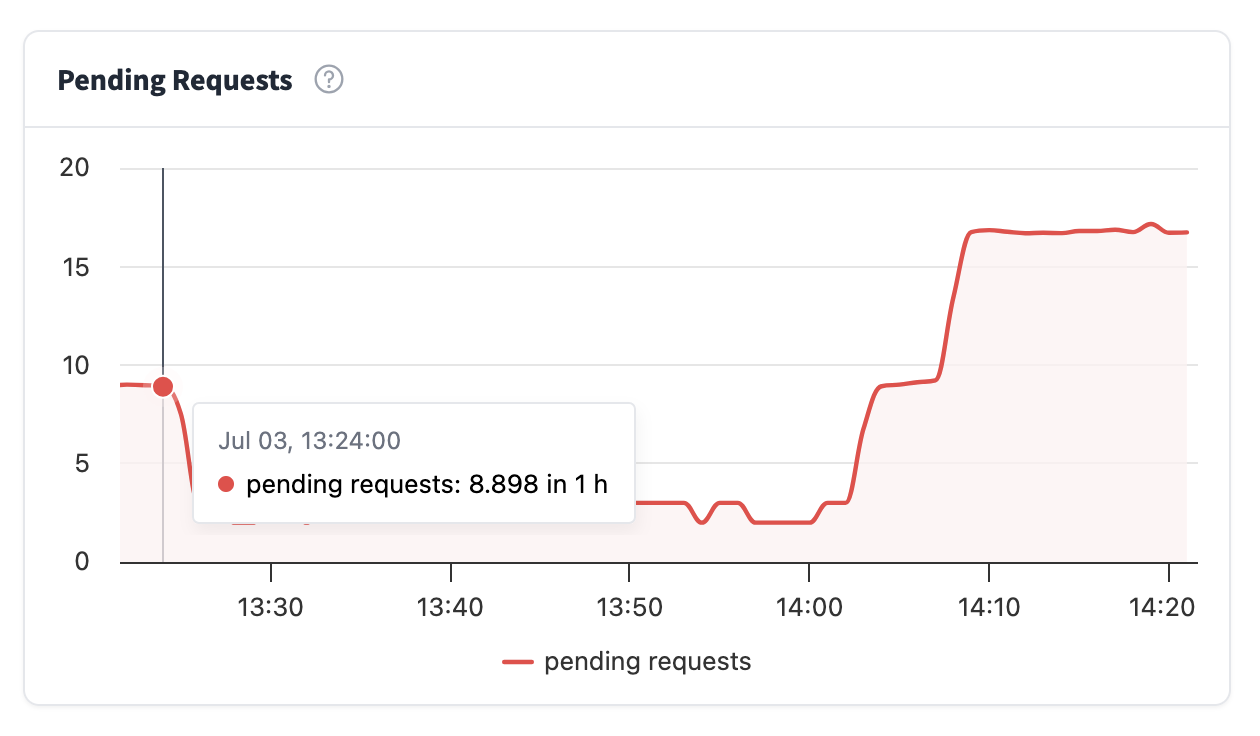
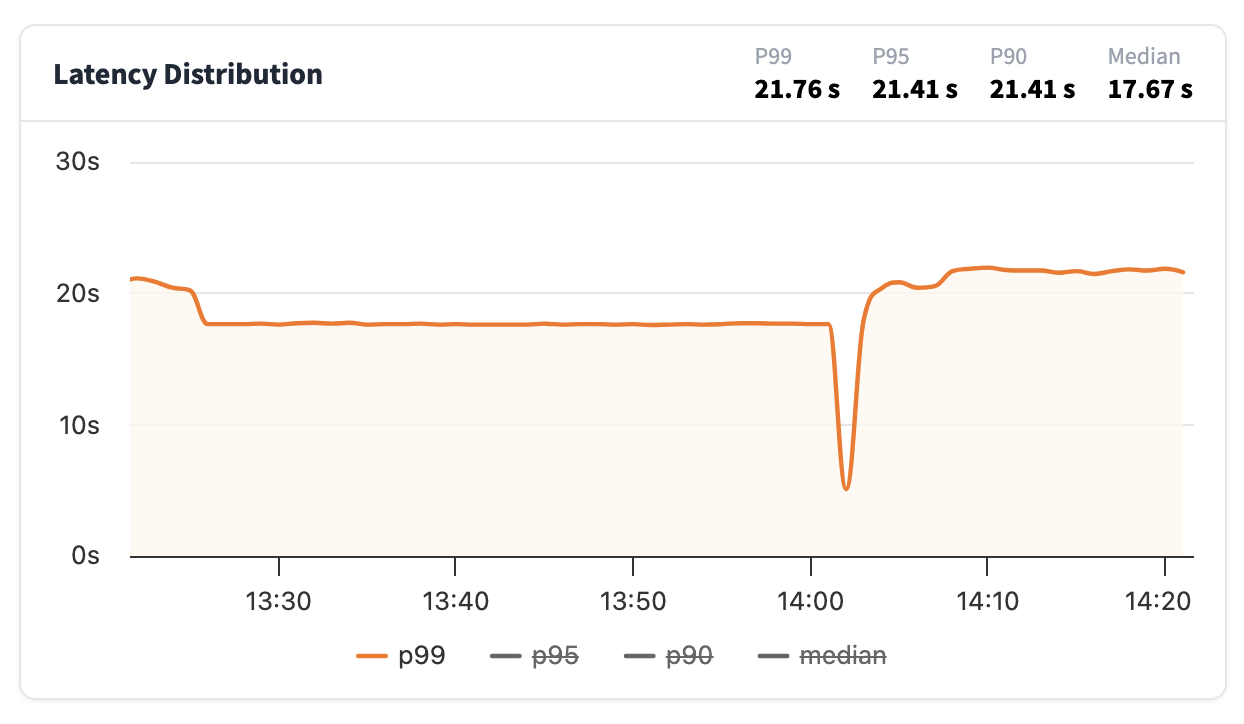
延遲分佈
從該圖表您可以檢視推理端點生成響應所需的時間。延遲報告如下:
- p99:表示 99% 的請求快於此值
- p95:表示 95% 的請求快於此值
- p90:表示 90% 的請求快於此值
- 中位數:表示 50% 的請求快於此值
通常,一個好的指標是檢視中位數和 p99 之間的差異有多大。值越接近,延遲越均勻;如果差異很大,則表示您的推理端點使用者通常響應速度很快,但最壞情況下的延遲可能會很長。
副本狀態
在副本狀態圖中,您將在基本檢視中看到在某個時間點有多少個正在執行的副本。紅線顯示了您當前的最大副本設定。

如果您切換高階設定,您將看到各個副本的不同狀態,從“待處理”一直到“正在執行”。這對於瞭解端點實際準備好服務請求所需的時間非常有用。

硬體使用情況
最後四個圖表專門用於顯示硬體使用情況。您會發現:
- CPU 使用率:正在使用的處理能力。
- 記憶體使用率:正在使用的 RAM 容量。
- GPU 使用率:正在使用的 GPU 處理能力。
- GPU 記憶體 (VRAM) 使用率:正在使用的 GPU 記憶體容量。
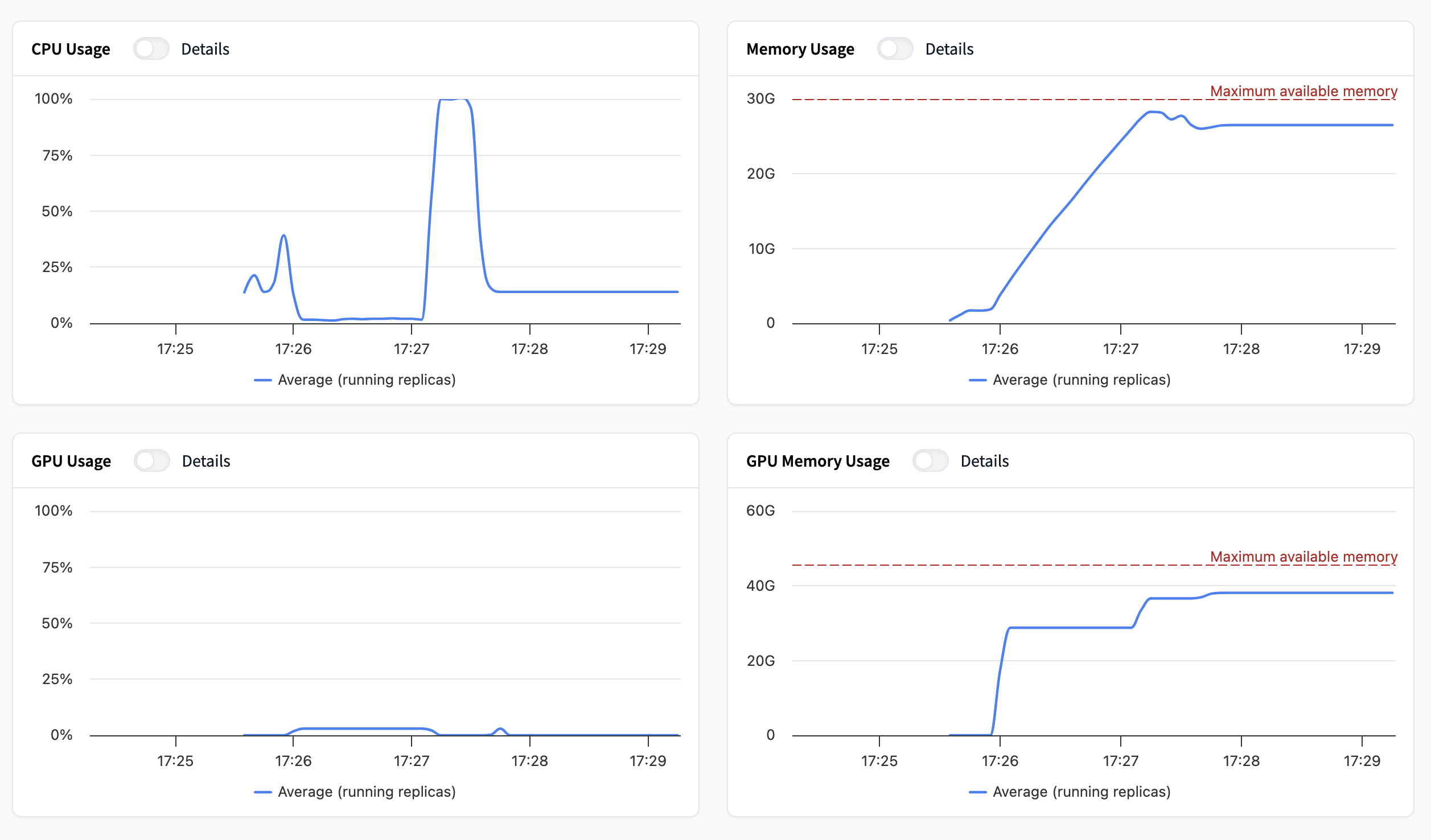
如果您啟用了基於硬體利用率的自動擴縮,這些指標將決定您的自動擴縮行為。您可以在此處閱讀有關自動擴縮的更多資訊。
使用推理端點指標 API 建立整合
此功能目前處於 Beta 階段。您需要訂閱企業版才能使用此功能。
您能夠將您的推理端點指標整合到您的內部工具中。
利用 OpenMetrics,您可以建立整合,以更精細地、幾乎即時地檢視您的端點指標,例如顯示:
- 按副本分組的請求
- 請求的延遲分佈
- 所有加速器型別的硬體指標
OpenMetrics 是一種標準化格式,用於表示和傳輸時間序列資料,使系統更容易消費和處理指標,確保資料結構最適合儲存和傳輸。
可以在您的內部工具中根據這些指標為您的端點設定進一步的配置和通知。
連線您的內部工具
有各種工具可與 OpenMetrics 配合使用。您需要設定一個代理。以下是一些示例文件可幫助您入門:
訂閱企業版
您可以隨時在 https://huggingface.co/enterprise?subscribe=true 註冊企業版計劃,起價為 $20/使用者/月。如有任何問題或功能請求,請傳送電子郵件至 api-enterprise@huggingface.co
< > 在 GitHub 上更新