推理端點(專用)文件
配置
加入 Hugging Face 社群
並獲得增強的文件體驗
開始使用
配置
本節描述了建立新推理端點時可用的配置選項。介面的每個部分都允許對模型如何部署、訪問和擴充套件進行精細控制。
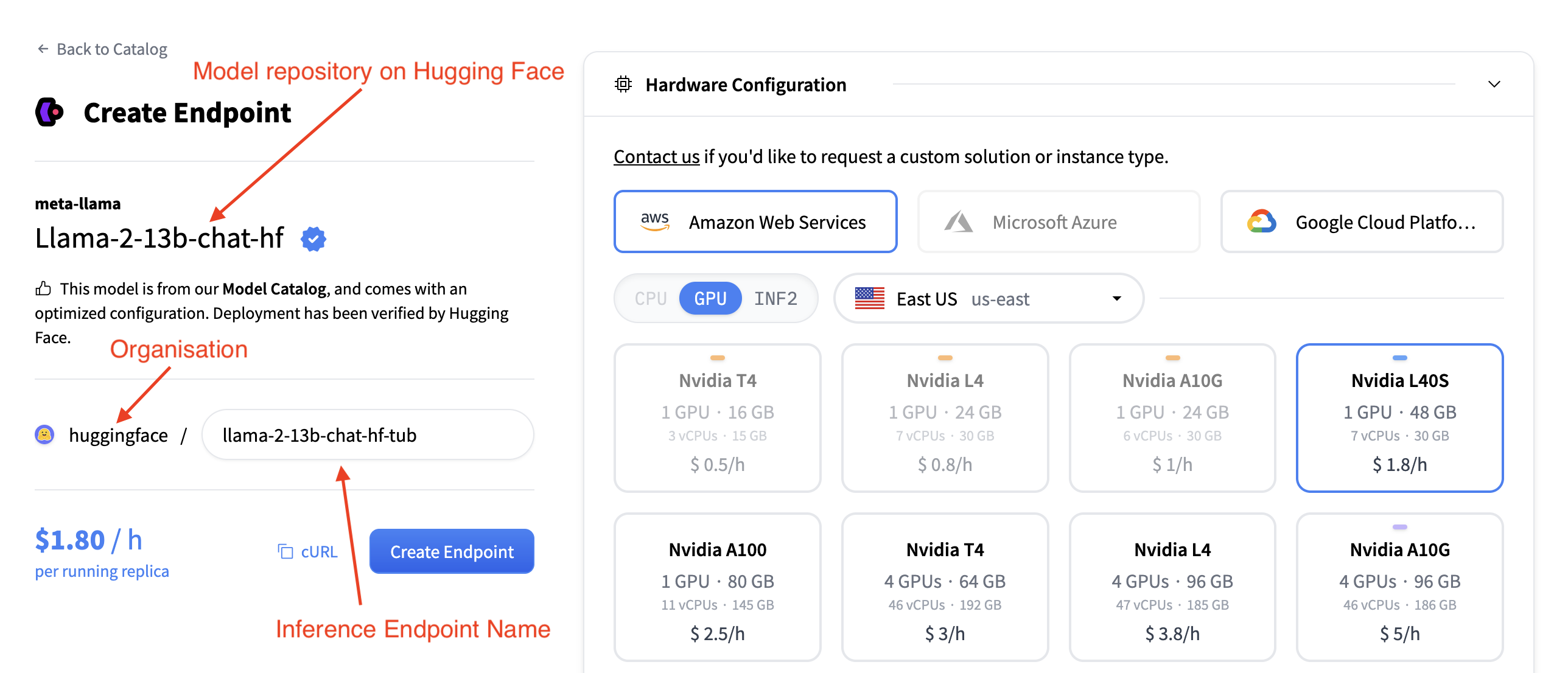
端點名稱、模型和組織
在左上角您可以
- 更改推理端點名稱
- 驗證您將此模型部署到哪個組織
- 驗證您正在部署哪個模型
- 以及您正在從哪個 Hugging Face Hub 倉庫部署此模型
硬體配置
硬體配置部分允許您選擇用於託管模型的計算後端。您可以從三個主要雲提供商中進行選擇:
- 亞馬遜網路服務 (AWS)
- Microsoft Azure
- 谷歌雲平臺
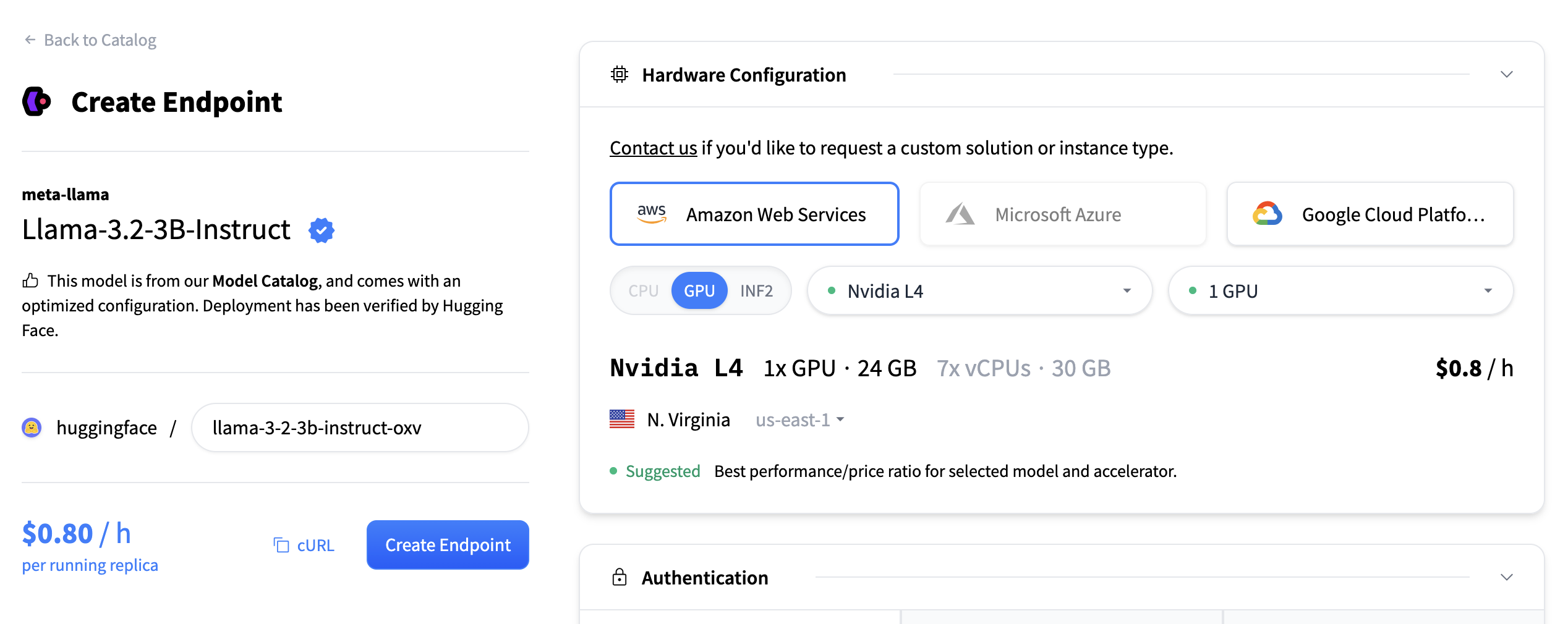
您還必須選擇加速器型別
- CPU
- GPU
- INF2 (AWS Inferentia)
此外,您可以使用下拉選單選擇部署區域(例如,美國東部)。選擇提供商、加速器和區域後,將顯示可用例項型別的列表。每個例項磁貼包括
- GPU 型別和數量
- 記憶體(例如,48 GB)
- vCPU 和 RAM
- 每小時定價(例如,$1.80/小時)
您可以選擇一個磁貼來為您的部署選擇該例項型別。在選定區域中不相容或不可用的例項將變灰且不可點選。
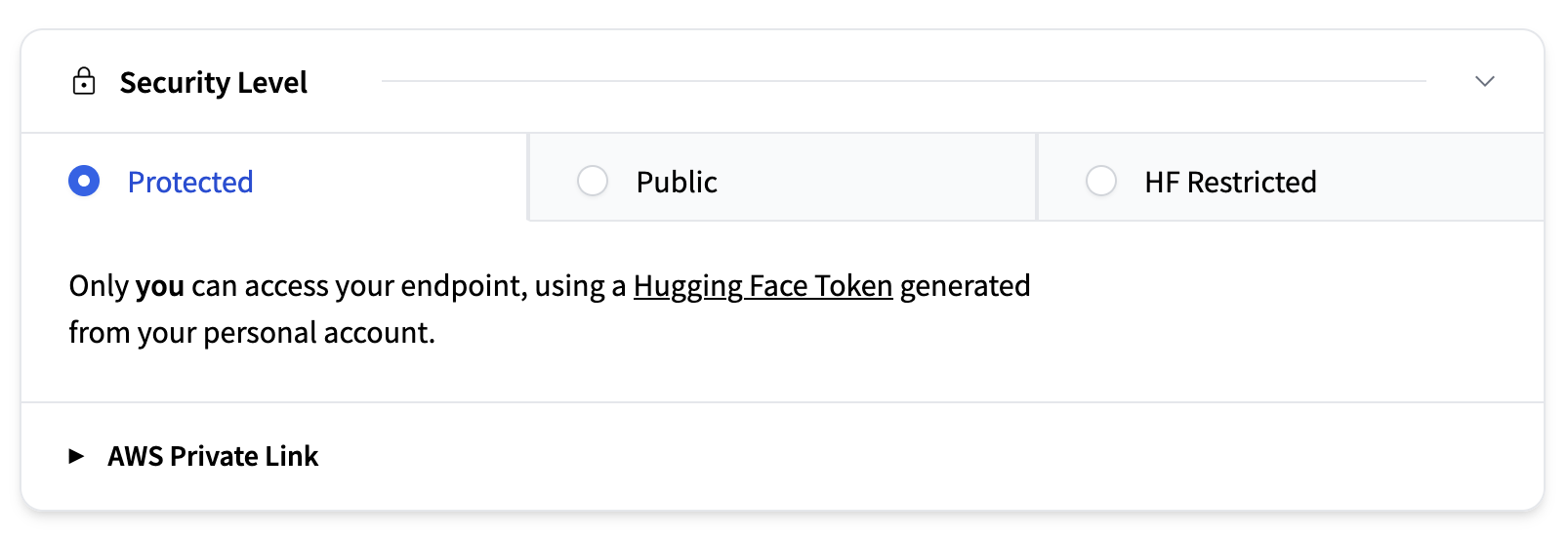
安全級別
本節確定誰可以訪問您部署的端點。可用選項包括
- 受保護(預設):僅供您的 Hugging Face 組織成員使用個人訪問令牌訪問。端點透過 TLS/SSL 進行保護。
- 公開:網際網路上的任何人都可以訪問該端點。
- HF 受限:任何擁有 Hugging Face 賬戶的人都可以透過其賬戶生成的個人 Hugging Face 令牌訪問。
- AWS 私有:端點僅透過區域內安全的 AWS PrivateLink 連線可用。
自動擴縮
自動擴縮部分配置了您的模型執行的副本數量,以及系統是否在不活動期間縮減到零。有關更多資訊,我們建議閱讀自動擴縮的深入指南。
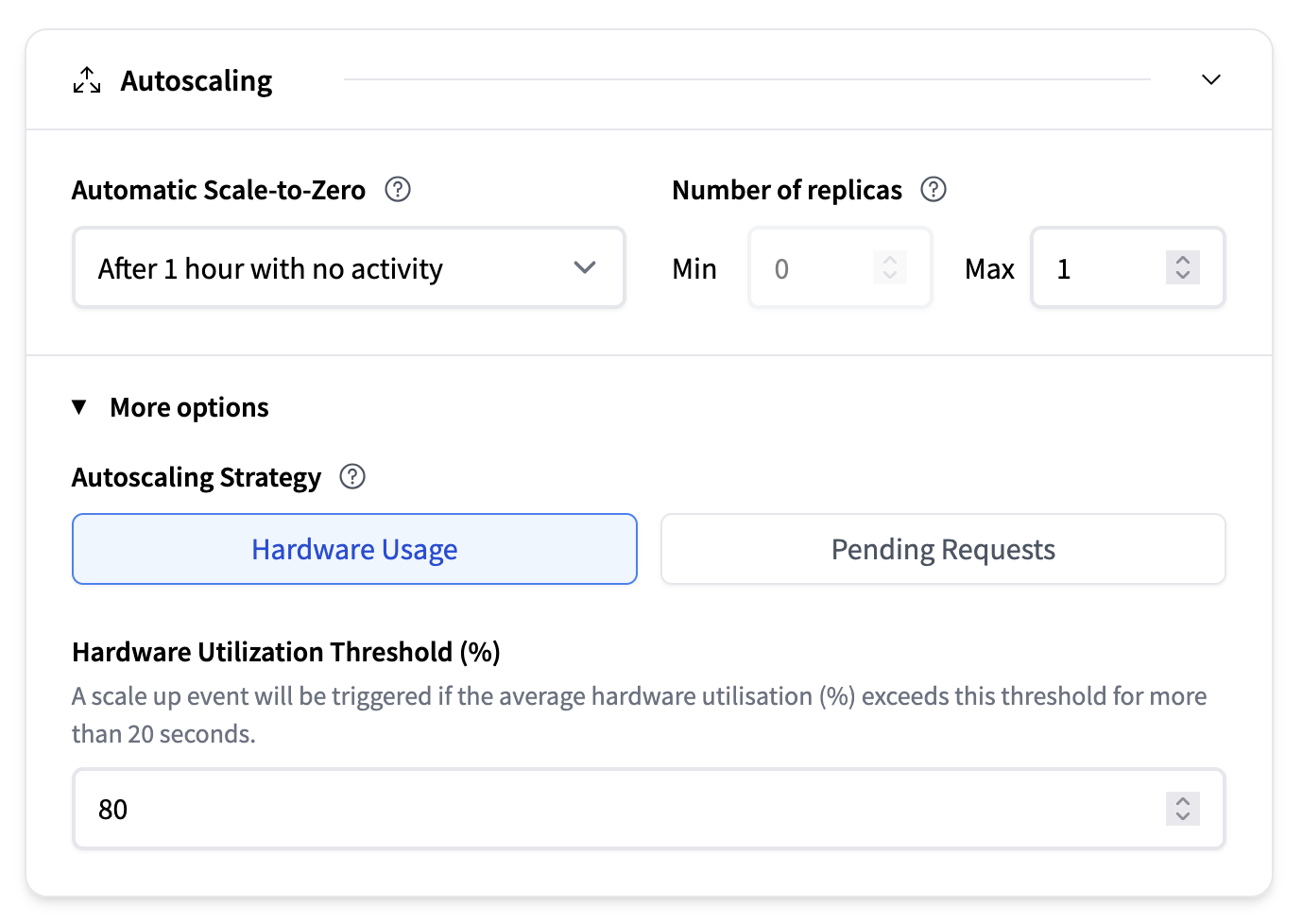
- 自動縮減到零:一個下拉選單讓您可以選擇系統在最後一次請求後應等待多長時間才能縮減到零。預設值為無活動 1 小時後。
- 副本數量:
- 最小值:保持執行的最小副本數量。請注意,啟用自動縮減到零要求將其設定為 0。
- 最大值:允許的最大副本數量(例如,1)
- 自動擴縮策略:
- 基於硬體使用率:例如,如果平均硬體利用率 (%) 超過此閾值超過 20 秒,將觸發擴縮事件。
- 待處理請求:如果待處理請求的平均數量超過此閾值超過 20 秒,將觸發擴縮事件。
容器配置
本節允許您指定託管模型的容器行為方式。此設定取決於所選的推理引擎。有關配置詳細資訊,請閱讀推理引擎部分。
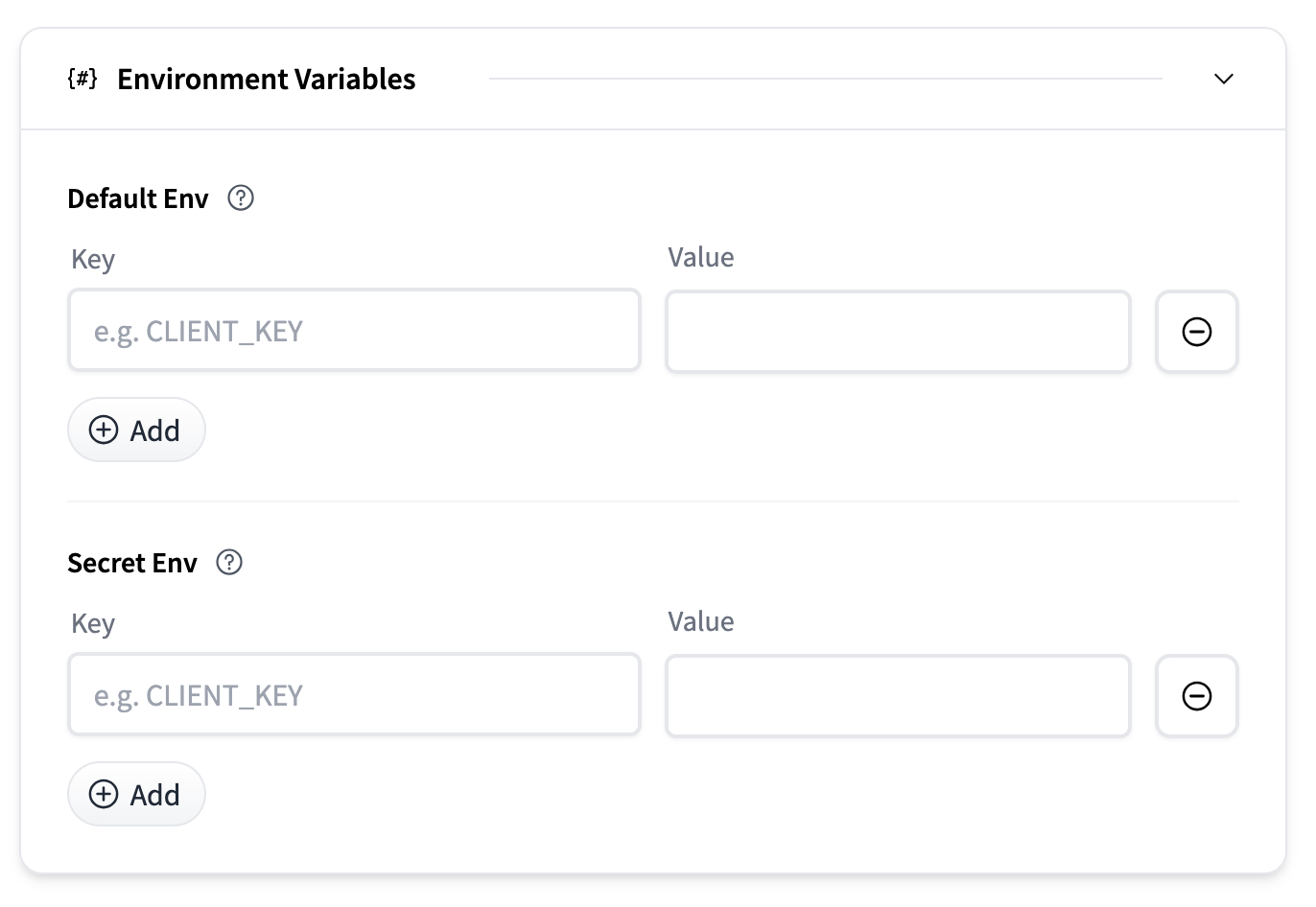
環境變數
可以提供環境變數來自定義容器行為或傳遞秘密。
- 預設環境變數:作為普通環境變數傳遞的鍵值對。
- 秘密環境變數:安全儲存並在執行時注入的鍵值對。
每個部分都允許您使用“新增”按鈕新增多個條目。
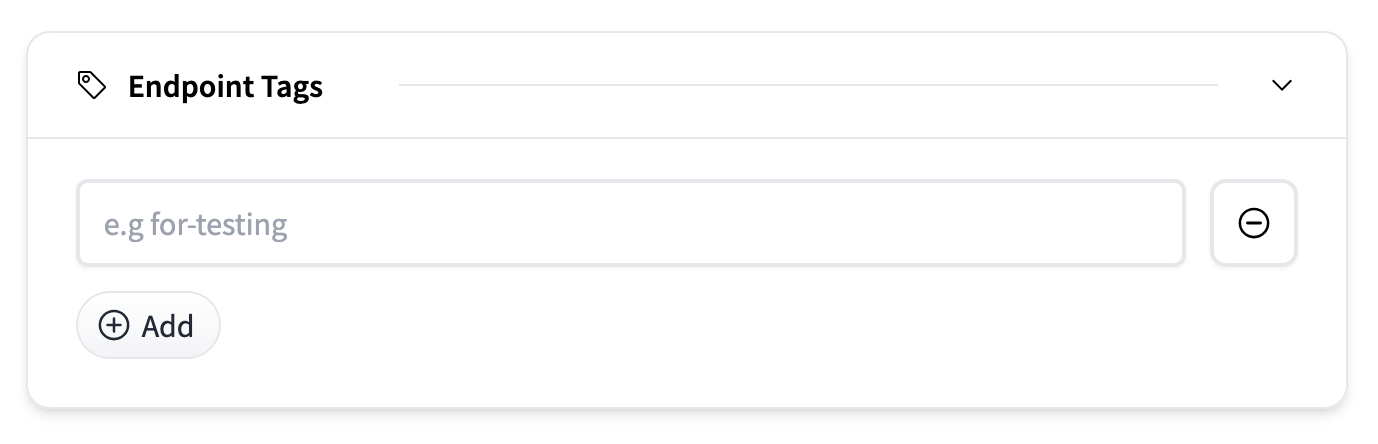
端點標籤
您可以使用標籤(例如,用於測試)標記端點,以幫助跨環境或團隊組織和管理部署。在儀表板中,您將能夠根據這些標籤過濾和排序端點。標籤是透過“新增”按鈕新增的純文字標籤。
高階設定
高階設定提供了對部署更精細的控制。
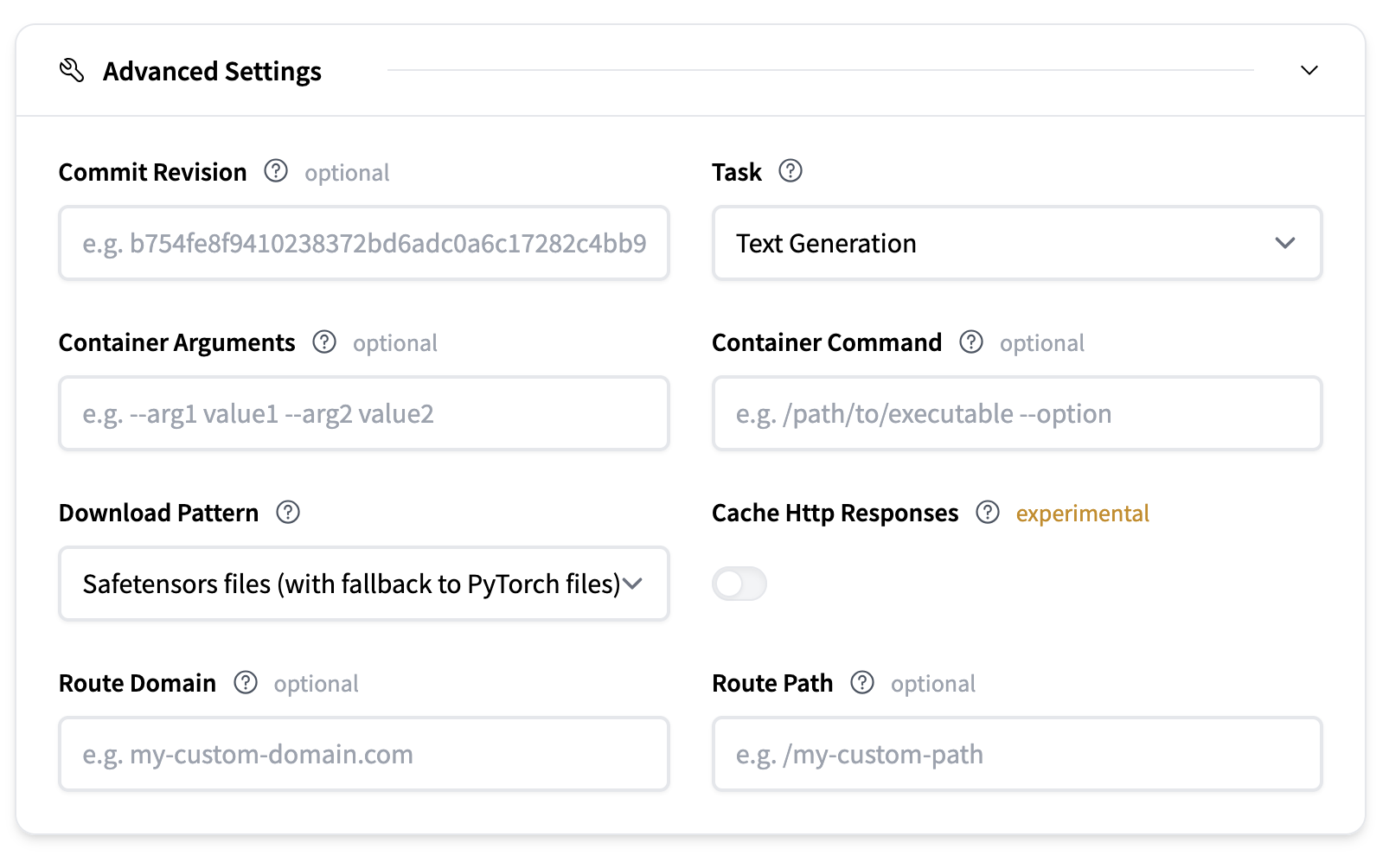
- 提交修訂:可選地指定一個提交雜湊,以確定您要從 Hugging Face Hub 上的模型倉庫下載哪個修訂的模型工件。
- 任務:定義模型任務的型別。這通常從模型倉庫推斷。
- 容器引數:向容器入口點傳遞 CLI 樣式引數。
- 容器命令:完全覆蓋容器入口點。
- 下載模式:定義要下載的模型檔案。