推理端點(專用)文件
建立您自己的轉錄應用程式
並獲得增強的文件體驗
開始使用
建立您自己的轉錄應用程式
本教程將指導您使用 Hugging Face 推理端點構建一個完整的轉錄應用程式。我們將建立一個能夠轉錄音訊檔案並生成帶有行動項的智慧摘要的應用程式——非常適合會議記錄、訪談或任何音訊內容。
本教程使用 Python 和 Gradio,但您可以將方法應用於任何可以發出 HTTP 請求的語言。部署在推理端點上的模型使用標準 API,因此您可以將它們整合到 Web 應用程式、移動應用程式或任何其他系統中。
建立轉錄端點
首先,我們需要為音訊轉錄建立一個推理端點。我們將使用 OpenAI 的 Whisper 模型進行高質量語音識別。
首先導航到 Inference Endpoints UI,登入後您應該會看到一個用於建立新推理端點的按鈕。單擊“New”按鈕。
從那裡您將被定向到目錄。模型目錄包含流行的模型,這些模型已調整配置以實現一鍵部署。您可以按名稱、任務、硬體價格等進行篩選。
搜尋“whisper”以查詢轉錄模型,或者您可以使用 openai/whisper-large-v3 建立自定義端點。此模型為多種語言提供出色的轉錄質量,並處理各種音訊格式。
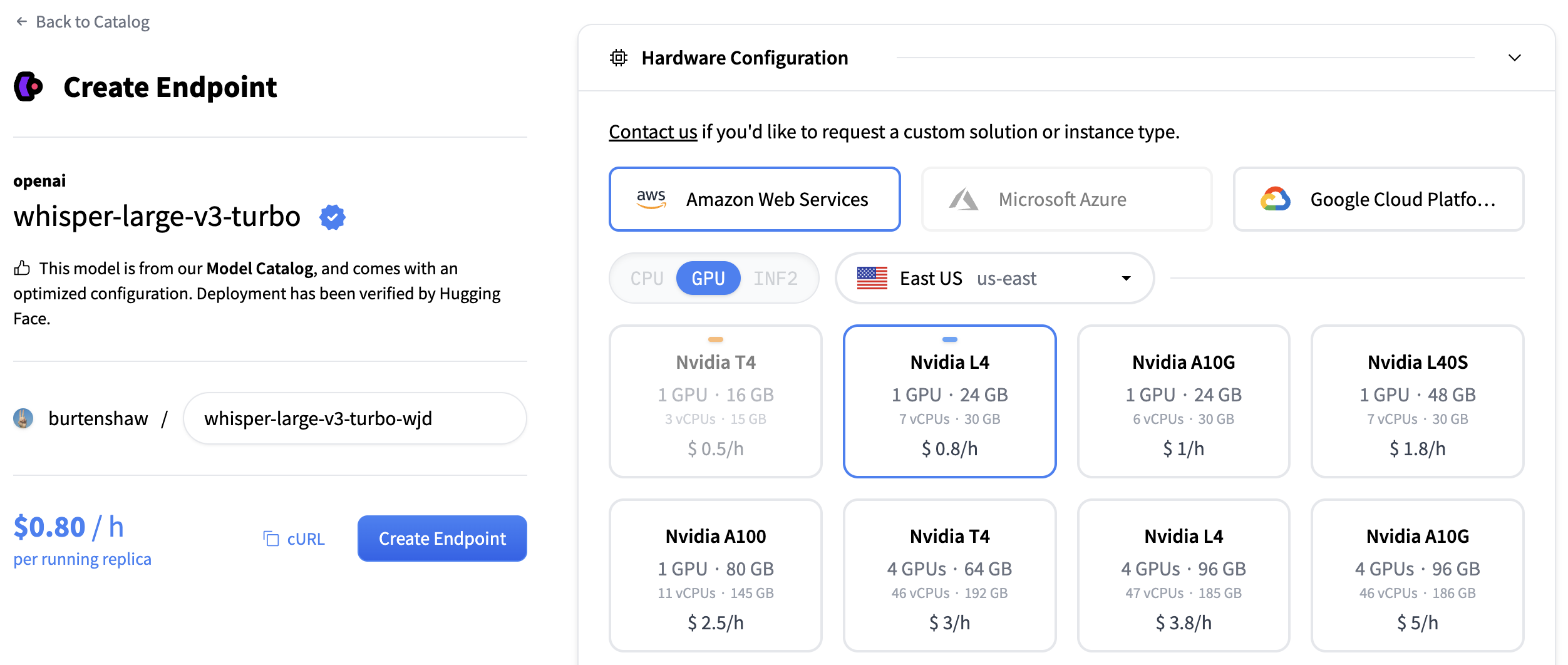
對於轉錄模型,我們建議使用
- GPU:NVIDIA L4 或 A10G,用於音訊處理,效能良好
- 例項大小:x1(足以滿足大多數轉錄工作負載)
- 自動縮放:啟用縮放到零以在使用時節省成本
點選“建立端點”部署您的轉錄服務。
您的端點將需要大約 5 分鐘來初始化。一旦準備就緒,您將在“執行中”狀態下看到它。
建立文字生成端點
現在我們再次執行相同的操作,但這次是針對文字生成模型。為了生成摘要和行動項,我們將使用 Qwen/Qwen3-1.7B 模型建立第二個端點。
遵循相同的過程
- 點選推理端點 UI 中的“新建”按鈕
- 在目錄中搜索
qwen3 1.7b - 此模型建議使用 NVIDIA L4 和 x1 例項大小
- 保留預設設定(啟用縮放到零,1 小時超時)
- 點選“建立端點”
此模型已針對文字生成任務進行最佳化,並將提供出色的摘要功能。兩個端點都將需要大約 3-5 分鐘來初始化。
測試您的端點
一旦您的端點執行起來,您就可以在 playground 中測試它們。轉錄端點將接受音訊檔案並返回文字轉錄。
使用簡短的音訊樣本進行測試,以驗證轉錄質量。
獲取您的端點詳細資訊
您需要從您的端點頁面獲取端點詳細資訊。
- 基本 URL:
https://<endpoint-name>.endpoints.huggingface.cloud/v1/ - 模型名稱: 您的端點名稱
- 令牌: 您從設定獲取的 HF 令牌
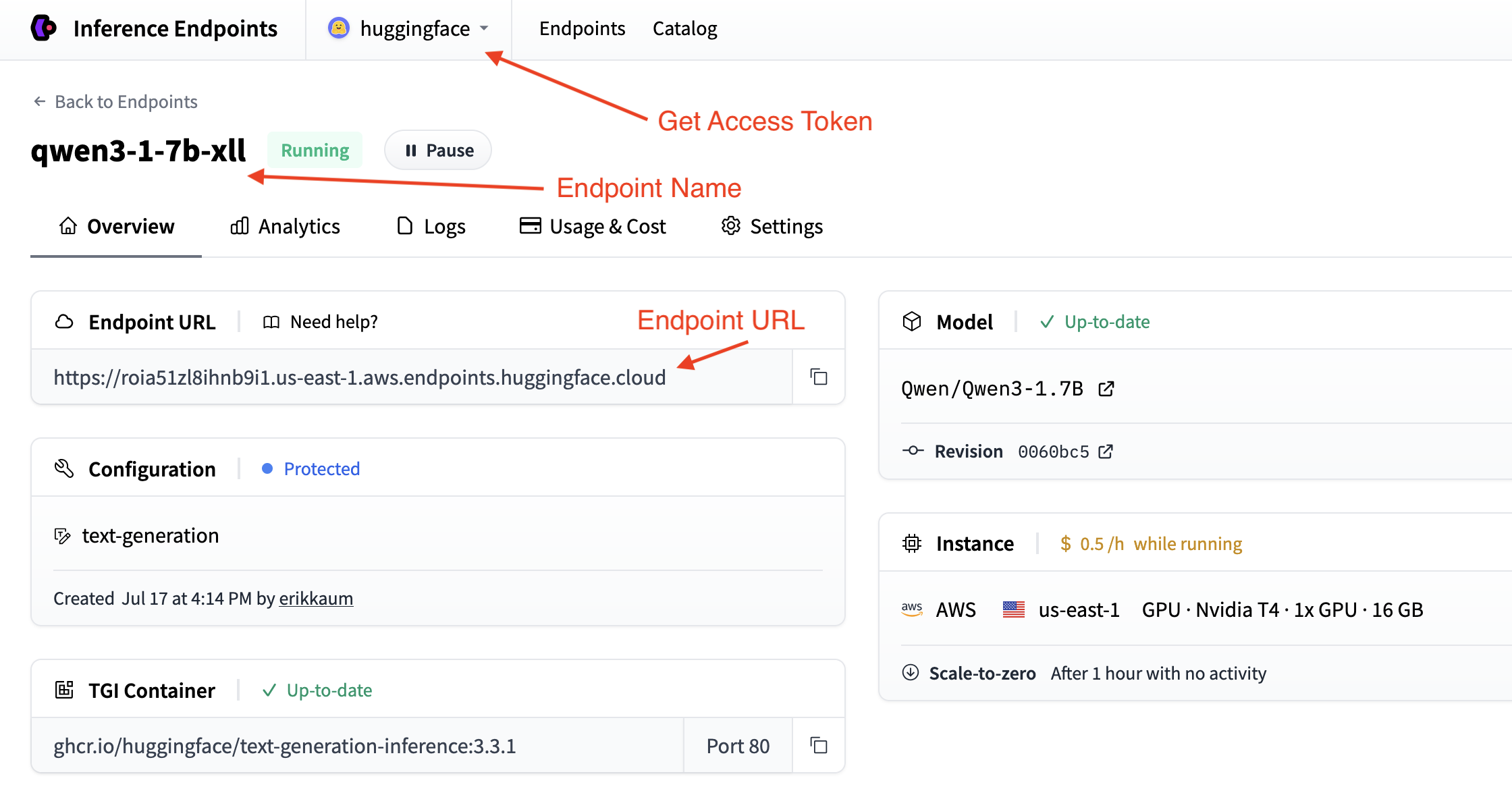
您可以透過在命令列中使用 curl 測試您的端點來驗證您的詳細資訊。
curl "<endpoint-url>" \
-X POST \
--data-binary '@<audio-file>' \
-H "Accept: application/json" \
-H "Content-Type: audio/flac" \構建轉錄應用程式
現在我們一步步構建一個轉錄應用程式。我們將它分解成邏輯塊,以建立一個完整的解決方案,可以轉錄音訊並生成智慧摘要。
步驟 1:設定依賴項和匯入
我們將使用 requests 庫連線到兩個端點,並使用 gradio 建立介面。讓我們安裝所需的軟體包。
pip install gradio requests
然後,在一個新的 Python 檔案中設定您的匯入。
import os
import gradio as gr
import requests步驟 2:配置您的端點連線
根據您在之前步驟中收集的詳細資訊,設定連線轉錄和摘要端點的配置。
# Configuration for both endpoints
TRANSCRIPTION_ENDPOINT = "https://your-whisper-endpoint.endpoints.huggingface.cloud/api/v1/audio/transcriptions"
SUMMARIZATION_ENDPOINT = "https://your-qwen-endpoint.endpoints.huggingface.cloud/v1/chat/completions"
HF_TOKEN = os.getenv("HF_TOKEN") # Your Hugging Face Hub token
# Headers for authentication
headers = {
"Authorization": f"Bearer {HF_TOKEN}"
}您的端點現在已配置為處理音訊轉錄和文字摘要。
您可能還需要使用 os.getenv 來獲取您的端點詳細資訊。
步驟 3:建立轉錄函式
接下來,我們將建立一個函式來處理音訊檔案上傳和轉錄
def transcribe_audio(audio_file_path):
"""Transcribe audio using direct requests to the endpoint"""
# Read audio file and prepare for upload
with open(audio_file_path, "rb") as audio_file:
# Read the audio file as binary data and represent it as a file object
files = {"file": audio_file.read()}
# Make the request to the transcription endpoint
response = requests.post(TRANSCRIPTION_ENDPOINT, headers=headers, files=files)
# Check if the request was successful
if response.status_code == 200:
result = response.json()
return result.get("text", "No transcription available")
else:
return f"Error: {response.status_code} - {response.text}"轉錄端點期望在 files 引數中上傳檔案。請確保將音訊檔案讀取為二進位制資料並正確傳遞給 API。
步驟 4:建立摘要函式
現在我們將建立一個函式來從轉錄的文字中生成摘要。我們將進行一些簡單的提示工程以獲得最佳結果。
def generate_summary(transcript):
"""Generate summary using requests to the chat completions endpoint"""
# define a nice prompt to get the best results for our use case
prompt = f"""
Analyze this meeting transcript and provide:
1. A concise summary of key points
2. Action items with responsible parties
3. Important decisions made
Transcript: {transcript}
Format with clear sections:
## Summary
## Action Items
## Decisions Made
"""
# Prepare the payload using the Messages API format
payload = {
"model": "your-qwen-endpoint-name", # Use the name of your endpoint
"messages": [{"role": "user", "content": prompt}],
"max_tokens": 1000, # we can also set a max_tokens parameter to limit the length of the response
"temperature": 0.7, # we might want to set lower temperature for more deterministic results
"stream": False # we don't need streaming for this use case
}
# Headers for chat completions
chat_headers = {
"Accept": "application/json",
"Content-Type": "application/json",
"Authorization": f"Bearer {HF_TOKEN}"
}
# Make the request
response = requests.post(SUMMARIZATION_ENDPOINT, headers=chat_headers, json=payload)
response.raise_for_status()
# Parse the response
result = response.json()
return result["choices"][0]["message"]["content"]步驟 5:整合所有功能
現在讓我們構建 Gradio 介面。我們將使用 gr.Interface 類來建立一個簡單的介面,允許我們上傳音訊檔案並檢視轉錄和摘要。
首先,我們將建立一個處理完整工作流程的主處理函式。
def process_meeting_audio(audio_file):
"""Main processing function that handles the complete workflow"""
if audio_file is None:
return "Please upload an audio file.", ""
try:
# Step 1: Transcribe the audio
transcript = transcribe_audio(audio_file)
# Step 2: Generate summary from transcript
summary = generate_summary(transcript)
return transcript, summary
except Exception as e:
return f"Error processing audio: {str(e)}", ""然後,我們可以在 Gradio 介面中執行該函式。我們將新增一些描述和標題,使其更易於使用者使用。
# Create Gradio interface
app = gr.Interface(
fn=process_meeting_audio,
inputs=gr.Audio(label="Upload Meeting Audio", type="filepath"),
outputs=[
gr.Textbox(label="Full Transcript", lines=10),
gr.Textbox(label="Meeting Summary", lines=8),
],
title="🎤 AI Meeting Notes",
description="Upload audio to get instant transcripts and summaries.",
)就是這樣!您現在可以使用 python app.py 在本地執行應用程式並進行測試。
點選檢視完整指令碼
import gradio as gr
import os
import requests
# Configuration for both endpoints
TRANSCRIPTION_ENDPOINT = "https://your-whisper-endpoint.endpoints.huggingface.cloud/api/v1/audio/transcriptions"
SUMMARIZATION_ENDPOINT = "https://your-qwen-endpoint.endpoints.huggingface.cloud/v1/chat/completions"
HF_TOKEN = os.getenv("HF_TOKEN") # Your Hugging Face Hub token
# Headers for authentication
headers = {
"Authorization": f"Bearer {HF_TOKEN}"
}
def transcribe_audio(audio_file_path):
"""Transcribe audio using direct requests to the endpoint"""
# Read audio file and prepare for upload
with open(audio_file_path, "rb") as audio_file:
files = {"file": audio_file.read()}
# Make the request to the transcription endpoint
response = requests.post(TRANSCRIPTION_ENDPOINT, headers=headers, files=files)
if response.status_code == 200:
result = response.json()
return result.get("text", "No transcription available")
else:
return f"Error: {response.status_code} - {response.text}"
def generate_summary(transcript):
"""Generate summary using requests to the chat completions endpoint"""
prompt = f"""
Analyze this meeting transcript and provide:
1. A concise summary of key points
2. Action items with responsible parties
3. Important decisions made
Transcript: {transcript}
Format with clear sections:
## Summary
## Action Items
## Decisions Made
"""
# Prepare the payload using the Messages API format
payload = {
"model": "your-qwen-endpoint-name", # Use the name of your endpoint
"messages": [{"role": "user", "content": prompt}],
"max_tokens": 1000,
"temperature": 0.7,
"stream": False
}
# Headers for chat completions
chat_headers = {
"Accept": "application/json",
"Content-Type": "application/json",
"Authorization": f"Bearer {HF_TOKEN}"
}
# Make the request
response = requests.post(SUMMARIZATION_ENDPOINT, headers=chat_headers, json=payload)
response.raise_for_status()
# Parse the response
result = response.json()
return result["choices"][0]["message"]["content"]
def process_meeting_audio(audio_file):
"""Main processing function that handles the complete workflow"""
if audio_file is None:
return "Please upload an audio file.", ""
try:
# Step 1: Transcribe the audio
transcript = transcribe_audio(audio_file)
# Step 2: Generate summary from transcript
summary = generate_summary(transcript)
return transcript, summary
except Exception as e:
return f"Error processing audio: {str(e)}", ""
# Create Gradio interface
app = gr.Interface(
fn=process_meeting_audio,
inputs=gr.Audio(label="Upload Meeting Audio", type="filepath"),
outputs=[
gr.Textbox(label="Full Transcript", lines=10),
gr.Textbox(label="Meeting Summary", lines=8),
],
title="🎤 AI Meeting Notes",
description="Upload audio to get instant transcripts and summaries.",
)
if __name__ == "__main__":
app.launch()
部署您的轉錄應用程式
現在,讓我們將其部署到 Hugging Face Spaces,以便所有人都可以使用它!
- 建立一個新空間:前往 huggingface.co/new-space
- 選擇 Gradio SDK 並將其設定為公開
- 上傳您的檔案:上傳
app.py和所有依賴項 - 新增您的令牌:在空間設定中,將
HF_TOKEN新增為金鑰 - 配置硬體:考慮使用 GPU 以加快處理速度
- 啟動:您的應用程式將在
https://huggingface.co/spaces/your-username/your-space-name上上線
您的轉錄應用程式現在已準備好處理會議記錄、採訪、播客以及任何其他需要轉錄和摘要的音訊內容!
下一步
幹得好!您現在已經構建了一個具有智慧摘要功能的完整轉錄應用程式。
以下是一些擴充套件轉錄應用程式的方法:
- 多語言支援:新增語言檢測並支援多種語言
- 說話人識別:使用來自 Hub 的具有說話人分離功能的模型。
- 自定義提示:允許使用者自定義摘要格式和樣式
- 實現文字轉語音:使用來自 Hub 的模型將您的摘要轉換為另一個音訊檔案!