推理端點(專用)文件
文字生成推理 (TGI)
加入 Hugging Face 社群
並獲得增強的文件體驗
開始使用
文字生成推理 (TGI)
TGI 是一個用 Rust 和 Python 構建的生產級推理引擎,旨在為開源 LLM(例如 LLaMA、Falcon、StarCoder、BLOOM 等)提供高效能服務。使 TGI 成為一個好選擇的核心功能是:
- 連續批處理 + 流式傳輸:透過伺服器傳送事件 (SSE) 動態分組進行中的請求並流式傳輸令牌
- 最佳化注意力與解碼:TGI 使用 Flash Attention、Paged Attention、KV 快取和自定義 CUDA 核心來提高延遲和記憶體效率
- 量化與權重載入速度:支援 bitsandbytes 和 GPTQ 等量化方法,並使用 Safetensors 減少載入時間
- 生產就緒:完全相容 OpenAI 的
/v1/chat或/v1/completionsAPI、Prometheus 指標、OpenTelemetry 跟蹤、水印、邏輯控制、JSON schema 指導
預設情況下,TGI 版本將是最新可用的版本(可能會有一些延遲)。但您也可以透過更改容器 URL 來指定不同的版本
配置
當選擇要部署的模型時,推理端點 UI 會自動檢查模型是否受 TGI 支援。如果支援,您將在“容器配置”下看到此選項,您可以在其中更改以下設定:
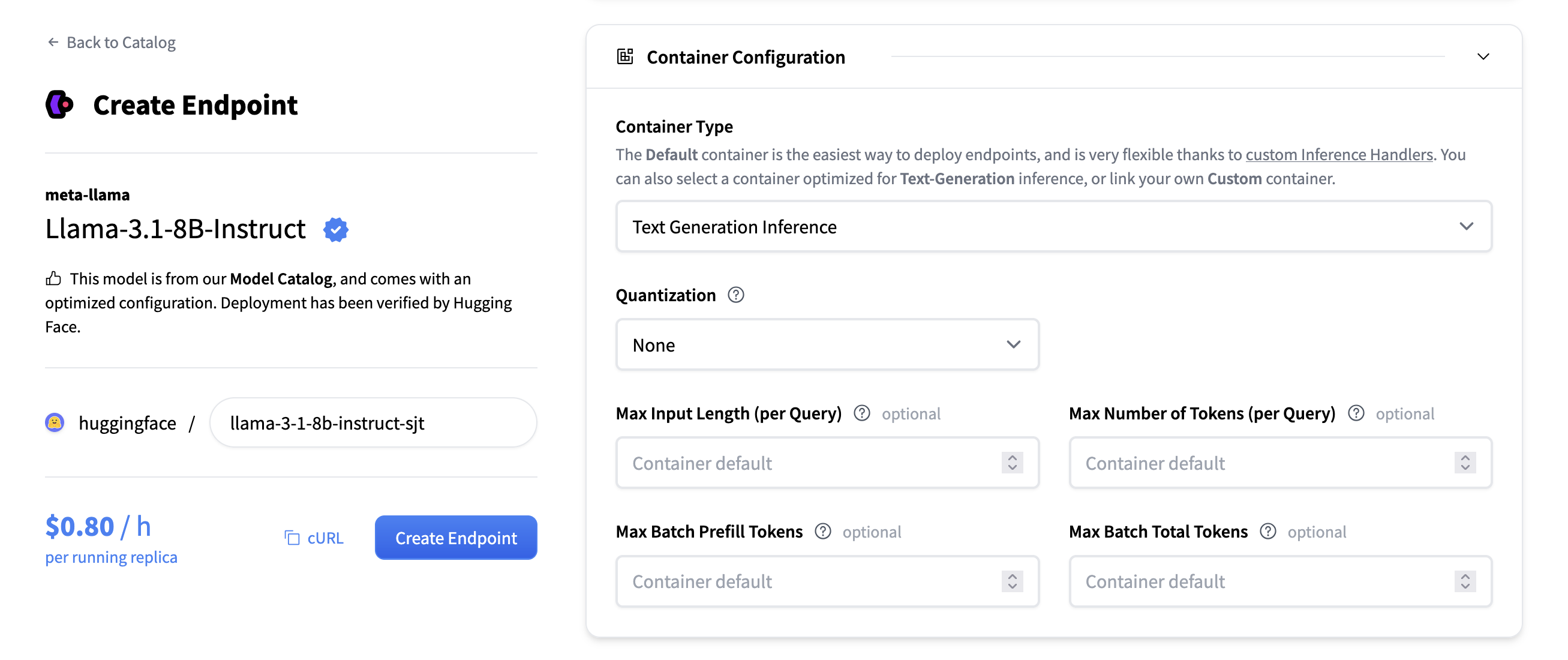
- 量化:模型要使用的量化方法(如果有)。
- 最大令牌數(每個查詢):更改請求可包含的最大令牌數。例如,
1512的值表示使用者可以傳送1000個令牌的提示並生成512個新令牌,或者傳送1個令牌的提示並生成1511個新令牌。此值越大,每個請求在 RAM 中佔用的空間越大,批處理效果越差。 - 最大輸入令牌數(每個查詢):最大輸入令牌數,即提示中的令牌數。
- 最大批預填充令牌數:限制預填充操作的令牌數。預填充令牌是隨使用者提示一起傳送的令牌。
- 最大批總令牌數:這將更改批處理中潛在令牌的總量。結合“最大令牌數”,這決定了您可以同時服務的併發請求數。如果您將“最大令牌數”設定為 100,並將“最大批總令牌數”也設定為 100,則一次只能服務一個請求。
通常建議在大多數情況下使用零配置(見下文)。TGI 支援其他幾個配置引數,您可以在 TGI 文件中找到完整的列表。所有這些都可以透過將值作為環境變數傳遞給容器來設定,連結到指南。
零配置
TGI v3 中引入的零配置模式可幫助您充分利用硬體,而無需手動配置和反覆試驗。如果將值留空,TGI 將在伺服器啟動時自動(根據執行的硬體)為最大輸入長度、最大令牌數、最大批預填充令牌數和最大批總令牌數選擇最大可能值。這意味著您將充分利用硬體容量。
請注意,有一個注意事項:假設您正在部署 `meta-llama/Llama-3.3-70B-Instruct`,其上下文長度為 128k 令牌。但是您使用的 GPU 只能將模型的上下文三次放入記憶體。因此,如果您想以完整上下文長度提供模型,則只能服務多達 3 個併發請求。在某些情況下,將最大上下文長度降低到 64k 令牌是可以的,這將允許伺服器處理 6 個併發請求。您可以透過將最大輸入長度設定為 64k,然後讓 TGI 自動配置其餘部分來配置此項。
支援的模型
您可以在以下位置找到 TGI 支援的模型:
- 在 Hugging Face Hub 上瀏覽支援的模型
- 在 TGI 文件的支援模型部分
- 在 推理端點目錄中選擇熱門模型
如果模型受 TGI 支援,推理端點 UI 將透過啟用/停用“容器型別”配置下的選擇來指示此情況。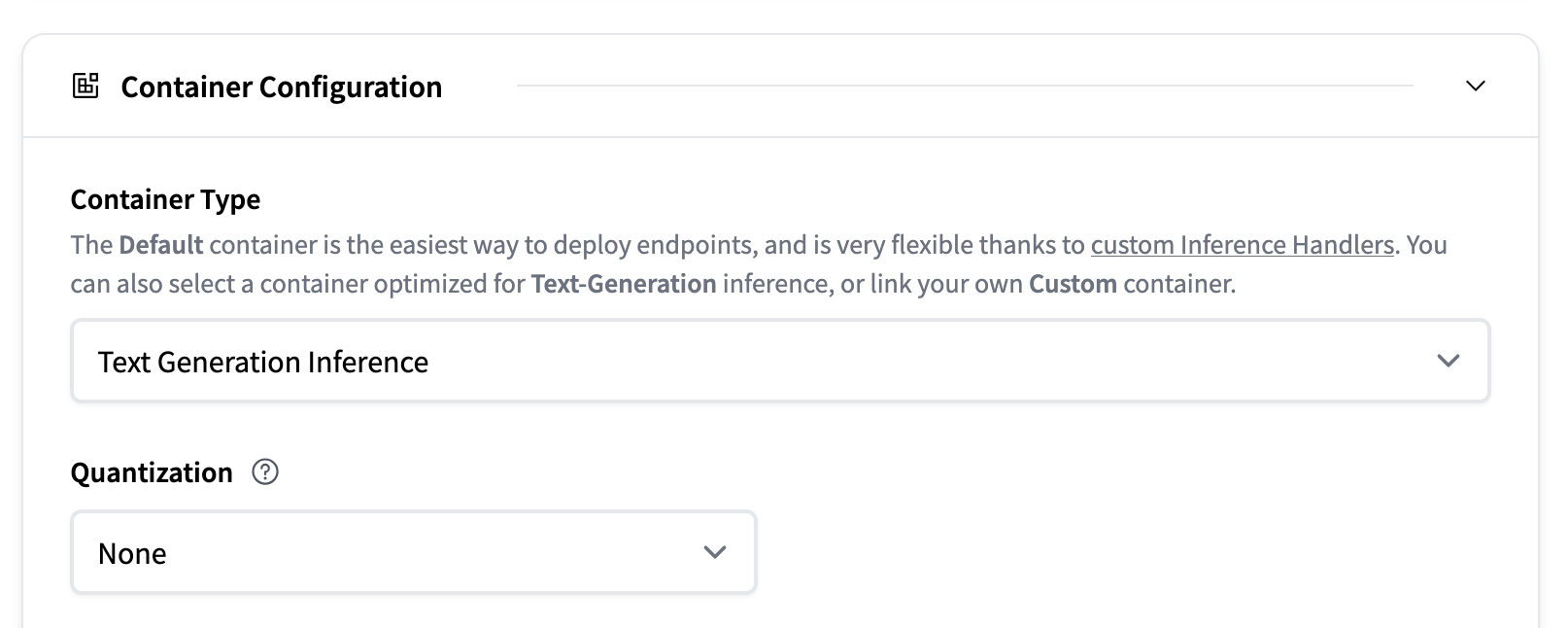
參考資料
我們還建議閱讀 TGI 文件,以獲取更深入的資訊。
< > 在 GitHub 上更新