推理端點(專用)文件
快速入門
並獲得增強的文件體驗
開始使用
快速開始
在本指南中,您將僅需幾分鐘即可使用推理端點部署生產就緒型 AI 模型。請確保您已使用 Hugging Face 帳戶登入 推理端點 UI,並且已設定付款方式。如果尚未設定,請在您的賬單設定中快速新增有效的付款方式。
建立您的端點
首先導航到推理端點 UI,登入後,您應該會看到一個用於建立新推理端點的按鈕。單擊“新建”按鈕。
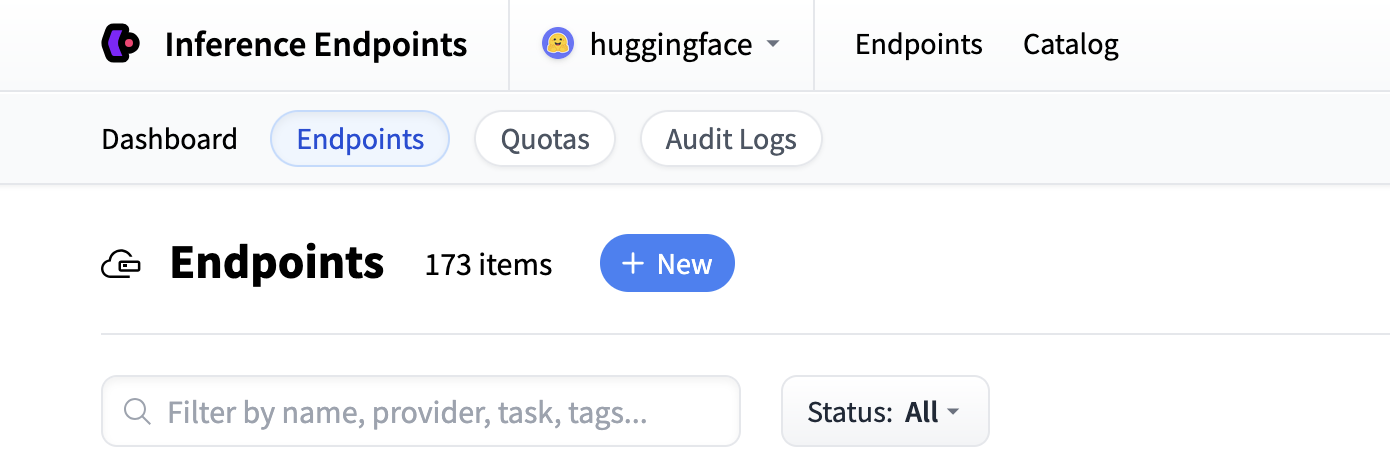
從那裡您將被引導到目錄。模型目錄包含流行的模型,這些模型已調整配置以實現一鍵部署。您可以按名稱、任務、硬體價格等進行篩選。
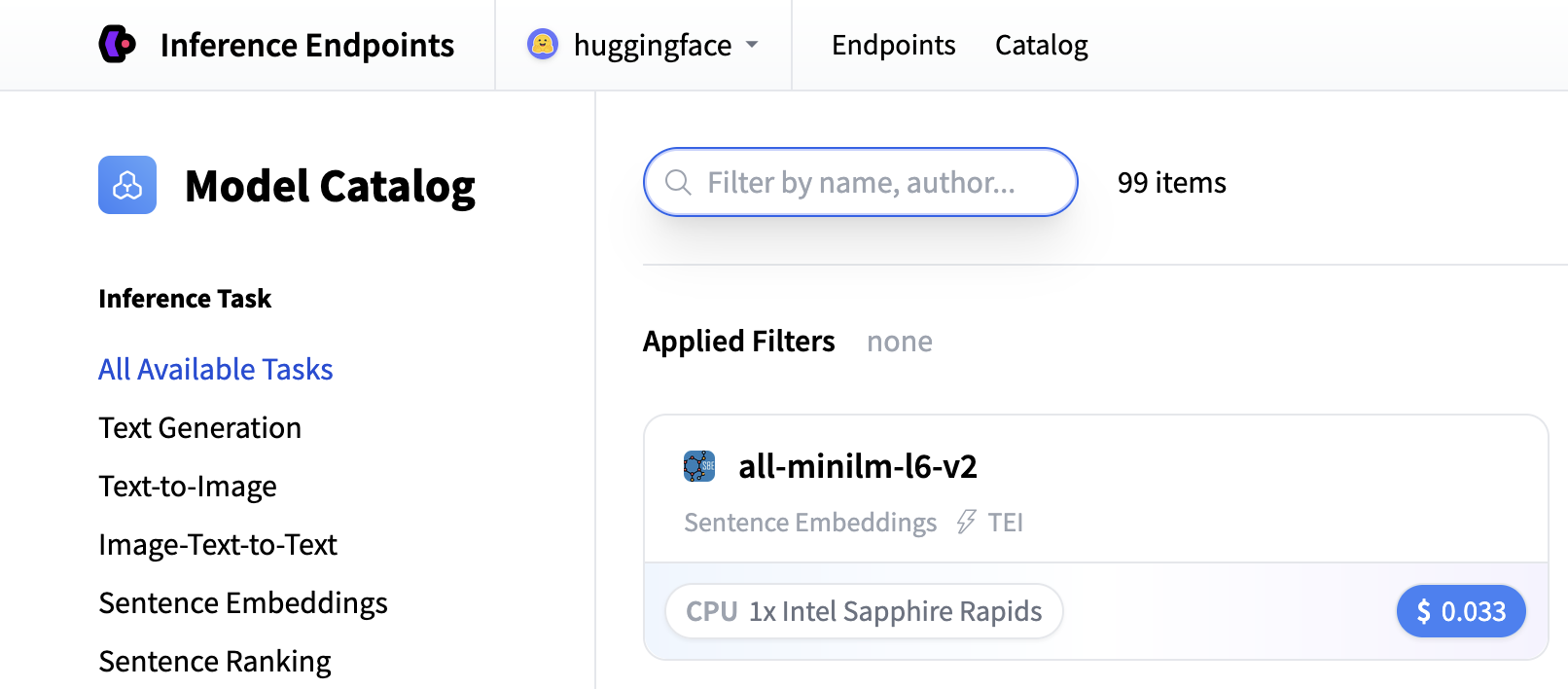
在此示例中,我們部署 meta-llama/Llama-3.2-3B-Instruct 模型。您可以透過在搜尋欄位中搜索 llama-3.2-3b 來找到它,然後單擊卡片進行部署。
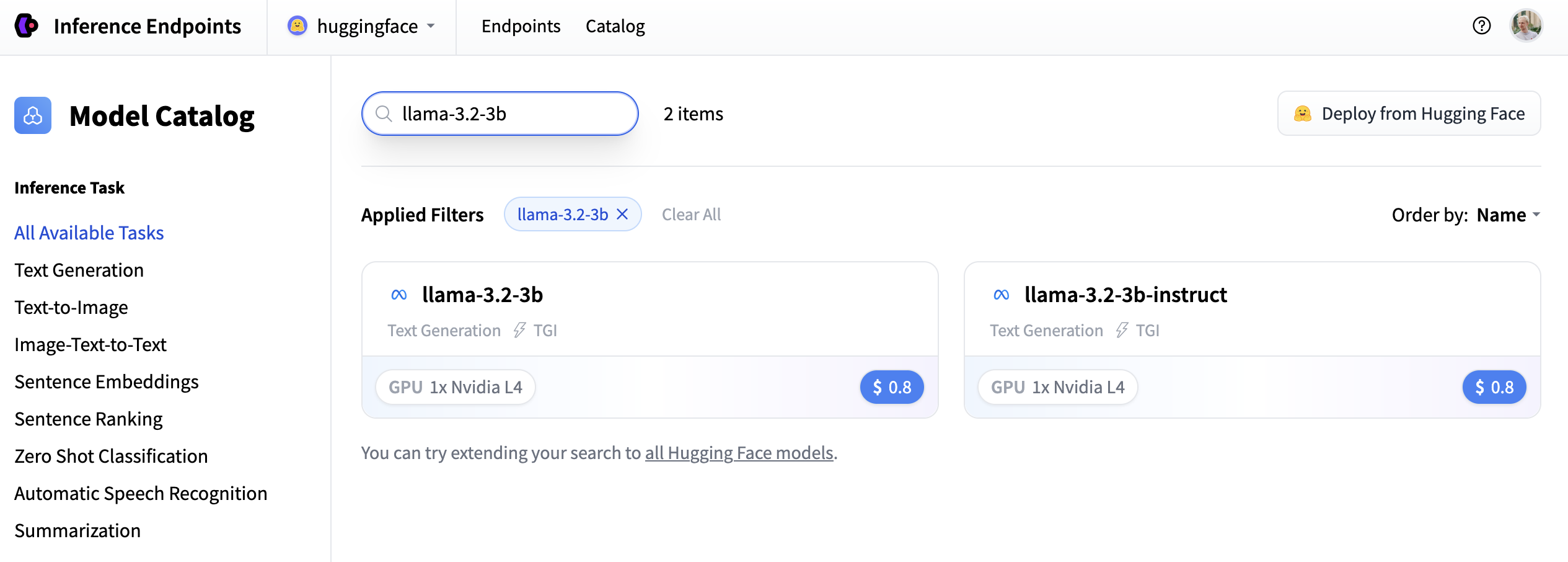
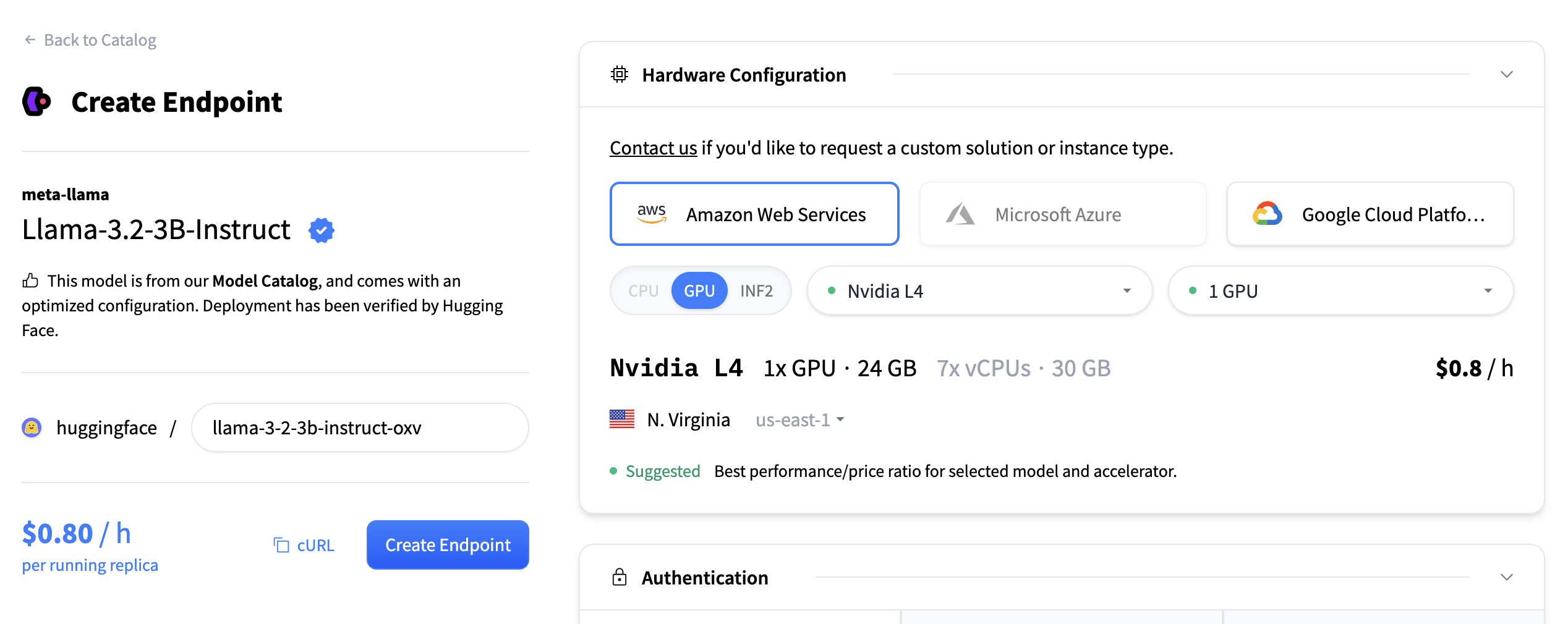
接下來,我們將選擇硬體和部署設定。由於這是一個目錄模型,所有預選選項都是非常好的預設值。因此在這種情況下,我們無需更改任何內容。如果您想深入瞭解不同設定的含義,可以檢視配置指南。
對於此模型,建議選擇 Nvidia L4。它非常適合我們的測試。效能良好且價格合理。另請注意,預設情況下,端點將縮減到零,這意味著它將在不活動 1 小時後變為閒置狀態。
現在您所需要做的就是點選“建立端點”🚀
現在我們的推理端點正在初始化,這通常需要大約 3-5 分鐘。如果您願意,可以允許瀏覽器通知,當端點達到執行狀態時,它會向您傳送提示。
測試您的推理端點
一旦一切都啟動並執行,您將能夠看到
- 端點 URL:用於呼叫端點並向其傳送請求
- 遊樂場:一種快速測試模型是否工作的小型視覺化方式
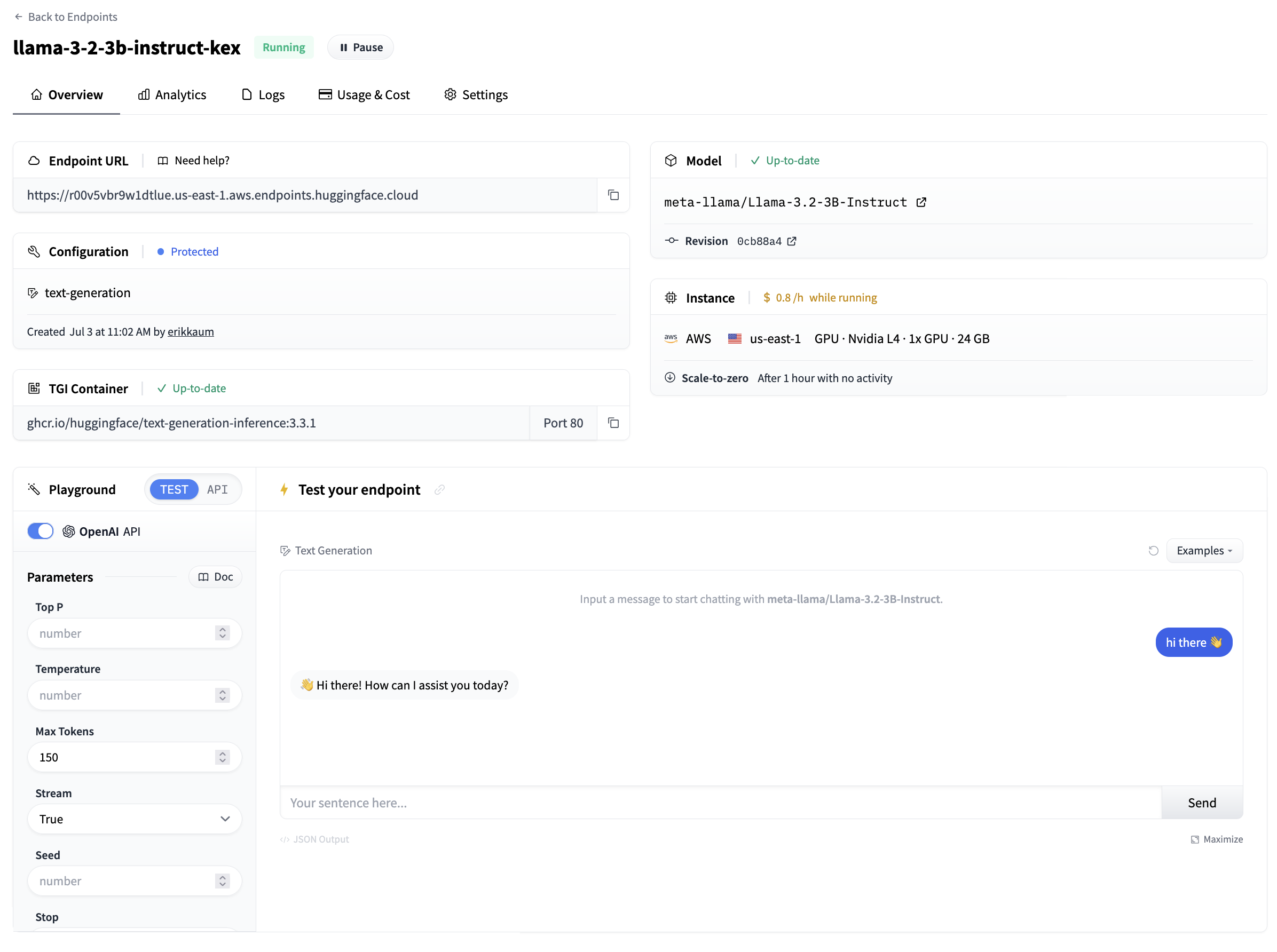
在遊樂場側面,您還可以複製+貼上呼叫模型的程式碼片段。透過單擊“應用令牌”,您將被引導到 Hugging Face,配置訪問令牌以能夠呼叫模型。預設情況下,所有推理端點都建立為私有端點,需要身份驗證,並且所有資料都使用 TLS/SSL 加密傳輸。
恭喜,您剛剛在推理端點中部署了一個生產就緒型 AI 模型 🔥
測試滿意後,您可以暫停推理端點,刪除它。或者,如果您不進行操作,它將在 1 小時後縮減為零。
< > 在 GitHub 上更新