推理端點(專用)文件
構建和部署您自己的聊天應用程式
並獲得增強的文件體驗
開始使用
構建並部署您自己的聊天應用程式
本教程將端到端地指導您如何使用 Hugging Face Inference Endpoints 部署您自己的聊天應用程式。我們將使用 Gradio 建立聊天介面,並使用 OpenAI 客戶端連線到推理端點。
本教程使用 Python,但您的客戶端可以是任何可以發出 HTTP 請求的語言。您在 Inference Endpoints 上部署的模型和引擎使用 **OpenAI Chat Completions 格式**,因此您可以使用任何 OpenAI 客戶端(如 JavaScript、Java 和 Go)連線它們。
建立您的推理端點
首先,我們需要為可以聊天的模型建立一個推理端點。
首先導航到 Inference Endpoints UI,登入後您應該會看到一個用於建立新推理端點的按鈕。單擊“New”按鈕。
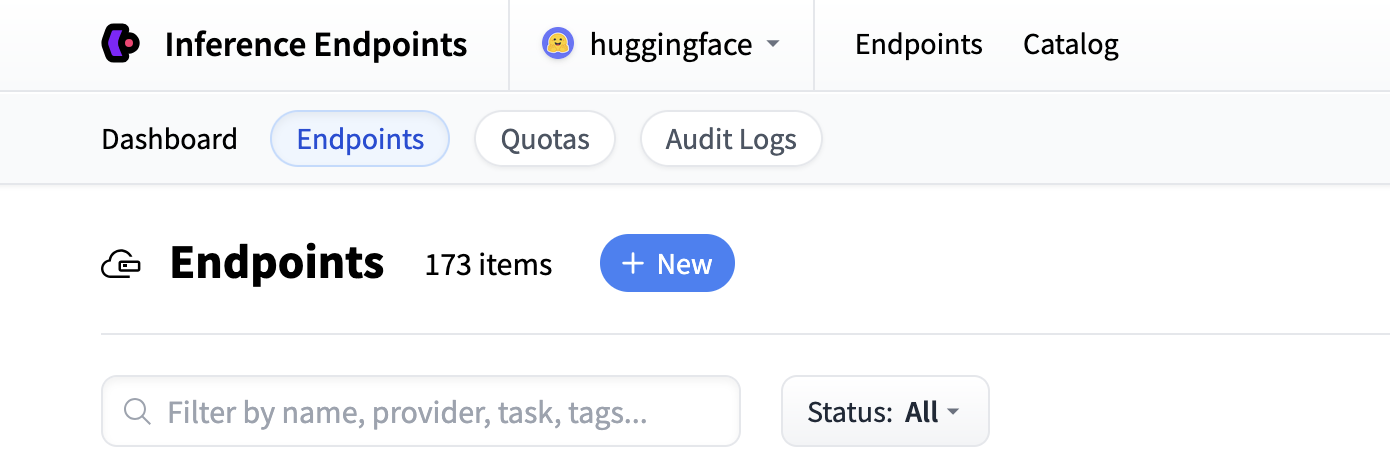
從那裡您將被定向到目錄。模型目錄包含流行的模型,這些模型已調整配置以實現一鍵部署。您可以按名稱、任務、硬體價格等進行篩選。
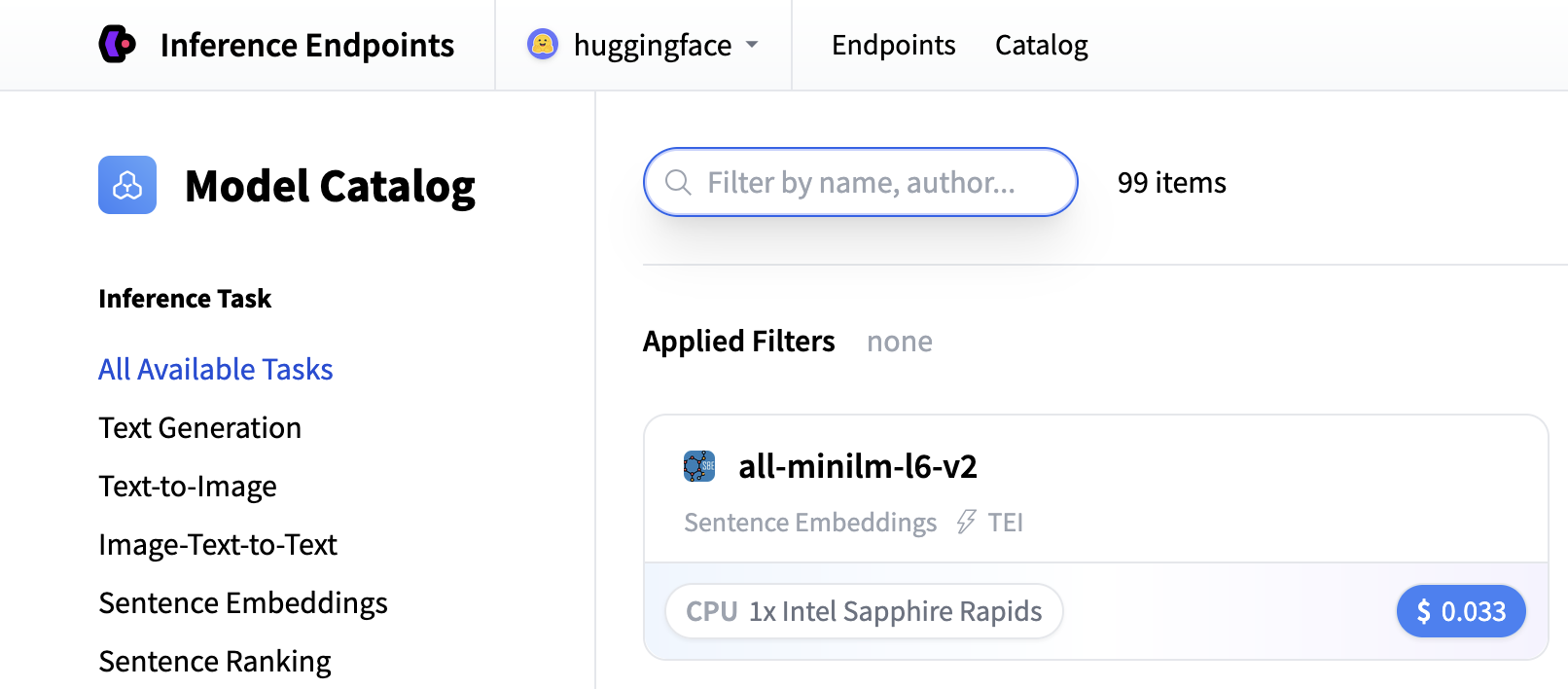
在此示例中,讓我們部署 Qwen/Qwen3-1.7B 模型。您可以透過在搜尋欄位中搜索 qwen3 1.7b 並單擊卡片來找到並部署它。
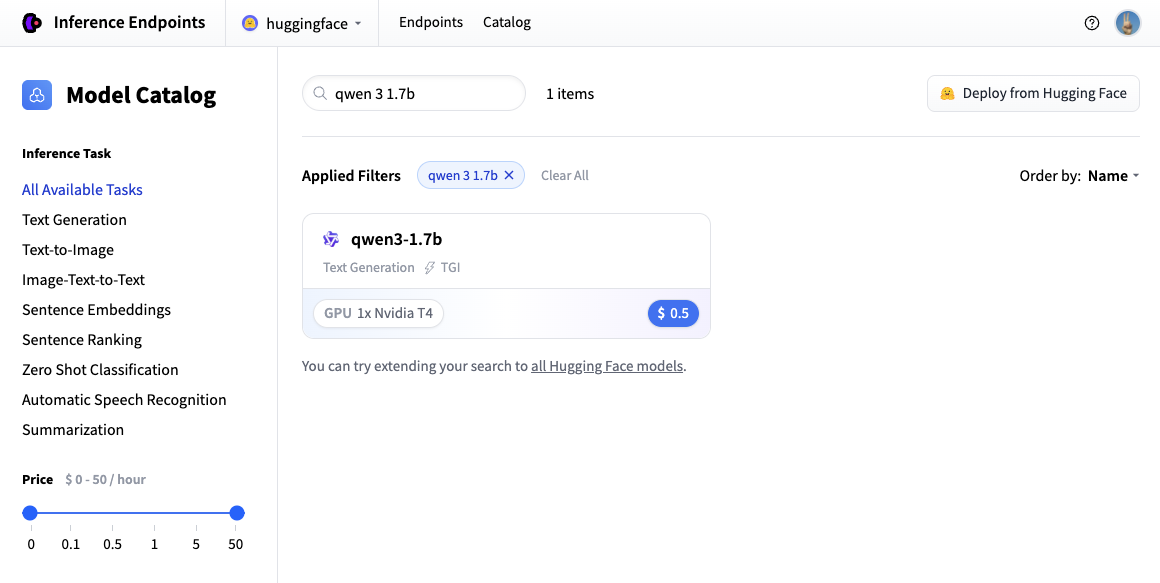
接下來我們將選擇我們想要的硬體和部署設定。由於這是一個目錄模型,所有預選的選項都是非常好的預設值。因此,在這種情況下,我們不需要更改任何內容。如果您想深入瞭解不同設定的含義,可以檢視 配置指南。
對於此模型,Nvidia L4 是推薦的選擇。它將非常適合我們的測試。效能良好但價格合理。另請注意,預設情況下,端點將縮減為零,這意味著它在閒置 1 小時後將進入空閒狀態。
現在您所需要做的就是單擊“建立端點”🚀
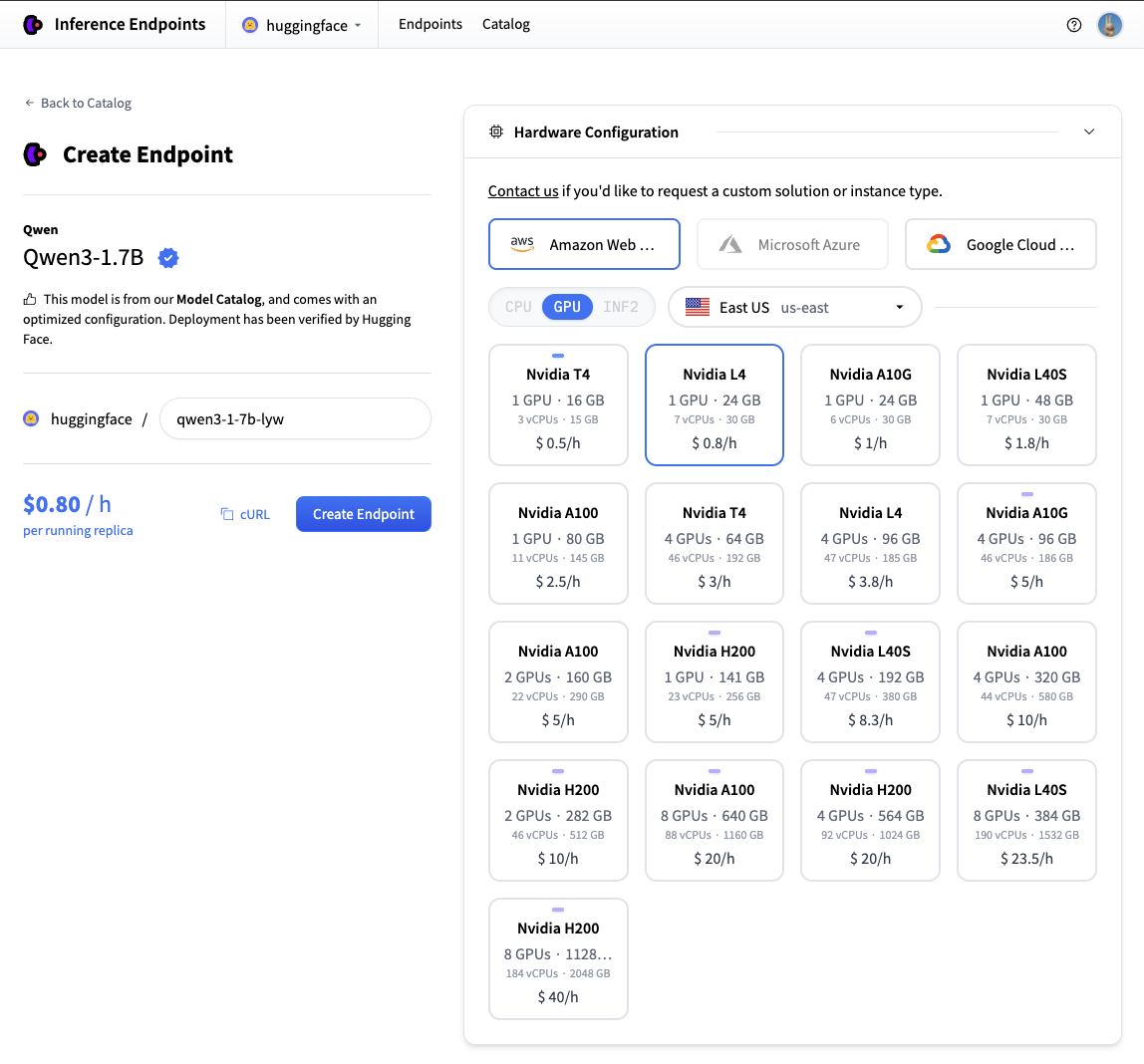
現在我們的推理端點正在初始化,通常需要大約 3-5 分鐘。如果您願意,可以允許瀏覽器通知,當端點達到執行狀態時會給您一個提示。
在瀏覽器中測試您的推理端點
現在我們已經建立了推理端點,我們可以在 Playground 部分進行測試。
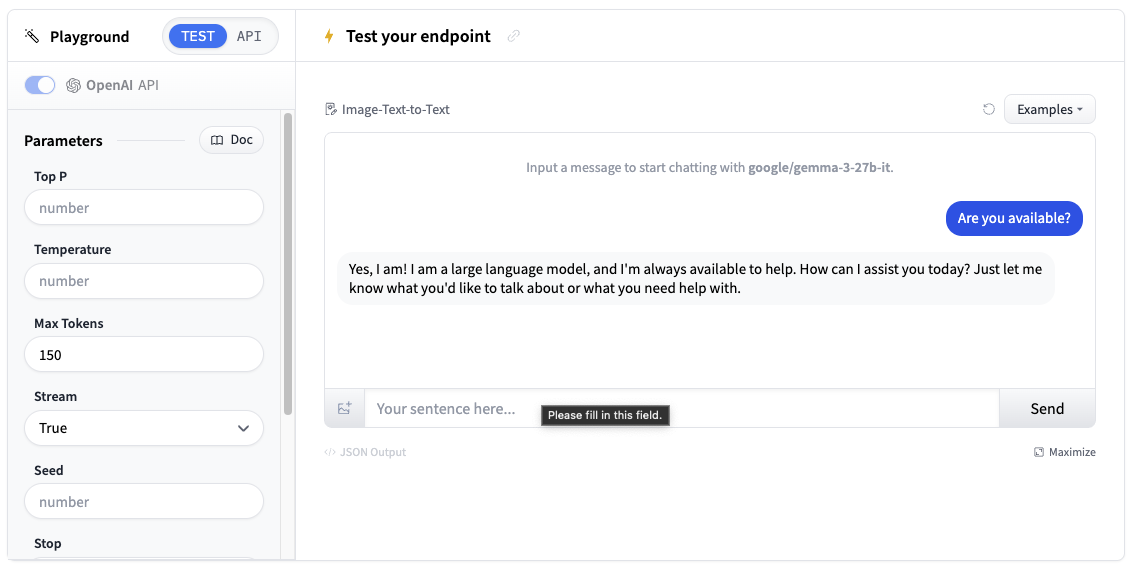
您可以透過聊天介面使用模型,或複製程式碼片段在您自己的應用程式中使用它。
獲取您的推理端點詳細資訊
我們需要獲取推理端點的詳細資訊,這些資訊可以在端點的概覽中找到。我們將需要以下詳細資訊:
- 端點的基本 URL 以及 OpenAI API 的版本(例如,`https://
. . .endpoints.huggingface.cloud/v1/`) - 要使用的端點名稱(例如,`qwen3-1-7b-xll`)
- 用於身份驗證的令牌(例如,`hf_
`)
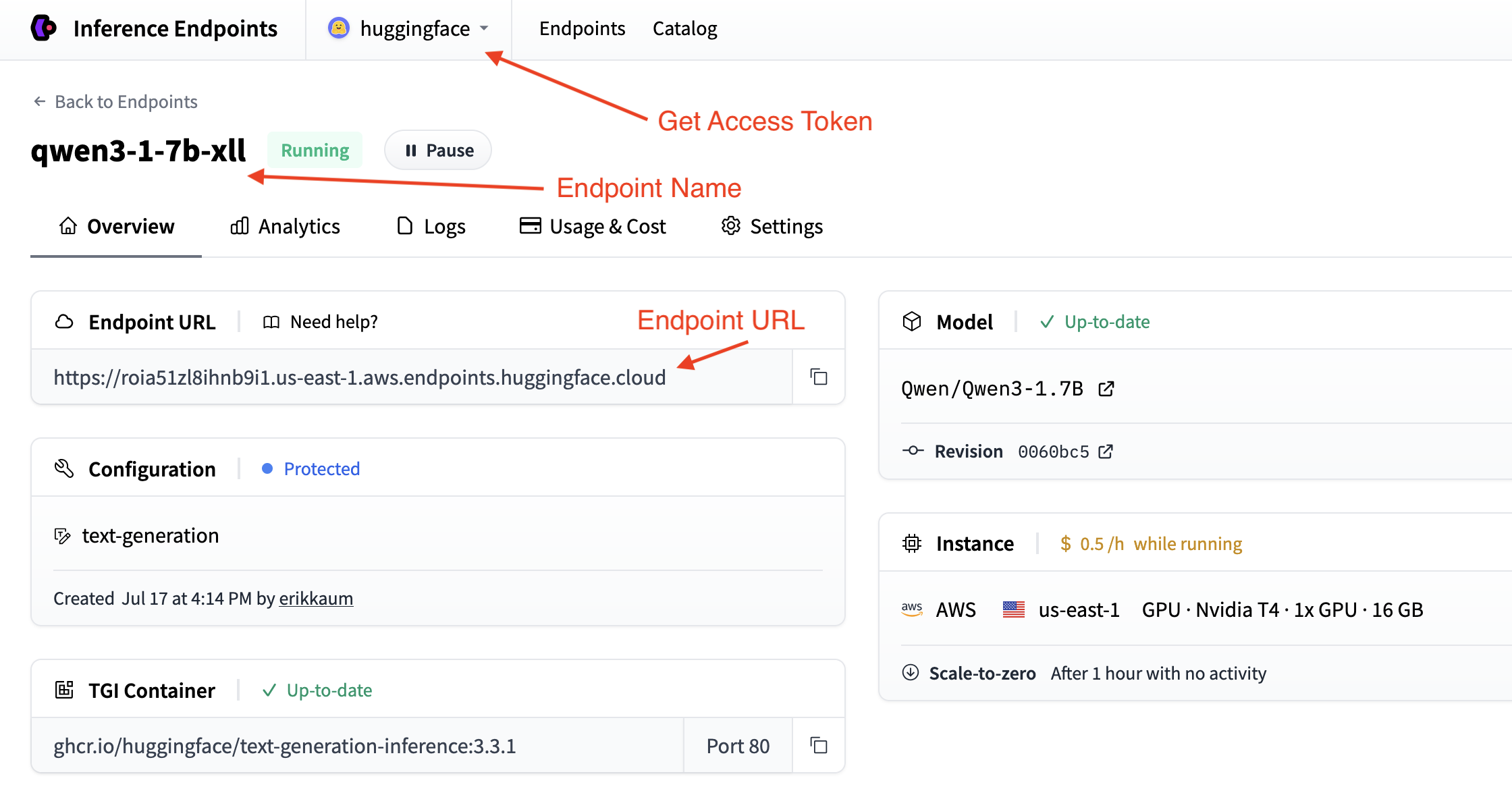
您可以在帳戶設定中找到令牌,透過頂部下拉選單並單擊您的帳戶名稱即可訪問。
幾行程式碼即可部署
使用 Gradio 部署聊天應用程式最簡單的方法是使用便捷的 load_chat 方法。這抽象了所有內容,您可以快速擁有一個可用的聊天應用程式。
import os
import gradio as gr
gr.load_chat(
base_url="<endpoint-url>/v1/", # Replace with your endpoint URL + version
model="endpoint-name", # Replace with your endpoint name
token=os.getenv("HF_TOKEN"), # Replace with your token
).launch()load_chat 方法無法滿足您的生產需求,但它是入門和測試應用程式的好方法。
構建您自己的自定義聊天應用程式
如果您想更好地控制聊天應用程式,您可以使用 Gradio 構建自己的自定義聊天介面。這為您提供了更大的靈活性來定製行為、新增功能和處理錯誤。
選擇您首選的連線推理端點的方法
使用 Hugging Face InferenceClient
首先,安裝所需的依賴項
pip install gradio huggingface-hub
Hugging Face InferenceClient 提供了一個與 OpenAI API 格式相容的簡潔介面
import os
import gradio as gr
from huggingface_hub import InferenceClient
# Initialize the Hugging Face InferenceClient
client = InferenceClient(
base_url="<endpoint-url>/v1/", # Replace with your endpoint URL
token=os.getenv("HF_TOKEN") # Use environment variable for security
)
def chat_with_hf_client(message, history):
# Convert Gradio history to messages format
messages = [{"role": msg["role"], "content": msg["content"]} for msg in history]
# Add the current message
messages.append({"role": "user", "content": message})
# Create chat completion
chat_completion = client.chat.completions.create(
model="endpoint-name", # Use the name of your endpoint (i.e. qwen3-1.7b-instruct-xxxx)
messages=messages,
max_tokens=150,
temperature=0.7,
)
# Return the response
return chat_completion.choices[0].message.content
# Create the Gradio interface
demo = gr.ChatInterface(
fn=chat_with_hf_client,
type="messages",
title="Custom Chat with Inference Endpoints",
examples=["What is deep learning?", "Explain neural networks", "How does AI work?"]
)
if __name__ == "__main__":
demo.launch()新增流式支援
為了獲得更好的使用者體驗,您可以實現流式響應。這將要求我們處理訊息並將其 `yield` 給客戶端。
以下是如何為每個客戶端新增流式傳輸:
Hugging Face InferenceClient 流式傳輸
Hugging Face InferenceClient 支援類似於 OpenAI 客戶端的流式傳輸
import os
import gradio as gr
from huggingface_hub import InferenceClient
client = InferenceClient(
base_url="<endpoint-url>/v1/",
token=os.getenv("HF_TOKEN")
)
def chat_with_hf_streaming(message, history):
# Convert history to messages format
messages = [{"role": msg["role"], "content": msg["content"]} for msg in history]
messages.append({"role": "user", "content": message})
# Create streaming chat completion
chat_completion = client.chat.completions.create(
model="endpoint-name",
messages=messages,
max_tokens=150,
temperature=0.7,
stream=True # Enable streaming
)
response = ""
for chunk in chat_completion:
if chunk.choices[0].delta.content:
response += chunk.choices[0].delta.content
yield response # Yield partial response for streaming
# Create streaming interface
demo = gr.ChatInterface(
fn=chat_with_hf_streaming,
type="messages",
title="Streaming Chat with Inference Endpoints"
)
demo.launch()部署您的聊天應用程式
我們的應用程式將在埠 7860 上執行,看起來像這樣:
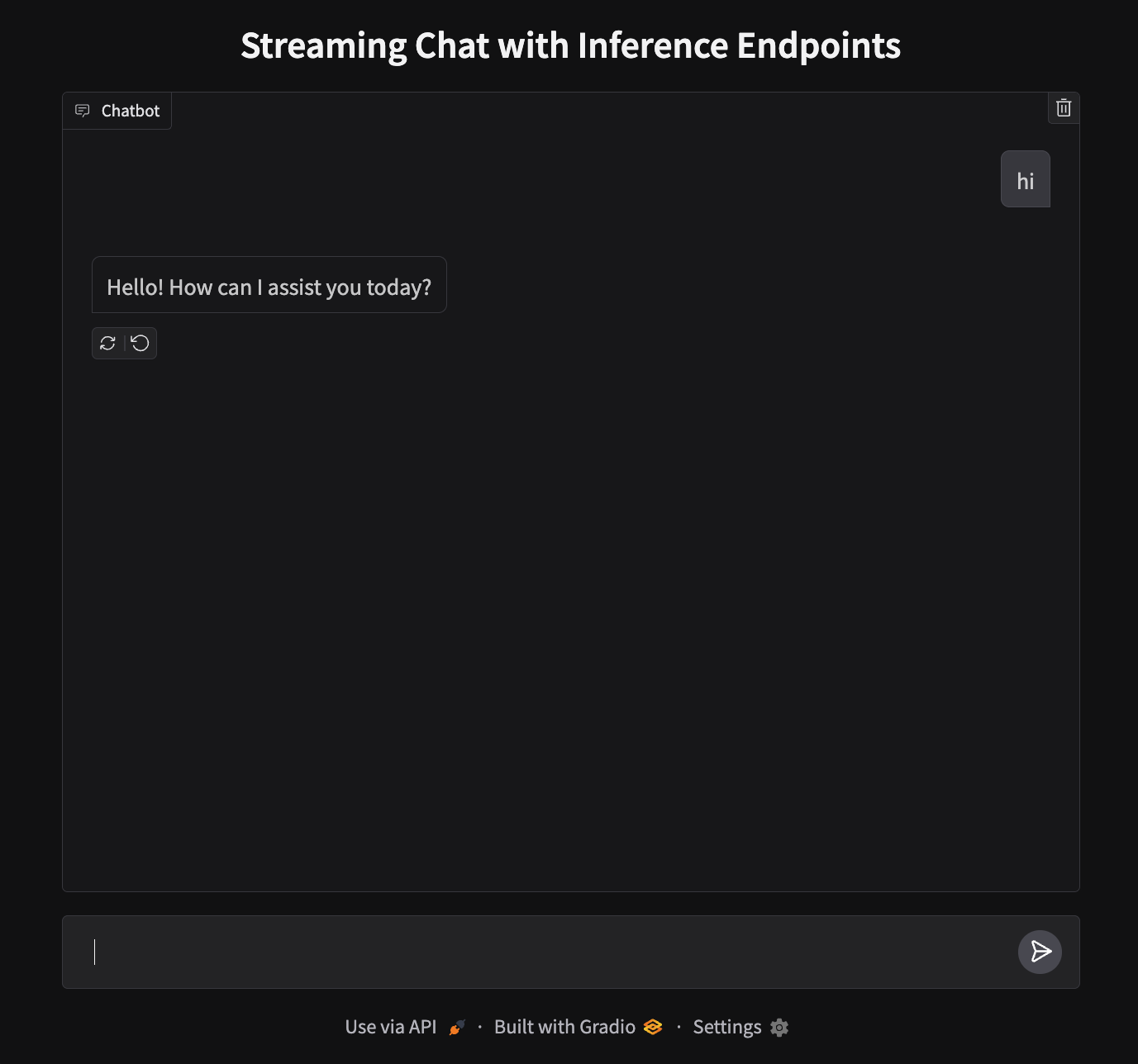
要部署,我們需要建立一個新的空間並上傳我們的檔案。
- 建立一個新空間:前往 huggingface.co/new-space
- 選擇 Gradio SDK 並將其設定為公開
- 上傳您的檔案:上傳
app.py - 新增您的令牌:在空間設定中,將
HF_TOKEN新增為秘密(從您的設定中獲取) - 啟動:您的應用程式將在
https://huggingface.co/spaces/your-username/your-space-name上上線
注意:雖然我們在本地使用 CLI 身份驗證,但 Spaces 要求將令牌作為部署環境的秘密。
下一步
就是這樣!您現在擁有一個在 Hugging Face Spaces 上執行的聊天應用程式,由 Inference Endpoints 提供支援。
何不更進一步,嘗試下一個指南來構建一個文字轉語音應用程式呢?
< > 在 GitHub 上更新