推理端點(專用)文件
自動擴縮
並獲得增強的文件體驗
開始使用
自動擴縮
自動擴縮允許您根據流量和硬體利用率動態調整執行模型的端點副本數量。透過利用自動擴縮,您可以無縫處理不同的工作負載,同時最佳化成本並確保高可用性。
您可以在推理端點卡的“設定”選項卡下找到端點的自動擴縮設定。
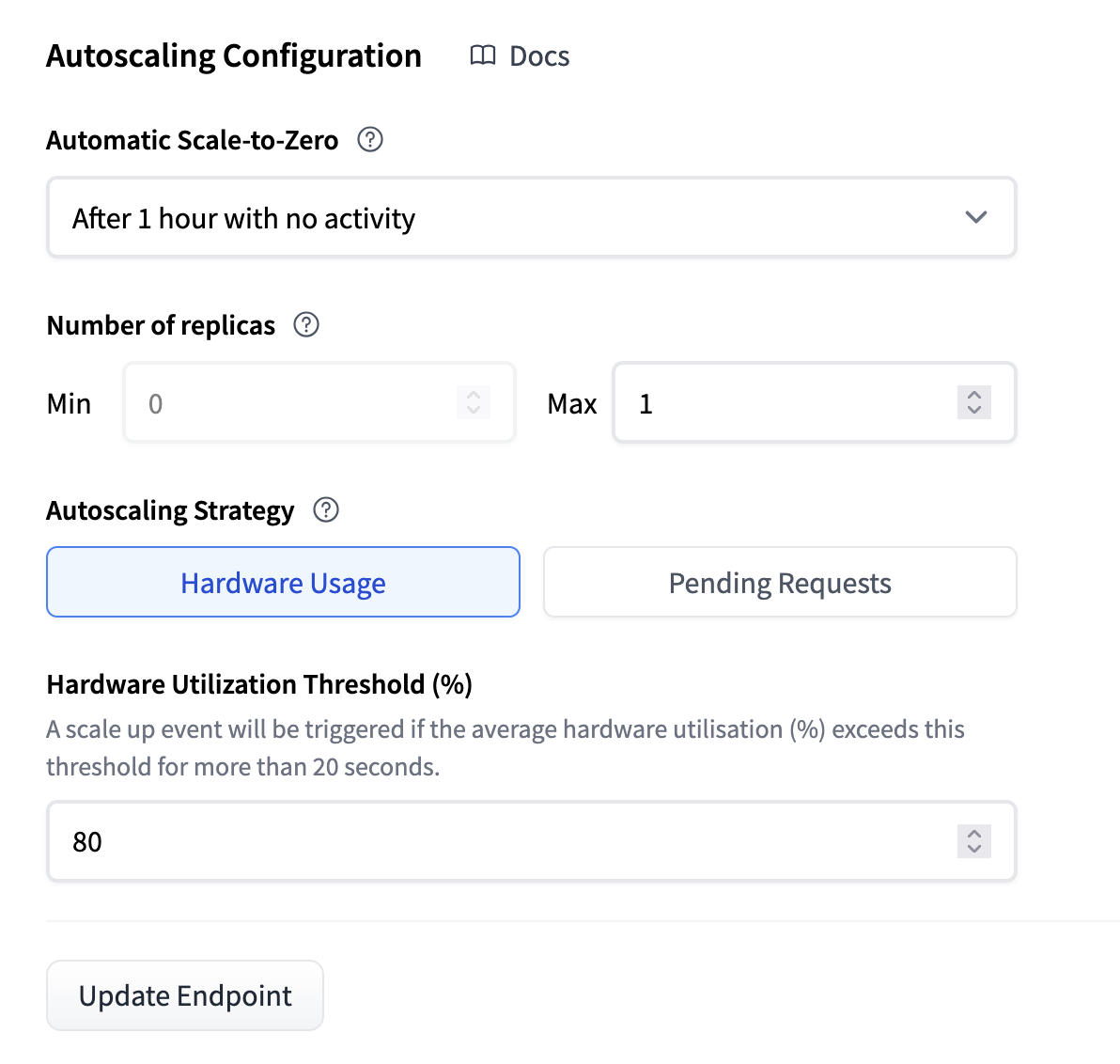
縮減到零
縮減到零意味著您的推理端點在給定持續時間(預設為 1 小時)不活動後將進入空閒狀態。當您想最佳化低成本或工作負載是間歇性時,這通常非常有用。
將副本數量縮減到零有助於透過最大限度地減少非活動期間的資源使用來最佳化成本節約。然而,重要的是要意識到,當端點收到新請求時,縮減到零意味著存在冷啟動期。此外,當新副本初始化時,代理將以狀態碼 503 響應。為了可能避免這種情況,您還可以將“X-Scale-Up-Timeout”標頭新增到您的請求中。這意味著當端點正在擴縮時,代理將保持請求,直到副本準備就緒,或者在指定秒數後超時。例如,“X-Scale-Up-Timeout: 600”將等待 600 秒。
副本數量
透過此設定,您可以更改副本的最大和最小數量。這意味著您可以控制成本的上限和下限。通常,您會將最小值設定為一個值,以便在流量最低時,您仍然能夠以可接受的速度為使用者提供服務。而最大值則設定為一個值,以便您在預算範圍內,即使在流量高峰期也能為使用者提供服務。
自動擴縮策略
為了使自動擴縮系統良好執行,需要有一個訊號來指示何時擴縮和縮減。為此,我們有兩種策略。
基於硬體利用率的擴縮
自動擴縮過程根據硬體利用率指標觸發。擴縮標準因所使用的加速器型別而異。
- CPU:當所有副本的平均 CPU 利用率達到閾值(預設為 80%)時,將新增新副本。
- GPU:當所有副本在 1 分鐘視窗內的平均 GPU 利用率達到閾值(預設為 80%)時,將新增新副本。
重要的是要注意,擴縮過程每分鐘進行一次,縮減過程每 2 分鐘進行一次。此頻率確保了自動擴縮系統的響應能力和穩定性之間的平衡,並在縮減後有 300 秒的穩定時間。
您還可以在“分析”選項卡中跟蹤硬體利用率指標,或在此處閱讀更多相關資訊。
基於待處理請求的擴縮(Beta 功能)
在某些情況下,硬體利用率指標不夠“快速”。原因是硬體指標總是比實際請求略滯後。待處理請求是一個更具前瞻性的指標。
- 待處理請求是指尚未收到 HTTP 狀態的請求,這意味著它們包括正在處理的請求和正在進行中的請求。
- 預設情況下,如果在過去 20 秒內每個副本有超過 1.5 個待處理請求,則會觸發自動擴縮事件並向您的部署新增一個副本。您可以根據您的特定要求在端點設定中調整此閾值。
與硬體指標類似,您可以在“分析”選項卡中跟蹤待處理請求,或在此處閱讀更多相關資訊。
< > 在 GitHub 上更新