推理端點(專用)文件
高階設定(例項型別、自動擴縮、版本控制)
並獲得增強的文件體驗
開始使用
高階設定(例項型別、自動擴縮、版本控制)
我們在建立你的第一個端點中已經看到部署一個端點是多麼快速和簡單,但這並非全部。在建立過程中,選擇雲提供商和區域後,點選 [高階配置] 按鈕,將顯示更多端點的配置選項。
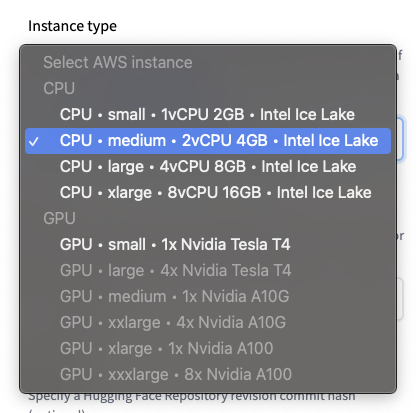
例項型別
🤗 Inference Endpoints 提供了一系列精選的 CPU 和 GPU 例項。
注意:你的 Hugging Face 賬戶對 CPU 和 GPU 例項有容量配額。如需增加配額或請求新的例項型別,請與我們聯絡。
預設值:CPU-medium
副本自動擴縮
設定你希望端點根據使用率自動擴縮的副本範圍(最小值 (>=1) 和最大值)。
預設值:最小 1;最大 2
任務
選擇一個支援的機器學習任務,或設定為自定義。自定義可以/應該在你未使用基於 Transformers 的模型或希望自定義推理流水線時使用,請參閱建立你自己的推理處理器。
預設值:從模型倉庫派生。
框架
對於 Transformers 模型,如果 PyTorch 和 TensorFlow 權重都可用,你可以選擇使用哪種模型權重。這將有助於減小映象製品的大小,並加速端點的啟動/擴縮。
預設值:如果可用,則為 PyTorch。
版本
建立端點時,可以為其源 Hugging Face 模型倉庫指定一個特定的版本提交(revision commit)。這允許你對端點進行版本控制,並確保即使你更新了模型倉庫,也始終使用相同的權重。
預設值:最新的提交。
影像
允許你提供想要部署到端點中的自定義容器映象。這些可以是公共映象,例如 tensorflow/serving:2.7.3,也可以是託管在 Docker Hub、AWS ECR、Azure ACR 或 Google GCR 上的私有映象。
更多關於如何“使用你自己的自定義容器”的內容見下文。
< > 在 GitHub 上更新