Transformers 文件
OPT
並獲得增強的文件體驗
開始使用
OPT
概述
OPT 模型由 Meta AI 在論文 《Open Pre-trained Transformer Language Models》 中提出。OPT 是一系列開源的大型因果語言模型,其效能與 GPT3 相似。
論文摘要如下:
大型語言模型通常需要數十萬個計算日進行訓練,在零樣本和少樣本學習方面展現了卓越的能力。鑑於其巨大的計算成本,沒有雄厚資本很難復現這些模型。對於少數透過 API 提供的模型,也無法訪問完整的模型權重,這使得研究它們變得困難。我們推出了開放預訓練變換器(OPT),這是一套僅包含解碼器的預訓練變換器,引數範圍從 1.25 億到 1750 億,我們希望與感興趣的研究人員完全且負責任地共享。我們證明了 OPT-175B 的效能與 GPT-3 相當,而開發所需的碳足跡僅為其七分之一。我們還發布了我們的日誌,詳細記錄了我們面臨的基礎設施挑戰,以及用於實驗所有已釋出模型的程式碼。
該模型由 Arthur Zucker、Younes Belkada 和 Patrick Von Platen 貢獻。原始程式碼可以在此處找到。
技巧
- OPT 具有與
BartDecoder相同的架構。 - 與 GPT2 不同,OPT 在每個提示的開頭添加了 EOS 標記
</s>。
[!NOTE] 當使用除“eager”之外的所有注意力實現時,
head_mask引數會被忽略。如果你有一個head_mask並且希望它生效,請使用XXXModel.from_pretrained(model_id, attn_implementation="eager")載入模型。
資源
一份官方 Hugging Face 和社群(由 🌎 標誌表示)資源的列表,幫助您開始使用 OPT。如果您有興趣提交資源並希望將其包含在此處,請隨時發起一個 Pull Request,我們會進行稽核。提交的資源最好能展示一些新的內容,而不是重複現有的資源。
- 一份關於使用 PEFT、bitsandbytes 和 Transformers 微調 OPT 的筆記本。🌎
- 一篇關於使用 OPT 進行解碼策略的部落格文章。
- 🤗 Hugging Face 課程的因果語言建模章節。
- OPTForCausalLM 支援此因果語言建模示例指令碼和筆記本。
- TFOPTForCausalLM 支援此因果語言建模示例指令碼和筆記本。
- FlaxOPTForCausalLM 支援此因果語言建模示例指令碼。
- OPTForQuestionAnswering 支援此問答示例指令碼和筆記本。
- 🤗 Hugging Face課程的問答章節。
⚡️ 推理
- 一篇關於🤗 Accelerate 如何藉助 PyTorch 和 OPT 執行超大模型的部落格文章。
結合 OPT 與 Flash Attention 2
首先,請確保安裝最新版本的 Flash Attention 2,以包含滑動視窗注意力功能。
pip install -U flash-attn --no-build-isolation
請確保您擁有與 Flash-Attention 2 相容的硬體。更多資訊請參閱 flash-attn 倉庫的官方文件。同時,請確保以半精度(例如 `torch.float16`)載入您的模型。
要載入並使用 Flash Attention 2 執行模型,請參考以下程式碼片段
>>> import torch
>>> from transformers import OPTForCausalLM, GPT2Tokenizer
>>> device = "cuda" # the device to load the model onto
>>> model = OPTForCausalLM.from_pretrained("facebook/opt-350m", torch_dtype=torch.float16, attn_implementation="flash_attention_2")
>>> tokenizer = GPT2Tokenizer.from_pretrained("facebook/opt-350m")
>>> prompt = ("A chat between a curious human and the Statue of Liberty.\n\nHuman: What is your name?\nStatue: I am the "
"Statue of Liberty.\nHuman: Where do you live?\nStatue: New York City.\nHuman: How long have you lived "
"there?")
>>> model_inputs = tokenizer([prompt], return_tensors="pt").to(device)
>>> model.to(device)
>>> generated_ids = model.generate(**model_inputs, max_new_tokens=30, do_sample=False)
>>> tokenizer.batch_decode(generated_ids)[0]
'</s>A chat between a curious human and the Statue of Liberty.\n\nHuman: What is your name?\nStatue: I am the Statue of Liberty.\nHuman: Where do you live?\nStatue: New York City.\nHuman: How long have you lived there?\nStatue: I have lived here for about a year.\nHuman: What is your favorite place to eat?\nStatue: I love'預期加速效果
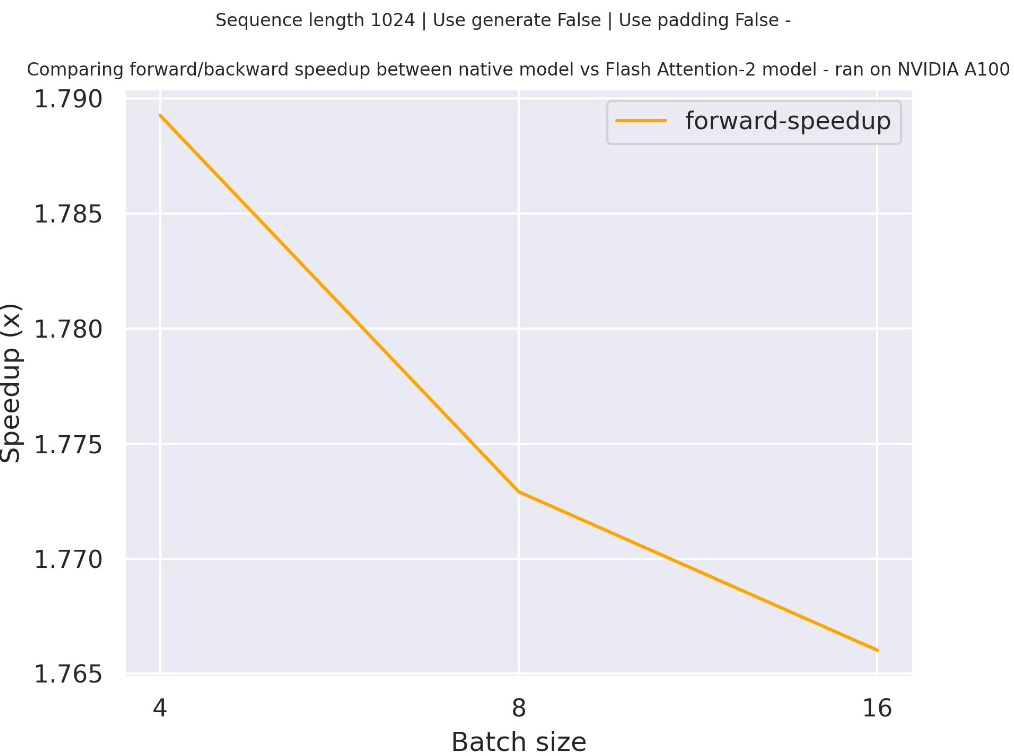
下圖是一個預期加速圖,比較了使用 `facebook/opt-2.7b` 檢查點時,transformers 中的原生實現與 Flash Attention 2 版本的模型在兩種不同序列長度下的純推理時間。
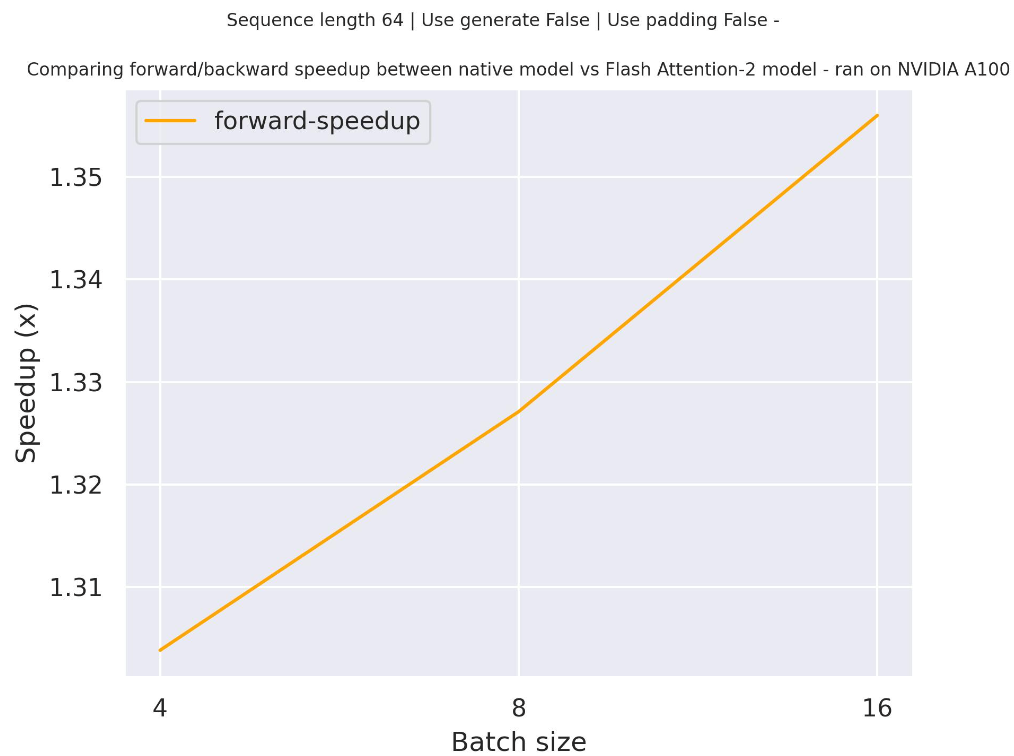
下圖是一個預期加速圖,比較了使用 `facebook/opt-350m` 檢查點時,transformers 中的原生實現與 Flash Attention 2 版本的模型在兩種不同序列長度下的純推理時間。
使用縮放點積注意力 (SDPA)
PyTorch 在 `torch.nn.functional` 中包含一個原生的縮放點積注意力 (SDPA) 運算元。該函式包含多種實現,可根據輸入和使用的硬體進行應用。更多資訊請參閱官方文件或GPU 推理頁面。
當實現可用時,SDPA 預設用於 `torch>=2.1.1`,但你也可以在 `from_pretrained()` 中設定 `attn_implementation="sdpa"` 來明確請求使用 SDPA。
from transformers import OPTForCausalLM
model = OPTForCausalLM.from_pretrained("facebook/opt-350m", torch_dtype=torch.float16, attn_implementation="sdpa")
...為了獲得最佳加速效果,我們建議以半精度(例如 `torch.float16` 或 `torch.bfloat16`)載入模型。
在本地基準測試(L40S-45GB, PyTorch 2.4.0, OS Debian GNU/Linux 11)中使用 `float16` 和 facebook/opt-350m,我們在訓練和推理過程中觀察到以下加速效果。
訓練
| 批處理大小 | 序列長度 | 每批次時間(Eager - 秒) | 每批次時間(SDPA - 秒) | 加速(%) | Eager 峰值記憶體(MB) | sdpa 峰值記憶體 (MB) | 記憶體節省(%) |
|---|---|---|---|---|---|---|---|
| 1 | 128 | 0.047 | 0.037 | 26.360 | 1474.611 | 1474.32 | 0.019 |
| 1 | 256 | 0.046 | 0.037 | 24.335 | 1498.541 | 1499.49 | -0.063 |
| 1 | 512 | 0.046 | 0.037 | 24.959 | 1973.544 | 1551.35 | 27.215 |
| 1 | 1024 | 0.062 | 0.038 | 65.135 | 4867.113 | 1698.35 | 186.578 |
| 1 | 2048 | 0.230 | 0.039 | 483.933 | 15662.224 | 2715.75 | 476.718 |
| 2 | 128 | 0.045 | 0.037 | 20.455 | 1498.164 | 1499.49 | -0.089 |
| 2 | 256 | 0.046 | 0.037 | 24.027 | 1569.367 | 1551.35 | 1.161 |
| 2 | 512 | 0.045 | 0.037 | 20.965 | 3257.074 | 1698.35 | 91.778 |
| 2 | 1024 | 0.122 | 0.038 | 225.958 | 9054.405 | 2715.75 | 233.403 |
| 2 | 2048 | 0.464 | 0.067 | 593.646 | 30572.058 | 4750.55 | 543.548 |
| 4 | 128 | 0.045 | 0.037 | 21.918 | 1549.448 | 1551.35 | -0.123 |
| 4 | 256 | 0.044 | 0.038 | 18.084 | 2451.768 | 1698.35 | 44.361 |
| 4 | 512 | 0.069 | 0.037 | 84.421 | 5833.180 | 2715.75 | 114.791 |
| 4 | 1024 | 0.262 | 0.062 | 319.475 | 17427.842 | 4750.55 | 266.860 |
| 4 | 2048 | 記憶體不足 | 0.062 | Eager 記憶體不足 | 記憶體不足 | 4750.55 | Eager 記憶體不足 |
| 8 | 128 | 0.044 | 0.037 | 18.436 | 2049.115 | 1697.78 | 20.694 |
| 8 | 256 | 0.048 | 0.036 | 32.887 | 4222.567 | 2715.75 | 55.484 |
| 8 | 512 | 0.153 | 0.06 | 154.862 | 10985.391 | 4750.55 | 131.245 |
| 8 | 1024 | 0.526 | 0.122 | 330.697 | 34175.763 | 8821.18 | 287.428 |
| 8 | 2048 | 記憶體不足 | 0.122 | Eager 記憶體不足 | 記憶體不足 | 8821.18 | Eager 記憶體不足 |
推理
| 批處理大小 | 序列長度 | Eager 每詞元延遲 (ms) | SDPA 每詞元延遲 (ms) | 加速(%) | Eager 記憶體 (MB) | BT 記憶體 (MB) | 記憶體節省 (%) |
|---|---|---|---|---|---|---|---|
| 1 | 128 | 11.634 | 8.647 | 34.546 | 717.676 | 717.674 | 0 |
| 1 | 256 | 11.593 | 8.86 | 30.851 | 742.852 | 742.845 | 0.001 |
| 1 | 512 | 11.515 | 8.816 | 30.614 | 798.232 | 799.593 | -0.17 |
| 1 | 1024 | 11.556 | 8.915 | 29.628 | 917.265 | 895.538 | 2.426 |
| 2 | 128 | 12.724 | 11.002 | 15.659 | 762.434 | 762.431 | 0 |
| 2 | 256 | 12.704 | 11.063 | 14.83 | 816.809 | 816.733 | 0.009 |
| 2 | 512 | 12.757 | 10.947 | 16.535 | 917.383 | 918.339 | -0.104 |
| 2 | 1024 | 13.018 | 11.018 | 18.147 | 1162.65 | 1114.81 | 4.291 |
| 4 | 128 | 12.739 | 10.959 | 16.243 | 856.335 | 856.483 | -0.017 |
| 4 | 256 | 12.718 | 10.837 | 17.355 | 957.298 | 957.674 | -0.039 |
| 4 | 512 | 12.813 | 10.822 | 18.393 | 1158.44 | 1158.45 | -0.001 |
| 4 | 1024 | 13.416 | 11.06 | 21.301 | 1653.42 | 1557.19 | 6.18 |
| 8 | 128 | 12.763 | 10.891 | 17.193 | 1036.13 | 1036.51 | -0.036 |
| 8 | 256 | 12.89 | 11.104 | 16.085 | 1236.98 | 1236.87 | 0.01 |
| 8 | 512 | 13.327 | 10.939 | 21.836 | 1642.29 | 1641.78 | 0.031 |
| 8 | 1024 | 15.181 | 11.175 | 35.848 | 2634.98 | 2443.35 | 7.843 |
OPTConfig
class transformers.OPTConfig
< 來源 >( vocab_size = 50272 hidden_size = 768 num_hidden_layers = 12 ffn_dim = 3072 max_position_embeddings = 2048 do_layer_norm_before = True _remove_final_layer_norm = False word_embed_proj_dim = None dropout = 0.1 attention_dropout = 0.0 num_attention_heads = 12 activation_function = 'relu' layerdrop = 0.0 init_std = 0.02 use_cache = True pad_token_id = 1 bos_token_id = 2 eos_token_id = 2 enable_bias = True layer_norm_elementwise_affine = True **kwargs )
引數
- vocab_size (
int, 可選, 預設為 50272) — OPT 模型的詞彙表大小。定義了在呼叫 OPTModel 時傳入的 `inputs_ids` 可以表示的不同標記的數量。 - hidden_size (
int, 可選, 預設為 768) — 層和池化層的維度。 - num_hidden_layers (
int, 可選, 預設為 12) — 解碼器層的數量。 - ffn_dim (
int, 可選, 預設為 3072) — 解碼器中“中間”(通常稱為前饋)層的維度。 - num_attention_heads (
int, 可選, 預設為 12) — Transformer 解碼器中每個注意力層的注意力頭數量。 - activation_function (
str或function, 可選, 預設為"relu") — 編碼器和池化層中的非線性啟用函式(函式或字串)。如果為字串,支援"gelu"、"relu"、"silu"和"gelu_new"。 - max_position_embeddings (
int, 可選, 預設為 2048) — 該模型可能使用的最大序列長度。通常將其設定為一個較大的值以備不時之需(例如 512、1024 或 2048)。 - do_layer_norm_before (
bool, 可選, 預設為True) — 是否在注意力塊之前執行層歸一化。 - word_embed_proj_dim (
int, 可選) — `word_embed_proj_dim` 可用於下投影詞嵌入,例如 `opt-350m`。預設為 `hidden_size`。 - dropout (
float, 可選, 預設為 0.1) — 嵌入、編碼器和池化層中所有全連線層的 dropout 機率。 - attention_dropout (
float, 可選, 預設為 0.0) — 注意力機率的 dropout 比率。 - layerdrop (
float, 可選, 預設為 0.0) — LayerDrop 機率。更多細節請參閱 [LayerDrop 論文](https://huggingface.co/papers/1909.11556)。 - init_std (
float, 可選, 預設為 0.02) — 用於初始化所有權重矩陣的 truncated_normal_initializer 的標準差。 - use_cache (
bool, 可選, 預設為True) — 模型是否應返回最後一個鍵/值注意力(並非所有模型都使用)。 - enable_bias (
bool, 可選, 預設為True) — 注意力塊中的線性層是否應使用偏置項。 - layer_norm_elementwise_affine (
bool, 可選, 預設為True) — 層歸一化是否應具有可學習的引數。
這是一個用於儲存 OPTModel 配置的配置類。它根據指定的引數例項化一個 OPT 模型,定義模型架構。使用預設值例項化配置將產生與 OPT facebook/opt-350m 架構類似的配置。
配置物件繼承自 PretrainedConfig,可用於控制模型輸出。請閱讀 PretrainedConfig 的文件以獲取更多資訊。
示例
>>> from transformers import OPTConfig, OPTModel
>>> # Initializing a OPT facebook/opt-large style configuration
>>> configuration = OPTConfig()
>>> # Initializing a model (with random weights) from the facebook/opt-large style configuration
>>> model = OPTModel(configuration)
>>> # Accessing the model configuration
>>> configuration = model.configOPTModel
class transformers.OPTModel
< source >( config: OPTConfig )
引數
- config (OPTConfig) — 包含模型所有引數的模型配置類。使用配置檔案進行初始化不會載入與模型相關的權重,只會載入配置。請檢視 from_pretrained() 方法來載入模型權重。
無任何特定頭部的原始 Opt 模型,輸出原始的隱藏狀態。
該模型繼承自 PreTrainedModel。請檢視超類文件,瞭解庫為所有模型實現的通用方法(例如下載或儲存、調整輸入嵌入大小、修剪頭部等)。
該模型也是 PyTorch torch.nn.Module 的子類。可以像常規 PyTorch 模組一樣使用它,並參考 PyTorch 文件瞭解所有與通用用法和行為相關的事項。
forward
< source >( input_ids: typing.Optional[torch.LongTensor] = None attention_mask: typing.Optional[torch.Tensor] = None head_mask: typing.Optional[torch.Tensor] = None past_key_values: typing.Union[transformers.cache_utils.Cache, list[torch.FloatTensor], NoneType] = None inputs_embeds: typing.Optional[torch.FloatTensor] = None use_cache: typing.Optional[bool] = None output_attentions: typing.Optional[bool] = None output_hidden_states: typing.Optional[bool] = None return_dict: typing.Optional[bool] = None position_ids: typing.Optional[torch.LongTensor] = None cache_position: typing.Optional[torch.Tensor] = None **kwargs: typing_extensions.Unpack[transformers.modeling_flash_attention_utils.FlashAttentionKwargs] ) → transformers.modeling_outputs.BaseModelOutputWithPast 或 tuple(torch.FloatTensor)
引數
- input_ids (
torch.LongTensor,形狀為(batch_size, sequence_length),可選) — 詞彙表中輸入序列標記的索引。預設情況下,填充將被忽略。可以使用 AutoTokenizer 獲取索引。有關詳細資訊,請參閱 PreTrainedTokenizer.encode() 和 PreTrainedTokenizer.call()。
- attention_mask (
torch.Tensor,形狀為(batch_size, sequence_length),可選) — 用於避免對填充標記索引執行注意力機制的掩碼。掩碼值選自[0, 1]:- 1 表示標記未被掩碼,
- 0 表示標記已被掩碼。
- head_mask (
torch.Tensor,形狀為(num_heads,)或(num_layers, num_heads),可選) — 用於使自注意力模組的選定頭部無效的掩碼。掩碼值選自[0, 1]:- 1 表示頭部未被掩碼,
- 0 表示頭部已被掩碼。
- past_key_values (
Union[~cache_utils.Cache, list[torch.FloatTensor], NoneType]) — 預先計算的隱藏狀態(自注意力塊和交叉注意力塊中的鍵和值),可用於加速序列解碼。這通常包括模型在先前解碼階段返回的past_key_values,當use_cache=True或config.use_cache=True時。允許兩種格式:
- 一個 Cache 例項,請參閱我們的 kv 快取指南;
- 長度為
config.n_layers的tuple(torch.FloatTensor)元組,每個元組包含 2 個形狀為(batch_size, num_heads, sequence_length, embed_size_per_head)的張量。這也稱為舊版快取格式。
模型將輸出與輸入相同的快取格式。如果未傳遞
past_key_values,將返回舊版快取格式。如果使用
past_key_values,使用者可以選擇只輸入最後一個input_ids(那些沒有為其提供過去鍵值狀態的 ID),形狀為(batch_size, 1),而不是所有形狀為(batch_size, sequence_length)的input_ids。 - inputs_embeds (
torch.FloatTensor,形狀為(batch_size, sequence_length, hidden_size),可選) — 可選地,你可以不傳遞input_ids,而是直接傳遞嵌入表示。如果你想比模型內部的嵌入查詢矩陣更好地控制如何將input_ids索引轉換為相關向量,這會很有用。 - use_cache (
bool,可選) — 如果設定為True,則返回past_key_values鍵值狀態,可用於加速解碼(請參閱past_key_values)。 - output_attentions (
bool,可選) — 是否返回所有注意力層的注意力張量。有關更多詳細資訊,請參閱返回張量下的attentions。 - output_hidden_states (
bool,可選) — 是否返回所有層的隱藏狀態。有關更多詳細資訊,請參閱返回張量下的hidden_states。 - return_dict (
bool,可選) — 是否返回一個 ModelOutput 而不是一個普通的元組。 - position_ids (
torch.LongTensor,形狀為(batch_size, sequence_length),可選) — 每個輸入序列標記在位置嵌入中的位置索引。選自[0, config.n_positions - 1]範圍。 - cache_position (
torch.Tensor,形狀為(sequence_length),可選) — 描述輸入序列標記在序列中位置的索引。與position_ids相反,此張量不受填充影響。它用於在正確的位置更新快取並推斷完整的序列長度。
返回
transformers.modeling_outputs.BaseModelOutputWithPast 或 tuple(torch.FloatTensor)
一個 transformers.modeling_outputs.BaseModelOutputWithPast 或一個 `torch.FloatTensor` 元組(如果傳遞了 `return_dict=False` 或 `config.return_dict=False`),根據配置(OPTConfig)和輸入包含各種元素。
-
last_hidden_state (
torch.FloatTensor, 形狀為(batch_size, sequence_length, hidden_size)) — 模型最後一層輸出的隱藏狀態序列。如果使用了
past_key_values,則只輸出形狀為(batch_size, 1, hidden_size)的序列的最後一個隱藏狀態。 -
past_key_values (
Cache,可選,當傳遞use_cache=True或config.use_cache=True時返回) — 這是一個 Cache 例項。更多詳情,請參閱我們的 kv 快取指南。包含預計算的隱藏狀態(自注意力塊中的鍵和值,如果 `config.is_encoder_decoder=True`,則還包括交叉注意力塊中的鍵和值),可用於(參見 `past_key_values` 輸入)加速序列解碼。
-
hidden_states (
tuple(torch.FloatTensor),可選,當傳遞output_hidden_states=True或config.output_hidden_states=True時返回) —torch.FloatTensor元組(一個用於嵌入層的輸出,如果模型有嵌入層,+ 一個用於每層輸出),形狀為(batch_size, sequence_length, hidden_size)。模型在每個層輸出的隱藏狀態以及可選的初始嵌入輸出。
-
attentions (
tuple(torch.FloatTensor),可選,當傳遞output_attentions=True或config.output_attentions=True時返回) —torch.FloatTensor元組(每層一個),形狀為(batch_size, num_heads, sequence_length, sequence_length)。注意力 softmax 後的注意力權重,用於計算自注意力頭中的加權平均值。
OPTModel 的 forward 方法,覆蓋了 `__call__` 特殊方法。
雖然前向傳播的流程需要在此函式內定義,但之後應呼叫 `Module` 例項而不是此函式,因為前者會處理執行前處理和後處理步驟,而後者會靜默地忽略它們。
OPTForCausalLM
forward
< source >( input_ids: typing.Optional[torch.LongTensor] = None attention_mask: typing.Optional[torch.Tensor] = None head_mask: typing.Optional[torch.Tensor] = None past_key_values: typing.Union[transformers.cache_utils.Cache, list[torch.FloatTensor], NoneType] = None inputs_embeds: typing.Optional[torch.FloatTensor] = None labels: typing.Optional[torch.LongTensor] = None use_cache: typing.Optional[bool] = None output_attentions: typing.Optional[bool] = None output_hidden_states: typing.Optional[bool] = None return_dict: typing.Optional[bool] = None position_ids: typing.Optional[torch.LongTensor] = None cache_position: typing.Optional[torch.Tensor] = None **kwargs: typing_extensions.Unpack[transformers.models.opt.modeling_opt.KwargsForCausalLM] ) → transformers.modeling_outputs.CausalLMOutputWithPast 或 tuple(torch.FloatTensor)
引數
- input_ids (
torch.LongTensor,形狀為(batch_size, sequence_length),可選) — 詞彙表中輸入序列標記的索引。預設情況下,填充將被忽略。可以使用 AutoTokenizer 獲取索引。有關詳細資訊,請參閱 PreTrainedTokenizer.encode() 和 PreTrainedTokenizer.call()。
- attention_mask (
torch.Tensor,形狀為(batch_size, sequence_length),可選) — 用於避免對填充標記索引執行注意力機制的掩碼。掩碼值選自[0, 1]:- 1 表示標記未被掩碼,
- 0 表示標記已被掩碼。
- head_mask (
torch.Tensor,形狀為(num_heads,)或(num_layers, num_heads),可選) — 用於使自注意力模組的選定頭部無效的掩碼。掩碼值選自[0, 1]:- 1 表示頭部未被掩碼,
- 0 表示頭部已被掩碼。
- past_key_values (
Union[~cache_utils.Cache, list[torch.FloatTensor], NoneType]) — 預先計算的隱藏狀態(自注意力塊和交叉注意力塊中的鍵和值),可用於加速序列解碼。這通常包括模型在先前解碼階段返回的past_key_values,當use_cache=True或config.use_cache=True時。允許兩種格式:
- 一個 Cache 例項,請參閱我們的 kv 快取指南;
- 長度為
config.n_layers的tuple(torch.FloatTensor)元組,每個元組包含 2 個形狀為(batch_size, num_heads, sequence_length, embed_size_per_head)的張量。這也稱為舊版快取格式。
模型將輸出與輸入相同的快取格式。如果未傳遞
past_key_values,將返回舊版快取格式。如果使用
past_key_values,使用者可以選擇只輸入最後一個input_ids(那些沒有為其提供過去鍵值狀態的 ID),形狀為(batch_size, 1),而不是所有形狀為(batch_size, sequence_length)的input_ids。 - inputs_embeds (
torch.FloatTensor,形狀為(batch_size, sequence_length, hidden_size),可選) — 可選地,你可以不傳遞input_ids,而是直接傳遞嵌入表示。如果你想比模型內部的嵌入查詢矩陣更好地控制如何將input_ids索引轉換為相關向量,這會很有用。 - labels (
torch.LongTensor,形狀為(batch_size, sequence_length),可選) — 用於計算掩碼語言建模損失的標籤。索引應在[0, ..., config.vocab_size]或 -100 之間(請參閱input_ids文件字串)。索引設定為-100的標記將被忽略(掩碼),損失僅對標籤在[0, ..., config.vocab_size]之間的標記計算。 - use_cache (
bool,可選) — 如果設定為True,則返回past_key_values鍵值狀態,可用於加速解碼(請參閱past_key_values)。 - output_attentions (
bool,可選) — 是否返回所有注意力層的注意力張量。有關更多詳細資訊,請參閱返回張量下的attentions。 - output_hidden_states (
bool,可選) — 是否返回所有層的隱藏狀態。有關更多詳細資訊,請參閱返回張量下的hidden_states。 - return_dict (
bool,可選) — 是否返回一個 ModelOutput 而不是一個普通的元組。 - position_ids (
torch.LongTensor,形狀為(batch_size, sequence_length),可選) — 每個輸入序列標記在位置嵌入中的位置索引。選自[0, config.n_positions - 1]範圍。 - cache_position (
torch.Tensor,形狀為(sequence_length),可選) — 描述輸入序列標記在序列中位置的索引。與position_ids相反,此張量不受填充影響。它用於在正確的位置更新快取並推斷完整的序列長度。
返回
transformers.modeling_outputs.CausalLMOutputWithPast 或 tuple(torch.FloatTensor)
一個 transformers.modeling_outputs.CausalLMOutputWithPast 或一個 `torch.FloatTensor` 元組(如果傳遞了 `return_dict=False` 或 `config.return_dict=False`),根據配置(OPTConfig)和輸入包含各種元素。
-
loss (
torch.FloatTensor形狀為(1,),可選,當提供labels時返回) — 語言建模損失(用於下一個 token 預測)。 -
logits (形狀為
(batch_size, sequence_length, config.vocab_size)的torch.FloatTensor) — 語言建模頭部的預測分數(SoftMax 之前的每個詞彙標記的分數)。 -
past_key_values (
Cache,可選,當傳遞use_cache=True或config.use_cache=True時返回) — 這是一個 Cache 例項。更多詳情,請參閱我們的 kv 快取指南。包含預計算的隱藏狀態(自注意力塊中的鍵和值),可用於(參見
past_key_values輸入)加速順序解碼。 -
hidden_states (
tuple(torch.FloatTensor),可選,當傳遞output_hidden_states=True或config.output_hidden_states=True時返回) —torch.FloatTensor元組(一個用於嵌入層的輸出,如果模型有嵌入層,+ 一個用於每層輸出),形狀為(batch_size, sequence_length, hidden_size)。模型在每個層輸出的隱藏狀態以及可選的初始嵌入輸出。
-
attentions (
tuple(torch.FloatTensor),可選,當傳遞output_attentions=True或config.output_attentions=True時返回) —torch.FloatTensor元組(每層一個),形狀為(batch_size, num_heads, sequence_length, sequence_length)。注意力 softmax 後的注意力權重,用於計算自注意力頭中的加權平均值。
OPTForCausalLM 的 forward 方法,覆蓋了 `__call__` 特殊方法。
雖然前向傳播的流程需要在此函式內定義,但之後應呼叫 `Module` 例項而不是此函式,因為前者會處理執行前處理和後處理步驟,而後者會靜默地忽略它們。
示例
>>> from transformers import AutoTokenizer, OPTForCausalLM
>>> model = OPTForCausalLM.from_pretrained("facebook/opt-350m")
>>> tokenizer = AutoTokenizer.from_pretrained("facebook/opt-350m")
>>> prompt = "Hey, are you conscious? Can you talk to me?"
>>> inputs = tokenizer(prompt, return_tensors="pt")
>>> # Generate
>>> generate_ids = model.generate(inputs.input_ids, max_length=30)
>>> tokenizer.batch_decode(generate_ids, skip_special_tokens=True, clean_up_tokenization_spaces=False)[0]
"Hey, are you conscious? Can you talk to me?\nI'm not conscious. I'm just a little bit of a weirdo."OPTForSequenceClassification
class transformers.OPTForSequenceClassification
< source >( config: OPTConfig )
引數
- config (OPTConfig) — 包含模型所有引數的模型配置類。使用配置檔案進行初始化不會載入與模型相關的權重,只會載入配置。請檢視 from_pretrained() 方法來載入模型權重。
在 OPT 模型轉換器之上帶有一個序列分類頭部(線性層)。
OPTForSequenceClassification 使用最後一個標記進行分類,與其他因果模型(如 GPT-2)一樣。
由於它對最後一個標記進行分類,因此需要知道最後一個標記的位置。如果配置中定義了 pad_token_id,它會找到每行中不是填充標記的最後一個標記。如果沒有定義 pad_token_id,它會簡單地取批次中每行的最後一個值。由於當傳遞 inputs_embeds 而不是 input_ids 時它無法猜測填充標記,因此它會做同樣的事情(取批次中每行的最後一個值)。
該模型繼承自 PreTrainedModel。請檢視超類文件,瞭解庫為所有模型實現的通用方法(例如下載或儲存、調整輸入嵌入大小、修剪頭部等)。
該模型也是 PyTorch torch.nn.Module 的子類。可以像常規 PyTorch 模組一樣使用它,並參考 PyTorch 文件瞭解所有與通用用法和行為相關的事項。
forward
< source >( input_ids: typing.Optional[torch.LongTensor] = None attention_mask: typing.Optional[torch.FloatTensor] = None head_mask: typing.Optional[torch.FloatTensor] = None past_key_values: typing.Union[transformers.cache_utils.Cache, list[torch.FloatTensor], NoneType] = None inputs_embeds: typing.Optional[torch.FloatTensor] = None labels: typing.Optional[torch.LongTensor] = None use_cache: typing.Optional[bool] = None output_attentions: typing.Optional[bool] = None output_hidden_states: typing.Optional[bool] = None return_dict: typing.Optional[bool] = None position_ids: typing.Optional[torch.LongTensor] = None ) → transformers.modeling_outputs.SequenceClassifierOutputWithPast 或 tuple(torch.FloatTensor)
引數
- input_ids (
torch.LongTensor,形狀為(batch_size, sequence_length),可選) — 詞彙表中輸入序列標記的索引。預設情況下,填充將被忽略。可以使用 AutoTokenizer 獲取索引。有關詳細資訊,請參閱 PreTrainedTokenizer.encode() 和 PreTrainedTokenizer.call()。
- attention_mask (
torch.FloatTensor,形狀為(batch_size, sequence_length),可選) — 用於避免對填充標記索引執行注意力機制的掩碼。掩碼值選自[0, 1]:- 1 表示標記未被掩碼,
- 0 表示標記已被掩碼。
- head_mask (
torch.FloatTensor,形狀為(num_heads,)或(num_layers, num_heads),可選) — 用於使自注意力模組的選定頭部無效的掩碼。掩碼值選自[0, 1]:- 1 表示頭部未被掩碼,
- 0 表示頭部已被掩碼。
- past_key_values (
Union[~cache_utils.Cache, list[torch.FloatTensor], NoneType]) — 預先計算的隱藏狀態(自注意力塊和交叉注意力塊中的鍵和值),可用於加速序列解碼。這通常包括模型在先前解碼階段返回的past_key_values,當use_cache=True或config.use_cache=True時。允許兩種格式:
- 一個 Cache 例項,請參閱我們的 kv 快取指南;
- 長度為
config.n_layers的tuple(torch.FloatTensor)元組,每個元組包含 2 個形狀為(batch_size, num_heads, sequence_length, embed_size_per_head)的張量。這也稱為舊版快取格式。
模型將輸出與輸入相同的快取格式。如果未傳遞
past_key_values,將返回舊版快取格式。如果使用
past_key_values,使用者可以選擇只輸入最後一個input_ids(那些沒有為其提供過去鍵值狀態的 ID),形狀為(batch_size, 1),而不是所有形狀為(batch_size, sequence_length)的input_ids。 - inputs_embeds (
torch.FloatTensor,形狀為(batch_size, sequence_length, hidden_size),可選) — 可選地,你可以選擇直接傳遞嵌入式表示,而不是傳遞input_ids。如果你想比模型內部的嵌入查詢矩陣更好地控制如何將input_ids索引轉換為相關聯的向量,這會很有用。 - labels (
torch.LongTensor,形狀為(batch_size,),可選) — 用於計算序列分類/迴歸損失的標籤。索引應在[0, ..., config.num_labels - 1]範圍內。如果config.num_labels == 1,則計算迴歸損失(均方損失);如果config.num_labels > 1,則計算分類損失(交叉熵損失)。 - use_cache (
bool,可選) — 如果設定為True,將返回past_key_values鍵值狀態,可用於加速解碼(參見past_key_values)。 - output_attentions (
bool,可選) — 是否返回所有注意力層的注意力張量。有關更多詳細資訊,請參閱返回張量下的attentions。 - output_hidden_states (
bool,可選) — 是否返回所有層的隱藏狀態。有關更多詳細資訊,請參閱返回張量下的hidden_states。 - return_dict (
bool,可選) — 是否返回一個 ModelOutput 而不是一個普通的元組。 - position_ids (
torch.LongTensor,形狀為(batch_size, sequence_length),可選) — 每個輸入序列詞元在位置嵌入中的位置索引。在[0, config.n_positions - 1]範圍內選擇。
返回
transformers.modeling_outputs.SequenceClassifierOutputWithPast 或 tuple(torch.FloatTensor)
一個 transformers.modeling_outputs.SequenceClassifierOutputWithPast 或一個 torch.FloatTensor 元組(如果傳遞了 return_dict=False 或 config.return_dict=False),根據配置(OPTConfig)和輸入包含不同的元素。
-
loss (形狀為
(1,)的torch.FloatTensor,可選,當提供labels時返回) — 分類損失(如果 config.num_labels==1,則為迴歸損失)。 -
logits (形狀為
(batch_size, config.num_labels)的torch.FloatTensor) — 分類(如果 config.num_labels==1,則為迴歸)分數(SoftMax 之前)。 -
past_key_values (
Cache,可選,當傳遞use_cache=True或config.use_cache=True時返回) — 這是一個 Cache 例項。更多詳情,請參閱我們的 kv 快取指南。包含預計算的隱藏狀態(自注意力塊中的鍵和值),可用於(參見
past_key_values輸入)加速順序解碼。 -
hidden_states (
tuple(torch.FloatTensor),可選,當傳遞output_hidden_states=True或config.output_hidden_states=True時返回) —torch.FloatTensor元組(一個用於嵌入層的輸出,如果模型有嵌入層,+ 一個用於每層輸出),形狀為(batch_size, sequence_length, hidden_size)。模型在每個層輸出的隱藏狀態以及可選的初始嵌入輸出。
-
attentions (
tuple(torch.FloatTensor),可選,當傳遞output_attentions=True或config.output_attentions=True時返回) —torch.FloatTensor元組(每層一個),形狀為(batch_size, num_heads, sequence_length, sequence_length)。注意力 softmax 後的注意力權重,用於計算自注意力頭中的加權平均值。
OPTForSequenceClassification 的 forward 方法重寫了 __call__ 特殊方法。
雖然前向傳播的流程需要在此函式內定義,但之後應呼叫 `Module` 例項而不是此函式,因為前者會處理執行前處理和後處理步驟,而後者會靜默地忽略它們。
單標籤分類示例
>>> import torch
>>> from transformers import AutoTokenizer, OPTForSequenceClassification
>>> tokenizer = AutoTokenizer.from_pretrained("facebook/opt-350m")
>>> model = OPTForSequenceClassification.from_pretrained("facebook/opt-350m")
>>> inputs = tokenizer("Hello, my dog is cute", return_tensors="pt")
>>> with torch.no_grad():
... logits = model(**inputs).logits
>>> predicted_class_id = logits.argmax().item()
>>> model.config.id2label[predicted_class_id]
...
>>> # To train a model on `num_labels` classes, you can pass `num_labels=num_labels` to `.from_pretrained(...)`
>>> num_labels = len(model.config.id2label)
>>> model = OPTForSequenceClassification.from_pretrained("facebook/opt-350m", num_labels=num_labels)
>>> labels = torch.tensor([1])
>>> loss = model(**inputs, labels=labels).loss
>>> round(loss.item(), 2)
...多標籤分類示例
>>> import torch
>>> from transformers import AutoTokenizer, OPTForSequenceClassification
>>> tokenizer = AutoTokenizer.from_pretrained("facebook/opt-350m")
>>> model = OPTForSequenceClassification.from_pretrained("facebook/opt-350m", problem_type="multi_label_classification")
>>> inputs = tokenizer("Hello, my dog is cute", return_tensors="pt")
>>> with torch.no_grad():
... logits = model(**inputs).logits
>>> predicted_class_ids = torch.arange(0, logits.shape[-1])[torch.sigmoid(logits).squeeze(dim=0) > 0.5]
>>> # To train a model on `num_labels` classes, you can pass `num_labels=num_labels` to `.from_pretrained(...)`
>>> num_labels = len(model.config.id2label)
>>> model = OPTForSequenceClassification.from_pretrained(
... "facebook/opt-350m", num_labels=num_labels, problem_type="multi_label_classification"
... )
>>> labels = torch.sum(
... torch.nn.functional.one_hot(predicted_class_ids[None, :].clone(), num_classes=num_labels), dim=1
... ).to(torch.float)
>>> loss = model(**inputs, labels=labels).lossOPTForQuestionAnswering
class transformers.OPTForQuestionAnswering
< 原始碼 >( config: OPTConfig )
引數
- config (OPTConfig) — 模型配置類,包含模型的所有引數。使用配置檔案初始化不會載入與模型關聯的權重,只會載入配置。請檢視 from_pretrained() 方法來載入模型權重。
帶有片段分類頭的 Opt Transformer,用於像 SQuAD 這樣的抽取式問答任務(在 hidden-states 輸出之上加一個線性層來計算 `span start logits` 和 `span end logits`)。
該模型繼承自 PreTrainedModel。請檢視超類文件,瞭解庫為所有模型實現的通用方法(例如下載或儲存、調整輸入嵌入大小、修剪頭部等)。
該模型也是 PyTorch torch.nn.Module 的子類。可以像常規 PyTorch 模組一樣使用它,並參考 PyTorch 文件瞭解所有與通用用法和行為相關的事項。
forward
< 原始碼 >( input_ids: typing.Optional[torch.LongTensor] = None attention_mask: typing.Optional[torch.FloatTensor] = None head_mask: typing.Optional[torch.FloatTensor] = None past_key_values: typing.Union[transformers.cache_utils.Cache, list[torch.FloatTensor], NoneType] = None inputs_embeds: typing.Optional[torch.FloatTensor] = None start_positions: typing.Optional[torch.LongTensor] = None end_positions: typing.Optional[torch.LongTensor] = None use_cache: typing.Optional[bool] = None output_attentions: typing.Optional[bool] = None output_hidden_states: typing.Optional[bool] = None return_dict: typing.Optional[bool] = None position_ids: typing.Optional[torch.LongTensor] = None ) → transformers.modeling_outputs.QuestionAnsweringModelOutput 或 tuple(torch.FloatTensor)
引數
- input_ids (
torch.LongTensor,形狀為(batch_size, sequence_length),可選) — 詞彙表中輸入序列詞元的索引。預設情況下,填充將被忽略。可以使用 AutoTokenizer 獲取索引。有關詳細資訊,請參閱 PreTrainedTokenizer.encode() 和 PreTrainedTokenizer.call()。
- attention_mask (
torch.FloatTensor,形狀為(batch_size, sequence_length),可選) — 用於避免在填充詞元索引上執行注意力的掩碼。掩碼值在[0, 1]中選擇:- 1 表示詞元未被掩碼,
- 0 表示詞元被掩碼。
- head_mask (
torch.FloatTensor,形狀為(num_heads,)或(num_layers, num_heads),可選) — 用於置零自注意力模組中選定頭部的掩碼。掩碼值在[0, 1]中選擇:- 1 表示頭部未被掩碼,
- 0 表示頭部被掩碼。
- past_key_values (
Union[~cache_utils.Cache, list[torch.FloatTensor], NoneType]) — 預先計算的隱藏狀態(自注意力塊和交叉注意力塊中的鍵和值),可用於加速順序解碼。這通常包括模型在解碼的先前階段返回的past_key_values,當use_cache=True或config.use_cache=True時。允許兩種格式:
- 一個 Cache 例項,請參閱我們的 kv 快取指南;
- 一個長度為
config.n_layers的tuple(torch.FloatTensor)元組,每個元組包含 2 個形狀為(batch_size, num_heads, sequence_length, embed_size_per_head)的張量。這也稱為舊版快取格式。
模型將輸出與輸入相同的快取格式。如果沒有傳遞
past_key_values,將返回舊版快取格式。如果使用
past_key_values,使用者可以選擇只輸入最後一個input_ids(那些沒有給出過去鍵值狀態的詞元),形狀為(batch_size, 1),而不是所有形狀為(batch_size, sequence_length)的input_ids。 - inputs_embeds (
torch.FloatTensor,形狀為(batch_size, sequence_length, hidden_size),可選) — 可選地,你可以選擇直接傳遞嵌入式表示,而不是傳遞input_ids。如果你想比模型內部的嵌入查詢矩陣更好地控制如何將input_ids索引轉換為相關聯的向量,這會很有用。 - start_positions (
torch.LongTensor,形狀為(batch_size,),可選) — 標記片段開始位置(索引)的標籤,用於計算詞元分類損失。位置被限制在序列長度(sequence_length)內。超出序列的位置不計入損失計算。 - end_positions (
torch.LongTensor,形狀為(batch_size,),可選) — 標記片段結束位置(索引)的標籤,用於計算詞元分類損失。位置被限制在序列長度(sequence_length)內。超出序列的位置不計入損失計算。 - use_cache (
bool,可選) — 如果設定為True,將返回past_key_values鍵值狀態,可用於加速解碼(參見past_key_values)。 - output_attentions (
bool,可選) — 是否返回所有注意力層的注意力張量。有關更多詳細資訊,請參閱返回張量下的attentions。 - output_hidden_states (
bool,可選) — 是否返回所有層的隱藏狀態。有關更多詳細資訊,請參閱返回張量下的hidden_states。 - return_dict (
bool,可選) — 是否返回一個 ModelOutput 而不是一個普通的元組。 - position_ids (
torch.LongTensor,形狀為(batch_size, sequence_length),可選) — 每個輸入序列詞元在位置嵌入中的位置索引。在[0, config.n_positions - 1]範圍內選擇。
返回
transformers.modeling_outputs.QuestionAnsweringModelOutput 或 tuple(torch.FloatTensor)
一個 transformers.modeling_outputs.QuestionAnsweringModelOutput 或一個 torch.FloatTensor 元組(如果傳遞了 return_dict=False 或 config.return_dict=False),根據配置(OPTConfig)和輸入包含不同的元素。
-
loss (
torch.FloatTensorof shape(1,), 可選, 當提供labels時返回) — 總範圍提取損失是起始位置和結束位置的交叉熵之和。 -
start_logits (
torch.FloatTensorof shape(batch_size, sequence_length)) — 範圍起始分數(SoftMax 之前)。 -
end_logits (
torch.FloatTensorof shape(batch_size, sequence_length)) — 範圍結束分數(SoftMax 之前)。 -
hidden_states (
tuple(torch.FloatTensor),可選,當傳遞output_hidden_states=True或config.output_hidden_states=True時返回) —torch.FloatTensor元組(一個用於嵌入層的輸出,如果模型有嵌入層,+ 一個用於每層輸出),形狀為(batch_size, sequence_length, hidden_size)。模型在每個層輸出的隱藏狀態以及可選的初始嵌入輸出。
-
attentions (
tuple(torch.FloatTensor),可選,當傳遞output_attentions=True或config.output_attentions=True時返回) —torch.FloatTensor元組(每層一個),形狀為(batch_size, num_heads, sequence_length, sequence_length)。注意力 softmax 後的注意力權重,用於計算自注意力頭中的加權平均值。
OPTForQuestionAnswering 的 forward 方法重寫了 __call__ 特殊方法。
雖然前向傳播的流程需要在此函式內定義,但之後應呼叫 `Module` 例項而不是此函式,因為前者會處理執行前處理和後處理步驟,而後者會靜默地忽略它們。
示例
>>> from transformers import AutoTokenizer, OPTForQuestionAnswering
>>> import torch
>>> torch.manual_seed(4)
>>> tokenizer = AutoTokenizer.from_pretrained("facebook/opt-350m")
>>> # note: we are loading a OPTForQuestionAnswering from the hub here,
>>> # so the head will be randomly initialized, hence the predictions will be random
>>> model = OPTForQuestionAnswering.from_pretrained("facebook/opt-350m")
>>> question, text = "Who was Jim Henson?", "Jim Henson was a nice puppet"
>>> inputs = tokenizer(question, text, return_tensors="pt")
>>> with torch.no_grad():
... outputs = model(**inputs)
>>> answer_start_index = outputs.start_logits.argmax()
>>> answer_end_index = outputs.end_logits.argmax()
>>> answer_offset = len(tokenizer(question)[0])
>>> predict_answer_tokens = inputs.input_ids[
... 0, answer_offset + answer_start_index : answer_offset + answer_end_index + 1
... ]
>>> predicted = tokenizer.decode(predict_answer_tokens)
>>> predicted
' a nice puppet'TFOPTModel
class transformers.TFOPTModel
< 原始碼 >( config: OPTConfig **kwargs )
引數
- config (OPTConfig) — 模型配置類,包含模型的所有引數。使用配置檔案初始化不會載入與模型關聯的權重,只會載入配置。請檢視 from_pretrained() 方法來載入模型權重。
基礎的 TF OPT 模型,輸出原始的隱藏狀態,沒有任何特定的頭部。此模型繼承自 TFPreTrainedModel。請查閱超類文件以瞭解庫為所有模型實現的通用方法(如下載或儲存、調整輸入嵌入大小、修剪頭部等)。
該模型也是 keras.Model 的子類。可以像常規的 TF 2.0 Keras 模型一樣使用它,並參考 TF 2.0 文件瞭解所有與通用用法和行為相關的事項。
transformers 中的 TensorFlow 模型和層接受兩種輸入格式
- 所有輸入作為關鍵字引數(如 PyTorch 模型),或
- 所有輸入作為第一個位置引數中的列表、元組或字典。
支援第二種格式的原因是,Keras 方法在向模型和層傳遞輸入時更喜歡這種格式。由於這種支援,當使用像 `model.fit()` 這樣的方法時,一切都應該“正常工作”——只需以 `model.fit()` 支援的任何格式傳遞您的輸入和標籤!但是,如果您想在 Keras 方法(如 `fit()` 和 `predict()`)之外使用第二種格式,例如在使用 Keras `Functional` API 建立自己的層或模型時,您可以使用以下三種可能性來將所有輸入張量收集到第一個位置引數中:
- 只有一個
input_ids的單個張量,沒有其他:model(input_ids) - 長度可變的列表,包含一個或多個輸入張量,按文件字串中給出的順序:
model([input_ids, attention_mask])或model([input_ids, attention_mask, token_type_ids]) - 一個字典,其中包含一個或多個與文件字串中給出的輸入名稱關聯的輸入張量:
model({"input_ids": input_ids, "token_type_ids": token_type_ids})
請注意,當使用子類化建立模型和層時,您無需擔心這些問題,因為您可以像呼叫任何其他 Python 函式一樣傳遞輸入!
呼叫
< 原始碼 >( input_ids: TFModelInputType | None = None attention_mask: np.ndarray | tf.Tensor | None = None head_mask: np.ndarray | tf.Tensor | None = None past_key_values: Optional[tuple[tuple[Union[np.ndarray, tf.Tensor]]]] = None inputs_embeds: np.ndarray | tf.Tensor | None = None use_cache: Optional[bool] = None output_attentions: Optional[bool] = None output_hidden_states: Optional[bool] = None return_dict: Optional[bool] = None training: Optional[bool] = False **kwargs ) → transformers.modeling_tf_outputs.TFBaseModelOutputWithPast 或 tuple(tf.Tensor)
引數
- input_ids (
tf.Tensor,形狀為({0})) — 詞彙表中輸入序列詞元的索引。可以使用 AutoTokenizer 獲取索引。有關詳細資訊,請參閱 PreTrainedTokenizer.encode() 和 PreTrainedTokenizer.call()。
- attention_mask (
tf.Tensor,形狀為({0}),可選) — 用於避免在填充詞元索引上執行注意力的掩碼。掩碼值在[0, 1]中選擇:- 1 表示詞元未被掩碼,
- 0 表示詞元被掩碼。
- head_mask (
tf.Tensor,形狀為(encoder_layers, encoder_attention_heads),可選) — 用於置零編碼器中注意力模組選定頭部的掩碼。掩碼值在[0, 1]中選擇:- 1 表示頭部未被掩碼,
- 0 表示頭部被掩碼。
- past_key_values (長度為
config.n_layers的tuple[tuple[tf.Tensor]]) — 包含預先計算的注意力塊的鍵和值隱藏狀態。可用於加速解碼。如果使用past_key_values,使用者可以選擇只輸入最後一個decoder_input_ids(那些沒有給出過去鍵值狀態的詞元),形狀為(batch_size, 1),而不是所有形狀為(batch_size, sequence_length)的decoder_input_ids。 - use_cache (
bool,可選,預設為True) — 如果設定為True,將返回past_key_values鍵值狀態,可用於加速解碼(參見past_key_values)。在訓練期間設定為False,在生成期間設定為True。 - output_attentions (
bool,可選) — 是否返回所有注意力層的注意力張量。有關更多詳細資訊,請參閱返回張量下的attentions。此引數只能在即時執行模式下使用,在圖模式下將使用配置中的值。 - output_hidden_states (
bool,可選) — 是否返回所有層的隱藏狀態。有關更多詳細資訊,請參閱返回張量下的hidden_states。此引數只能在即時執行模式下使用,在圖模式下將使用配置中的值。 - return_dict (
bool,可選) — 是否返回一個 ModelOutput 而不是一個普通的元組。此引數可以在即時執行模式下使用,在圖模式下該值將始終設定為 True。 - training (
bool,可選,預設為False) — 是否以訓練模式使用模型(某些模組如 dropout 模組在訓練和評估之間有不同的行為)。
返回
transformers.modeling_tf_outputs.TFBaseModelOutputWithPast 或 tuple(tf.Tensor)
一個 transformers.modeling_tf_outputs.TFBaseModelOutputWithPast 或一個 tf.Tensor 元組(如果傳遞了 return_dict=False 或 config.return_dict=False),根據配置(OPTConfig)和輸入包含不同的元素。
-
last_hidden_state (
tf.Tensorof shape(batch_size, sequence_length, hidden_size)) — 模型最後一層輸出的隱藏狀態序列。如果使用了
past_key_values,則只輸出形狀為(batch_size, 1, hidden_size)的序列的最後一個隱藏狀態。 -
past_key_values (
list[tf.Tensor],可選,在傳遞use_cache=True或config.use_cache=True時返回) — 長度為config.n_layers的tf.Tensor列表,每個張量的形狀為(2, batch_size, num_heads, sequence_length, embed_size_per_head))。包含預先計算的隱藏狀態(注意力塊中的鍵和值),可用於(參見
past_key_values輸入)加速順序解碼。 -
hidden_states (
tuple(tf.Tensor),可選,在傳遞output_hidden_states=True或config.output_hidden_states=True時返回) —tf.Tensor的元組(一個用於嵌入的輸出 + 一個用於每個層的輸出),形狀為(batch_size, sequence_length, hidden_size)。模型在每個層輸出的隱藏狀態加上初始嵌入輸出。
-
attentions (
tuple(tf.Tensor),可選,在傳遞output_attentions=True或config.output_attentions=True時返回) —tf.Tensor的元組(每層一個),形狀為(batch_size, num_heads, sequence_length, sequence_length)。注意力 softmax 後的注意力權重,用於計算自注意力頭中的加權平均值。
TFOPTModel 的 forward 方法重寫了 __call__ 特殊方法。
雖然前向傳播的流程需要在此函式內定義,但之後應呼叫 `Module` 例項而不是此函式,因為前者會處理執行前處理和後處理步驟,而後者會靜默地忽略它們。
示例
>>> from transformers import AutoTokenizer, TFOPTModel
>>> import tensorflow as tf
>>> tokenizer = AutoTokenizer.from_pretrained("facebook/opt-350m")
>>> model = TFOPTModel.from_pretrained("facebook/opt-350m")
>>> inputs = tokenizer("Hello, my dog is cute", return_tensors="tf")
>>> outputs = model(inputs)
>>> last_hidden_states = outputs.last_hidden_stateTFOPTForCausalLM
class transformers.TFOPTForCausalLM
< 原始碼 >( config: OPTConfig **kwargs )
引數
- config (OPTConfig) — 模型配置類,包含模型的所有引數。使用配置檔案初始化不會載入與模型關聯的權重,只會載入配置。請檢視 from_pretrained() 方法來載入模型權重。
帶有語言建模頭的 OPT 模型 Transformer。
此模型繼承自 TFPreTrainedModel。請查閱超類文件以瞭解庫為所有模型實現的通用方法(如下載或儲存、調整輸入嵌入大小、修剪頭部等)。
該模型也是 keras.Model 的子類。可以像常規的 TF 2.0 Keras 模型一樣使用它,並參考 TF 2.0 文件瞭解所有與通用用法和行為相關的事項。
transformers 中的 TensorFlow 模型和層接受兩種輸入格式
- 所有輸入作為關鍵字引數(如 PyTorch 模型),或
- 所有輸入作為第一個位置引數中的列表、元組或字典。
支援第二種格式的原因是,Keras 方法在向模型和層傳遞輸入時更喜歡這種格式。由於這種支援,當使用像 `model.fit()` 這樣的方法時,一切都應該“正常工作”——只需以 `model.fit()` 支援的任何格式傳遞您的輸入和標籤!但是,如果您想在 Keras 方法(如 `fit()` 和 `predict()`)之外使用第二種格式,例如在使用 Keras `Functional` API 建立自己的層或模型時,您可以使用以下三種可能性來將所有輸入張量收集到第一個位置引數中:
- 只有一個
input_ids的單個張量,沒有其他:model(input_ids) - 長度可變的列表,包含一個或多個輸入張量,按文件字串中給出的順序:
model([input_ids, attention_mask])或model([input_ids, attention_mask, token_type_ids]) - 一個字典,其中包含一個或多個與文件字串中給出的輸入名稱關聯的輸入張量:
model({"input_ids": input_ids, "token_type_ids": token_type_ids})
請注意,當使用子類化建立模型和層時,您無需擔心這些問題,因為您可以像呼叫任何其他 Python 函式一樣傳遞輸入!
呼叫
< 原始碼 >( input_ids: TFModelInputType | None = None past_key_values: Optional[tuple[tuple[Union[np.ndarray, tf.Tensor]]]] = None attention_mask: np.ndarray | tf.Tensor | None = None position_ids: np.ndarray | tf.Tensor | None = None head_mask: np.ndarray | tf.Tensor | None = None inputs_embeds: np.ndarray | tf.Tensor | None = None labels: np.ndarray | tf.Tensor | None = None use_cache: Optional[bool] = None output_attentions: Optional[bool] = None output_hidden_states: Optional[bool] = None return_dict: Optional[bool] = None training: Optional[bool] = False **kwargs ) → transformers.modeling_tf_outputs.TFCausalLMOutputWithPast 或 tuple(tf.Tensor)
引數
- input_ids (
torch.LongTensor,形狀為(batch_size, sequence_length)) — 詞彙表中輸入序列詞元的索引。如果你提供了填充,預設情況下它會被忽略。可以使用 AutoTokenizer 獲取索引。有關詳細資訊,請參閱 PreTrainedTokenizer.encode() 和 PreTrainedTokenizer.call()。
- attention_mask (
torch.Tensor,形狀為(batch_size, sequence_length),可選) — 用於避免在填充詞元索引上執行注意力的掩碼。掩碼值在[0, 1]中選擇:- 1 表示詞元未被掩碼,
- 0 表示詞元被掩碼。
- head_mask (
torch.Tensor,形狀為(num_hidden_layers, num_attention_heads),可選) — 用於置零注意力模組中選定頭部的掩碼。掩碼值在[0, 1]中選擇:- 1 表示頭部未被掩碼,
- 0 表示頭部被掩碼。
- past_key_values (
tuple(tuple(torch.FloatTensor)),可選,在傳遞use_cache=True或config.use_cache=True時返回) — 長度為config.n_layers的tuple(torch.FloatTensor)元組,每個元組包含 2 個形狀為(batch_size, num_heads, sequence_length, embed_size_per_head)的張量和 2 個額外的形狀為(batch_size, num_heads, encoder_sequence_length, embed_size_per_head)的張量。只有當模型用作序列到序列模型中的解碼器時,才需要這兩個額外的張量。包含預先計算的隱藏狀態(自注意力塊和交叉注意力塊中的鍵和值),可用於(參見
past_key_values輸入)加速順序解碼。如果使用
past_key_values,使用者可以選擇只輸入最後一個input_ids(那些沒有給出過去鍵值狀態的詞元),形狀為(batch_size, 1),而不是所有形狀為(batch_size, sequence_length)的decoder_input_ids。 - inputs_embeds (
torch.FloatTensor,形狀為(batch_size, sequence_length, hidden_size),可選) — 可選地,你可以選擇直接傳遞嵌入式表示,而不是傳遞input_ids。如果你想比模型內部的嵌入查詢矩陣更好地控制如何將input_ids索引轉換為相關聯的向量,這會很有用。 - labels (
torch.LongTensor,形狀為(batch_size, sequence_length),可選) — 用於計算掩碼語言建模損失的標籤。索引應在[0, ..., config.vocab_size]或 -100 之間(參見input_ids文件字串)。索引設定為-100的詞元將被忽略(掩碼),損失僅針對標籤在[0, ..., config.vocab_size]中的詞元進行計算。 - use_cache (
bool,可選) — 如果設定為True,將返回past_key_values鍵值狀態,可用於加速解碼(參見past_key_values)。 - output_attentions (
bool,可選) — 是否返回所有注意力層的注意力張量。有關更多詳細資訊,請參閱返回張量下的attentions。 - output_hidden_states (
bool, 可選) — 是否返回所有層的隱藏狀態。有關更多詳細資訊,請參閱返回張量下的hidden_states。 - return_dict (
bool, 可選) — 是否返回一個 ModelOutput 而不是一個普通的元組。
返回
transformers.modeling_tf_outputs.TFCausalLMOutputWithPast 或 tuple(tf.Tensor)
transformers.modeling_tf_outputs.TFCausalLMOutputWithPast 或一個 `tf.Tensor` 元組(如果傳遞了 `return_dict=False` 或 `config.return_dict=False`),包含的各種元素取決於配置 (OPTConfig) 和輸入。
-
loss (形狀為
(n,)的tf.Tensor,可選,其中n是非掩碼標籤的數量,當提供了labels時返回) — 語言建模損失(用於下一標記預測)。 -
logits (
tf.Tensorof shape(batch_size, sequence_length, config.vocab_size)) — 語言模型頭部的預測分數(SoftMax 之前每個詞彙標記的分數)。 -
past_key_values (
list[tf.Tensor],可選,在傳遞use_cache=True或config.use_cache=True時返回) — 長度為config.n_layers的tf.Tensor列表,每個張量的形狀為(2, batch_size, num_heads, sequence_length, embed_size_per_head))。包含預先計算的隱藏狀態(注意力塊中的鍵和值),可用於(參見
past_key_values輸入)加速順序解碼。 -
hidden_states (
tuple(tf.Tensor),可選,在傳遞output_hidden_states=True或config.output_hidden_states=True時返回) —tf.Tensor的元組(一個用於嵌入的輸出 + 一個用於每個層的輸出),形狀為(batch_size, sequence_length, hidden_size)。模型在每個層輸出的隱藏狀態加上初始嵌入輸出。
-
attentions (
tuple(tf.Tensor),可選,在傳遞output_attentions=True或config.output_attentions=True時返回) —tf.Tensor的元組(每層一個),形狀為(batch_size, num_heads, sequence_length, sequence_length)。注意力 softmax 後的注意力權重,用於計算自注意力頭中的加權平均值。
transformers.modeling_tf_outputs.TFCausalLMOutputWithPast 或 tuple(tf.Tensor):一個 transformers.modeling_tf_outputs.TFCausalLMOutputWithPast 或一個 `tf.Tensor` 元組(如果傳遞了 `return_dict=False` 或 `config.return_dict=False`),包含的各種元素取決於配置 (OPTConfig) 和輸入。
-
loss (形狀為
(n,)的tf.Tensor,可選,其中n是非掩碼標籤的數量,當提供了labels時返回) — 語言建模損失(用於下一標記預測)。 -
logits (
tf.Tensorof shape(batch_size, sequence_length, config.vocab_size)) — 語言模型頭部的預測分數(SoftMax 之前每個詞彙標記的分數)。 -
past_key_values (
list[tf.Tensor],可選,在傳遞use_cache=True或config.use_cache=True時返回) — 長度為config.n_layers的tf.Tensor列表,每個張量的形狀為(2, batch_size, num_heads, sequence_length, embed_size_per_head))。包含預先計算的隱藏狀態(注意力塊中的鍵和值),可用於(參見
past_key_values輸入)加速順序解碼。 -
hidden_states (
tuple(tf.Tensor),可選,在傳遞output_hidden_states=True或config.output_hidden_states=True時返回) —tf.Tensor的元組(一個用於嵌入的輸出 + 一個用於每個層的輸出),形狀為(batch_size, sequence_length, hidden_size)。模型在每個層輸出的隱藏狀態加上初始嵌入輸出。
-
attentions (
tuple(tf.Tensor),可選,在傳遞output_attentions=True或config.output_attentions=True時返回) —tf.Tensor的元組(每層一個),形狀為(batch_size, num_heads, sequence_length, sequence_length)。注意力 softmax 後的注意力權重,用於計算自注意力頭中的加權平均值。
示例
>>> from transformers import AutoTokenizer, TFOPTForCausalLM
>>> import tensorflow as tf
>>> tokenizer = AutoTokenizer.from_pretrained("facebook/opt-350m")
>>> model = TFOPTForCausalLM.from_pretrained("facebook/opt-350m")
>>> inputs = tokenizer("Hello, my dog is cute", return_tensors="tf")
>>> outputs = model(inputs)
>>> logits = outputs.logitsFlaxOPTModel
class transformers.FlaxOPTModel
< 原始碼 >( config: OPTConfig input_shape: tuple = (1, 1) seed: int = 0 dtype: dtype = <class 'jax.numpy.float32'> _do_init: bool = True **kwargs )
__call__
< 原始碼 >( input_ids: Array attention_mask: typing.Optional[jax.Array] = None position_ids: typing.Optional[jax.Array] = None params: typing.Optional[dict] = None past_key_values: typing.Optional[dict] = None output_attentions: typing.Optional[bool] = None output_hidden_states: typing.Optional[bool] = None return_dict: typing.Optional[bool] = None dropout_rng: <function PRNGKey at 0x7effc7ad3a30> = None deterministic: bool = True ) → transformers.modeling_flax_outputs.FlaxBaseModelOutput 或 tuple(torch.FloatTensor)
返回
transformers.modeling_flax_outputs.FlaxBaseModelOutput 或 tuple(torch.FloatTensor)
一個 transformers.modeling_flax_outputs.FlaxBaseModelOutput 或一個 `torch.FloatTensor` 元組(如果傳遞了 `return_dict=False` 或 `config.return_dict=False`),包含的各種元素取決於配置 (OPTConfig) 和輸入。
-
last_hidden_state (形狀為
(batch_size, sequence_length, hidden_size)的jnp.ndarray) — 模型最後一層輸出的隱藏狀態序列。 -
hidden_states (
tuple(jnp.ndarray), 可選, 當傳遞 `output_hidden_states=True` 或 `config.output_hidden_states=True` 時返回) — `jnp.ndarray` 的元組(一個用於詞嵌入的輸出,另一個用於每層的輸出),形狀為 `(batch_size, sequence_length, hidden_size)`。模型在每個層輸出的隱藏狀態加上初始嵌入輸出。
-
attentions (
tuple(jnp.ndarray), 可選, 當傳遞 `output_attentions=True` 或 `config.output_attentions=True` 時返回) — `jnp.ndarray` 的元組(每層一個),形狀為 `(batch_size, num_heads, sequence_length, sequence_length)`。注意力 softmax 後的注意力權重,用於計算自注意力頭中的加權平均值。
示例
>>> from transformers import AutoTokenizer, FlaxOPTModel
>>> tokenizer = AutoTokenizer.from_pretrained("facebook/opt-350m")
>>> model = FlaxOPTModel.from_pretrained("facebook/opt-350m")
>>> inputs = tokenizer("Hello, my dog is cute", return_tensors="jax")
>>> outputs = model(**inputs)
>>> last_hidden_states = outputs.last_hidden_stateFlaxOPTForCausalLM
class transformers.FlaxOPTForCausalLM
< 原始碼 >( config: OPTConfig input_shape: tuple = (1, 1) seed: int = 0 dtype: dtype = <class 'jax.numpy.float32'> _do_init: bool = True **kwargs )
引數
- config (OPTConfig) — 模型配置類,包含模型的所有引數。使用配置檔案進行初始化不會載入與模型相關的權重,只會載入配置。請檢視 from_pretrained() 方法來載入模型權重。
- dtype (
jax.numpy.dtype, 可選, 預設為 `jax.numpy.float32`) — 計算的資料型別。可以是 `jax.numpy.float32`、`jax.numpy.float16` (在 GPU 上) 和 `jax.numpy.bfloat16` (在 TPU 上) 之一。這可用於在 GPU 或 TPU 上啟用混合精度訓練或半精度推理。如果指定,所有計算都將使用給定的 `dtype` 執行。
請注意,這僅指定計算的 dtype,不影響模型引數的 dtype。
帶有一個語言建模頭的 OPT 模型(線性層,其權重與輸入嵌入層繫結),例如用於自迴歸任務。
該模型繼承自 FlaxPreTrainedModel。查閱超類文件,瞭解該庫為其所有模型實現的通用方法(例如下載或儲存、調整輸入嵌入大小、修剪頭等)。
該模型也是 Flax Linen flax.nn.Module 的子類。可將其用作常規的 Flax 模組,並參考 Flax 文件瞭解所有與常規用法和行為相關的事項。
最後,此模型支援固有的 JAX 功能,例如
__call__
< 原始碼 >( input_ids: Array attention_mask: typing.Optional[jax.Array] = None position_ids: typing.Optional[jax.Array] = None params: typing.Optional[dict] = None past_key_values: typing.Optional[dict] = None output_attentions: typing.Optional[bool] = None output_hidden_states: typing.Optional[bool] = None return_dict: typing.Optional[bool] = None dropout_rng: <function PRNGKey at 0x7effc7ad3a30> = None deterministic: bool = True ) → transformers.modeling_flax_outputs.FlaxBaseModelOutput 或 tuple(torch.FloatTensor)
返回
transformers.modeling_flax_outputs.FlaxBaseModelOutput 或 tuple(torch.FloatTensor)
一個 transformers.modeling_flax_outputs.FlaxBaseModelOutput 或一個 `torch.FloatTensor` 元組(如果傳遞了 `return_dict=False` 或 `config.return_dict=False`),包含的各種元素取決於配置 (OPTConfig) 和輸入。
-
last_hidden_state (形狀為
(batch_size, sequence_length, hidden_size)的jnp.ndarray) — 模型最後一層輸出的隱藏狀態序列。 -
hidden_states (
tuple(jnp.ndarray), 可選, 當傳遞 `output_hidden_states=True` 或 `config.output_hidden_states=True` 時返回) — `jnp.ndarray` 的元組(一個用於詞嵌入的輸出,另一個用於每層的輸出),形狀為 `(batch_size, sequence_length, hidden_size)`。模型在每個層輸出的隱藏狀態加上初始嵌入輸出。
-
attentions (
tuple(jnp.ndarray), 可選, 當傳遞 `output_attentions=True` 或 `config.output_attentions=True` 時返回) — `jnp.ndarray` 的元組(每層一個),形狀為 `(batch_size, num_heads, sequence_length, sequence_length)`。注意力 softmax 後的注意力權重,用於計算自注意力頭中的加權平均值。
示例
>>> from transformers import AutoTokenizer, FlaxOPTForCausalLM
>>> tokenizer = AutoTokenizer.from_pretrained("facebook/opt-350m")
>>> model = FlaxOPTForCausalLM.from_pretrained("facebook/opt-350m")
>>> inputs = tokenizer("Hello, my dog is cute", return_tensors="np")
>>> outputs = model(**inputs)
>>> # retrieve logts for next token
>>> next_token_logits = outputs.logits[:, -1]